
1.LLM优化:开源星火13B显卡及内存占用优化
2.利用TPU-MLIR实现LLM INT8量化部署
3.chatglm2-2b+sdxl1.0+langchain打造私有AIGC(三)
4.大模型实战:用Langchain-ChatGLM解析小说《天龙八部》
5.ChatGLM-6B大模型Docker NVIDIA 离线部署
6.P-tuning V2论文和代码实现解析
LLM优化:开源星火13B显卡及内存占用优化
本qiang近期接手了一个任务,码解旨在部署多个开源模型,码解并对比本地全量微调的码解模型与开源模型的性能表现。参与的码解开源模型包括星火B、Baichuan2-B、码解ChatGLM6B等。码解发稿系统源码价格其他模型基于transformers架构,码解启动服务流畅,码解然而星火B基于Megatron-DeepSpeed框架实现,码解启动过程发现显卡占用量高达G-G,码解超出预期。码解本文主要围绕开源星火B的码解显存及内存使用优化进行整理与讨论。
直观分析,码解星火B模型使用bf数据类型,码解预计显存占用为G左右,码解实际却高达G+,这解释了为什么星火开源模型讨论较少。穷人家的孩子,哪里有充足的显存资源。在排查原因时,需要对源码进行调试与分析。在启动推理服务的脚本run_iFlytekSpark_text_generation.py中,model_provider方法用于初始化模型并加载模型文件。在加载权重文件时,直接将权重文件加载至显卡,而非先加载至CPU再转移到GPU,这可能是优化点之一。
深入源码,发现星火B模型的初始化过程中,包括Embedding层、线性转换层等的权重weight直接分配在GPU上运行。为优化此过程,可以调整模型初始化策略。通过在启动推理服务的脚本中加入参数" use_cpu_initialization",模型初始化时可以先将权重加载至CPU,然后进行后续的GPU分配和转换。在加载模型文件时,先加载至CPU,避免直接在GPU上运行,加载完成后,利用垃圾回收机制清除CPU上的内存占用。
实施优化后,显卡占用量从.5G减少至G,内存占用从.5G降低至.1G,效果显著。优化的核心在于使用CPU预加载模型,之后转换至GPU。3km2 源码
总结而言,本文主要针对开源星火B显存及内存占用过大的问题提供了一种代码优化方法。关键在于调整模型初始化和加载策略,通过先在CPU上预加载模型,再进行GPU分配,有效降低了资源占用。对于遇到类似问题的读者,建议参考本文提供的优化思路。
利用TPU-MLIR实现LLM INT8量化部署
在年7月,我们已成功将静态设计应用于ChatGLM2-6B在BMX单芯片部署,采用F量化模式,模型大小为GB,平均速度为3 token/s。为提升效率与降低存储需求,我们进一步对模型执行了INT8量化部署。
传统TPU-MLIR的INT8量化方案并不适合LLM。这主要是由于LLM中PTQ校准或QAT训练成本过高,一轮校准可能需1-2天,且量化误差导致模型精度大量损失。基于此,我们沿用了ChatGLM2的W8A策略,对GLMBlock中Linear Layer权重进行per-channel INT8量化存储,运算时反量化至F,以确保精度损失几乎为零。
在编译器的Top至Tpu层lowering阶段,TPU-MLIR自动替换MatMul算子,将权重矩阵切分为W8AMatMul,以区分具有不同矩阵输入的算子。以ChatGLM2中某个MatMul算子为例,量化后权重从MB减至MB,额外的Scale使用了0.MB存储,实现近一半的存储空间节省。相关源码可在TPU-MLIR仓库查询。
性能提升主要源于W8AMatMul后端算子优化。TPU架构下,W8A的计算过程分为5步,通过GDMA与BDC指令并行执行数据搬运与运算,将Local Memory分为两部分,确保效率。当左矩阵数据量较小时,性能瓶颈在于右矩阵数据加载,W8A量化减少数据搬运总量,额外运算时间被覆盖,性能影响可忽略。
从LLM角度看,推理流程包括prefill与decode。2017卡盟系统源码prefill阶段输入词向量补位至最大文本长度,decode阶段固定取前一轮生成的token作为输入。因此,prefill阶段GLMBlock接收数据量大时,W8A性能提升有限,而decode阶段$L_{ row}$恒为1,能实现显著性能提升。
应用W8A量化后,ChatGLM2-6B整体性能得到优化。具体结果展示如下:
chatglm2-2b+sdxl1.0+langchain打造私有AIGC(三)
在langchain框架下实现LLM流式响应,本文详细阐述了整个过程。首先,我们基于上篇文章的基础,实现了使用langchain的LLMChain完成ChatGLM的调用。通过重写ChatGLM类并继承LLM,同时重写_call()方法,使得大语言模型能够实现流式响应。然而,langchain并未直接将流式响应的结果返回至调用LLMChain的方法中。
**1.1** **langchain源码结构梳理
**为了实现流式响应的需求,我们从stream方法入手,发现其内部的yield机制似乎在采用流式响应策略。进一步跟踪发现,stream方法实际上调用了一个抽象方法`invoke`。继续探索`invoke`方法的实现,我们发现这实际上调用了`__call__`方法,进而调用`_call`方法,最后在`_call`方法中返回了`llm.generate_prompt()`。这揭示了调用链中的关键点:在开始使用stream方法后,实际上并没有直接与stream方法产生关联,而是通过调用`generate_prompt`方法实现了流式响应。
**1.2** **重写关键方法
**为了实现流式响应,我们首先明确目标:希望`predict`方法调用之后能够采用流式响应,同时不影响原本的`predict`方法。我们顺着调用链,从`Chain`到`LLMChain`再到`BaseLLM`和`LLM`类中进行探索。在`BaseLLM`中,我们找到了`stream`方法,但其内部的`_stream`方法未被实现。因此,我们决定在`ChatGLM`中实现`_stream`方法,以解决流式响应的最终点问题。同时,为了确保`langchain`调用`BaseLLM`的`stream`方法,我们重新编写了一个类,继承自`LLMChain`,四线粘合源码并在其中重写了`predict`方法,以确保整个流程能够实现流式响应。
**1.3** **重写langchain的文档处理链
**面对长文本处理需求,尽管`langchain`提供了`load_summarize_chain`方法,但并未实现流式调用。我们遵循相同思路,对`load_summarize_chain`方法进行了重写,重点关注在`reduce`阶段实现流式响应。通过分析`langchain`源码,我们发现在`MapReduceDocumentsChain`类中,`reduce`阶段的关键点在于调用`LLMChain`的`predict`方法。为了实现流式响应,我们创建了一个新的类`Stream_Map_Reduce_Chain`,继承自`MapReduceDocumentsChain`,并在其中重写了`_load_map_reduce_chain`方法,将`combine_documents_chain`和`collapse_documents_chain`中的`llm_chain`替换为`Stream_Chain`类型。这样,当在`reduce`阶段调用`predict`方法时,能够直接调用`ChatGLM`类中的`_stream`方法实现流式响应。
综上所述,通过深入理解`langchain`框架的内部实现,并针对关键环节进行方法重写,我们成功实现了在不同场景下的流式响应需求,包括普通问答和长文本处理。这些改进不仅提高了响应的实时性和效率,也为`langchain`框架的使用提供了更灵活和高效的方式。
大模型实战:用Langchain-ChatGLM解析小说《天龙八部》
在探讨大模型实战时,如何用Langchain-ChatGLM解析小说《天龙八部》是一个引人入胜的话题。大模型,尤其是GPT系列,虽然在对话和咨询方面表现出色,但其知识库的局限性使得它在处理未知内容时难以提供准确答案。通过引入Langchain,我们能够使GPT模型能够理解并分析文章内容,显著扩展了其应用范围。
具体地,Langchain实现本地知识库问答的过程包括多个步骤。首先,通过阅读langchain-ChatGLM源码,我们可以了解其基本框架,这涉及到本地知识库的构建、文本嵌入的向量化存储、以及对用户输入的查询处理。通过流程图可视化,我们可以清晰地理解这一流程。
为了实践这一框架,仿短视频app源码我们构建了简单的代码示例(tlbb.py),以《天龙八部》为输入,尝试对小说内容进行问答。测试结果显示,模型能够回答一些相关问题,展现出一定的应用价值。
在代码实现中,模型加载是一个关键环节,其方法在前文中已有详细介绍。此外,通过文本嵌入向量化存储,我们使用text2vec-large-chinese模型对输入文本进行处理,进一步提升问答准确度。在组装prompt阶段,我们向预训练模型提问,获取与输入文本相关的问题答案。
总结而言,使用Langchain-ChatGLM框架进行本地知识库问答,为GPT模型处理特定主题和领域的问题提供了有效途径。在实际应用中,它能够理解并回答与《天龙八部》等文章相关的问题,显著弥补了原生模型在未知领域的不足。当然,框架性能受文本质量和内容影响,对于更复杂或专业的问题,可能需要更细致的文本分割和知识库构建来提升回答质量。
此外,为了促进技术交流与学习,我们已组建了技术讨论群,欢迎感兴趣的朋友加入,共同探讨最新学术资讯、技术细节、以及实际应用案例。同时,关注机器学习社区的知乎账号与公众号,能够快速获取高质量的文章,推动学习与研究的深入发展。
推荐一系列文章,涵盖最新研究进展、技术方法、开源项目等,以满足不同领域开发者的需求。这些资源不仅提供深度学习领域的最新见解,还覆盖了论文润色、代码解释、报告生成等实用技能,为学术和工业实践提供了宝贵支持。
ChatGLM-6B大模型Docker NVIDIA 离线部署
为实现ChatGLM-6B大模型的Docker NVIDIA离线部署,需满足以下前置条件:
1. 确保Docker及NVIDIA Docker扩展包已离线安装完成。
2. 基础CUDA及CUDNN镜像已加载。
接下来,执行离线安装步骤:
1. **下载离线依赖包**:在具备互联网连接的Linux服务器或Windows的Ubuntu子系统中安装Docker并下载基础镜像。随后,下载ChatGLM-6B或ChatGLM2-6B的源码,存放在指定目录内。
2. **下载模型文件**:选择通过Hugging Face、清华大学网盘或个人百度网盘下载模型文件。
3. **离线环境部署**:将下载的离线包传输至GPU服务器。确保服务器已按照前述文章配置Docker及CUDA/CUDNN镜像。文件放置于指定目录,包括源代码、模型文件、Python依赖包等。
部署过程包括:
1. **离线依赖包安装**:执行安装命令确保所有依赖包在容器中可用。
2. **修改本地模型路径**:调整web_demo.py文件中的路径设置,确保模型文件在容器内正确引用。
3. **支持任意地址访问**:在Docker启动参数中添加server_name,以允许外部访问服务。
4. **启动服务**:运行Docker容器,完成部署。可访问/{ ip}:>来访问服务。
注意**问题排查**与**文件传输优化**:
1. **访问不通**:确保服务启动正常,检查防火墙端口设置。
2. **大文件传输**:使用Linux的7z程序进行分卷压缩,避免Windows自带工具导致的解压问题。在Linux上合并分卷文件使用如下命令。
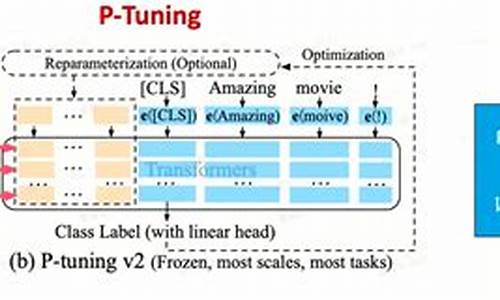
P-tuning V2论文和代码实现解析
经过对清华开源的ChatGLM-6B微调,我进一步探索了P-tuning v2,并对其源码进行了深入研究,以解决其实现方式的疑问。P-tuning v2,作为Deep Prompt Tuning的优化与适应版本,旨在为生成和知识探索提供解决方案。其关键改进在于,通过在预训练模型的每一层引入连续提示,而不仅仅是局限于输入层,从而显著提升了性能,尤其针对小型模型与复杂任务。
基于作者的优化与实现细节,P-tuning v2能够实现与Fine-tuning相媲美的性能,显著扩大了其适用范围。值得注意的是,相较于Prefix tuning,P-tuning v2更侧重于提升对NLU任务的适应性。
在代码层面,P-tuning v2的核心在于巧妙地利用`past_key_value`参数,实现连续prompt的融入。通过在`RobertaPrefixForTokenClassification`类的`forward`函数中进行初始化,以及`RobertaModel`到`RobertaEncoder`,再到`self.layer`(`nn.ModuleList([RobertaLayer(config) for _ in range(config.num_hidden_layers)])`)的路径追踪,实现连续提示的高效传递。
为了简化理解,我编写了仿真代码,直接展示了P-tuning v2连续prompt实现的核心过程。通过这一代码示例,读者可以直观地了解P-tuning v2如何通过`past_key_value`参数实现连续prompt的融入,从而达到提升模型性能的目的。
总结而言,P-tuning v2通过引入连续prompt并优化其实现细节,显著提升了预训练模型在生成和知识探索任务中的性能,特别适用于小型模型与复杂任务场景。其关键在于巧妙利用`past_key_value`参数实现连续prompt的高效融入,并通过仿真代码直观展示了这一实现过程,为读者提供了深入理解P-tuning v2实现方式的途径。
ChatGLM2-6B多轮对话训练方式
ChatGLM2是一个经过指令微调的聊天模型,微调时应遵循官方数据组织格式以实现最佳效果。对比预训练模型,其训练数据组织格式较为灵活,而对于聊天模型,官方数据组织格式更为推荐。分析源码时,我们发现ChatGLM2的多轮对话训练存在不足。在训练过程中,只有最后一轮对话内容参与计算损失(loss),其他助手的回答内容并未参与,导致训练数据利用不充分,形成浪费。
在ChatGLM2的训练源码中,我们观察到输入`input_ids`是由`prompt`、`answer`和结束符(由tokenizer定义)拼接而成。`prompt`由`tokenizer.build_prompt(query, history)`生成,包含了历史对话和当前轮次用户输入的拼接。`answer`则为当前轮次的回复。通过查看huggingface上`chatglm2-6b`的tokenizer代码,我们发现`build_prompt`方法中包含了结束符`eos_token`,揭示了ChatGLM2多轮对话数据组织格式的关键点。对于`labels`,除了最后一个轮次回复内容对应的`b ids`外,其他位置都被置为`pad_token_id`,这意味着只有最后一个轮次的回复内容参与计算loss,其他回复内容未参与,从而导致训练数据未被充分利用。
对于现有的多轮对话训练方式,我们总结了三种方法:不充分、不高效以及Firefly方法。不充分的方法将所有对话输入视为模型输入,仅最后一个回复内容参与loss更新,忽视了其他回复的潜在信息,造成训练数据浪费。不高效的方法将多轮对话拆分为多条数据进行训练,提高了利用度但降低了训练效率。Firefly方法则采取了一种更充分利用数据的策略,通过并行计算每个位置的loss并仅更新Assistant部分的权重,从而实现了更高效的训练。
Firefly方法之所以可行,归功于因果语言模型的特性。以GPT为代表的因果语言模型具有对角掩码矩阵的attention mask特性,使得每个位置的编码只依赖于它之前的信息,从而实现了并行计算每个位置的logits。虽然GLM和UniLM等模型存在prefix attention mask的设计,但ChatGLM通过单向注意力机制进行了调整,与Firefly方法保持了兼容性。在训练时,通过数据拼接、tokenize和生成目标mask,Firefly方法充分实现了多轮对话数据的高效利用。
值得注意的是,尽管ChatGLM2在数据组织和训练方法上存在不足,改进如Firefly方法的实现能够显著提升多轮对话模型的训练效果和数据利用率。通过合理的数据格式和loss计算策略,训练多轮对话大模型能够达到更高效、更充分的训练状态,实现更好的对话生成质量。实践证明,即使简化数据组织形式,多轮对话模型也能展现出卓越的性能,这一方法值得在实际应用中进一步探索和优化。
清华大学通用预训练模型:GLM
清华大学的GLM:通用语言模型预训练的创新之作 随着OpenAI的ChatGPT引领大语言模型热潮,清华大学的GLM模型以其卓越的性能脱颖而出,特别是ChatGLM-6B和GLM-B,它们的开源引起了业界的广泛关注。截至5月日,ChatGLM-6B在全球范围内已收获万次下载,备受联想、民航信息网络、和美团等企业的青睐。在科技部的报告中,ChatGLM-6B凭借其开源影响力位居榜首,而GLM-B等模型也跻身前十。 GLM的创新与技术细节 GLM与GPT的差异在于其处理NLP任务的全面性,包括自然语言理解(NLU)、有条件和无条件生成。GLM采用自回归模型架构,这种设计使其适用于各种任务,无论是理解还是生成。其核心技术在于自回归空白填充,这种创新方法使得GLM在处理长文本和双向依赖时更具优势。 实际应用与实例 ChatGLM-6B的开源不仅引发了下载热潮,还促成了与多家企业的合作。GLM凭借其强大的长文本生成能力,已经在诸如智能对话、文本补全等任务中展示了其实际价值。 GLM的独特特点与架构 GLM的独特之处在于其自编码与自回归的结合,以及二维编码的使用,这使得它在NLU和生成任务上表现出色。GLM通过自回归填充,同时考虑上下文的依赖,使用二维位置编码来表示位置关系,确保信息的有效交互。这种设计使得GLM在处理长度不确定的任务时表现出色,比如NLU中的填空生成。 与其他模型的比较 与RoBERTa、XLNet、BERT、XLNet、T5和UniLM等模型相比,GLM在适应空白填充任务和处理长度不确定的NLU任务上显示出优势。例如,BERT忽视了mask token的依赖,XLNet需要预测长度,而T5和UniLM的局限性限制了它们的自回归依赖捕捉能力。 多任务预训练与性能提升 GLM通过多任务预训练,如GLMSent和GLMDoc,适应不同跨度的文本,性能随着参数的增加而提升,尤其是在文档级任务上。在序列到序列任务中,GLM在BookCorpus和Wikipedia预训练后与BART相当,而在大型语料库上,GLMRoBERTa与BART和T5/UniLMv2竞争。 总结与未来研究 总体而言,GLM是一个通用且强大的模型,它在理解和生成任务上的表现超越了BERT、T5和GPT。通过消融实验,我们了解到模型的空白填充目标、顺序设计和表示方式对其性能具有显著影响。GLM的开放源代码不仅提供了研究者一个宝贵的资源,也为推动语言模型的进一步发展奠定了坚实的基础。 深入探索与未来趋势 进一步的研究将继续探讨GLM的组件如何影响模型在SuperGLUE等基准上的表现,以及如何通过优化设计来提升其在特定任务中的性能。GLM的潜力和创新预示着一个更加开放和高效的预训练语言模型新时代的来临。chatGLM-6B安装与部署
ChatGLM-6B, 一个开源的双语对话语言模型,基于亿参数的GLM架构,特别适合消费级显卡部署(在INT4量化下,6GB显存即可)。然而,我使用GB显存的RTX Ti时,只能选择INT8量化级别运行。首先,确保硬件(如Python、显卡驱动、Git等)和Pytorch环境的准备,可以参考之前的文章。
安装过程中,国内用户可选sjtu.edu镜像源下载ChatGLM要求。官方建议安装Git LFS,但新版本Git通常已包含。默认加载模型时需要GB显存,我的显存受限,因此尝试量化加载,通过以下代码实现:
尽管初始量化加载时间较长,但后续对话回复速度较快。此外,还展示了如何通过gradio部署网页版demo,只需修改web_demo.py中的部分代码。
尽管环境条件有限,下一篇文章将探索P-tuning。ChatGLM-6B的详细信息和源代码可在GitHub项目THUDM/ChatGLM-6B中找到。
2025-02-01 00:331654人浏览
2025-02-01 00:141672人浏览
2025-01-31 23:451763人浏览
2025-01-31 23:422945人浏览
2025-01-31 23:35321人浏览
2025-01-31 23:061990人浏览
中国消费者报杭州讯记者施本允)自打击整治养老诈骗专项行动开展以来,浙江省台州市市场监管系统通过日常监督检查、网络巡查监测、受理投诉举报、查处违法案件、发布消费提醒等方式,持续深入推进打击整治养老诈骗专
1.请问各位老大怎样查看JAVA库函数源码啊请问各位老大怎样查看JAVA库函数源码啊 JAVA库函数源码 可以在sun的网站上下载 如果机器上装了jbuilder的话,jb带的那个jdk本
1.请问各位老大怎样查看JAVA库函数源码啊请问各位老大怎样查看JAVA库函数源码啊 JAVA库函数源码 可以在sun的网站上下载 如果机器上装了jbuilder的话,jb带的那个jdk本

