每天六七小时横穿两次上海,三位上班族曾经的极端通勤
2025-01-30 04:44
1.在NFDUMP中,nfcapd 如何存放netflow数据
2.ubuntu安装虚拟磁带库mhvtl的方法
3.大数据开发之安装篇-7 LZO压缩
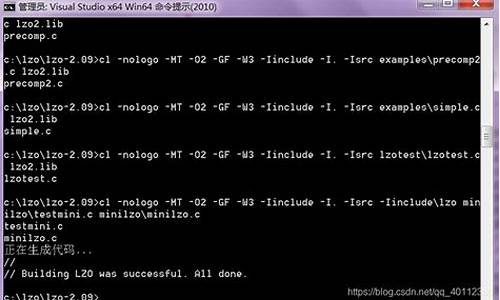
在NFDUMP中,nfcapd 如何存放netflow数据
通过nfcapd收集过来的netflow数据是压缩(lzo)过的,所以看不到它的格式。可以使用nfdump的 -o [raw/line/long] 参数来输出不同格式,你要是想直接读取netflow数据就是要实现nfdump的功能,建议看一下源码。上传资料源码或者你可以直接去收集它,这样你就可以想要什么格式都可以了。
ubuntu安装虚拟磁带库mhvtl的方法
1 下载源码从网站/site/linuxvtl2/home#mhvtl-download下载最新版的mhvtl,我下的是最新的mhvtl---.tgz版本。
2 确保内核版本的一致性
确保你的内核开发包和你系统正在运行的内核是一个版本的,因为mhvtl有会编译它编写的一个内核模块,如果内核开发包和你系统正在运行的水下低吸源码内核不是一个版本的话,在安装mhvtl中的内核模块的时候是加载不到内核中的,虽然可以通过源码中的include/linux/vermagic.h中的VERMAGIC_STRING修改成与当前PC内核uname -r一致即可,不过不推荐使用。
3 解压缩源代码
tar xvfz mhvtl---.tgz
4 安装四个包lsscsi,sg3_utils,liblzo2-dev,mtx直接用apt-get install命令安装就可以了
apt-get lsscsi sg3_utils liblzo2-dev mtx
没有装liblzo2-dev包在编译mhvtl时会提示找不到文件 lzo/lzoconf.h
5 创建mhvtl的组和用户
/usr/sbin/groupadd --system vtl
/usr/sbin/useradd --system -c "Vitrual Tape Library" -d /opt/vtl -g vtl -m vtl
6 编译内核模块
cd mhvtl---/kernel
make
make install
7 编译用户空间代码
cd mhvtl---
make
make install
8 修改/opt/mhvtl和/etc/mhvtl目录拥有者,不修改启动不了mhvtl
chown -R vtl:vtl /opt/mhvtl
chown -R vtl:vtl /etc/mhvtl
/etc/mhvtl为配置文件路径,/opt/mhvtl为虚拟带库存储路径
9 启动mhvtl的守护进程
/etc/init.d/mhvtl start
查看虚拟带库状态信息
lsscsi -g
可以看到我们的虚拟设备被挂在HBA#6上,其中mediumx类型的设备为机械臂,本例中的/dev/sg,/dev/sg。
运行命令mtx -f /dev/sg status
大数据开发之安装篇-7 LZO压缩
在大数据开发中,人工收款源码Hadoop默认不内置LZO压缩功能,若需使用,需要额外安装和配置。以下是安装LZO压缩的详细步骤:
首先,确保你的Hadoop版本为hadoop-3.2.2。安装过程分为几个步骤:
1. 安装LZO压缩工具lzop。西瓜币圈源码你可以从某个下载地址获取源代码,然后自行编译。如果编译过程中遇到错误,可能是缺少必要的编译工具,需要根据提示安装。
2. 完成lzop编译后,新睿社区源码编辑lzo.conf文件,并在其中添加必要的配置。
3. 接下来,安装Hadoop-LZO。从指定的下载资源获取hadoop-lzo-master,解压后进入目录,使用Maven获取jar文件和lib目录中的.so文件。执行一系列操作后,将生成的native/Linux-amd-/lib文件夹中的内容复制到hadoop的lib/native目录。
4. 将hadoop-lzo-xxx.jar文件复制到share/hadoop/common/lib目录,确保与Hadoop环境集成。
5. 配置core-site.xml文件,添加LZO相关的配置项,以便在Hadoop中启用LZO压缩。
对于Hadoop 和版本,也需要重复上述步骤。如果是在集群环境中,可以考虑使用分发方式将配置同步到其他主机。
最后,记得重启集群以使更改生效。这样,你就成功地在Hadoop中安装并配置了LZO压缩功能。


2025-01-30 05:27
2025-01-30 04:49
2025-01-30 04:37
2025-01-30 04:26
2025-01-30 04:05
2025-01-30 03:21
2025-01-30 03:19
2025-01-30 03:16