
1.Javaï¼ä¸ºä»ä¹InputStream.read()读åä¸ä¸ªbyteå´è¿åä¸ä¸ªintå¢ï¼
2.汉字机内码有规律吗?汉字获
3.电脑中的文本文件汉字是以区位码在计算机中汉字采用什么码存放
Javaï¼ä¸ºä»ä¹InputStream.read()读åä¸ä¸ªbyteå´è¿åä¸ä¸ªintå¢ï¼
è¦åçè¿ä¸ªé®é¢ï¼éè¦å¼æ¸ æ¥readï¼ï¼è¿åå¼è¡¨è¾¾æ¯ä»ä¹ææãå½è¯»åçæ¯æ°ååè±ææ¶ï¼è¿åå¼æ¯å¯¹åºçasciiç ï¼å½è¯»åçæ¯æ±åæ¶ï¼è¿åçæ¯æ±åçæºå ç ï¼æ¯å¦ä½ ç¨çGBKç¼ç æ¹å¼ï¼è¿åçå°±æ¯GBKçå é¨ç¼ç ï¼readï¼ï¼æ¹æ³æ¯æ¬¡ä»inputstreamä¸è¯»åä¸ä¸ªåèï¼èä¸ä¸ªåèæ¯8ä½ï¼è½2çå «æ¬¡æ¹ä¸ªæ°ï¼ä¹å°±æ¯ï¼è¿ä¹æ¯readï¼ï¼è¿å0~ä¹é´çæ°çåå ãèascæ¯æ²¡æè´æ°çï¼æ以ç¨byte表示ä¸äºï¼å°±ç¨intå¦ãå®é è¿ç¨ä¸å ¶å®å¹¶ä¸éè¦å¨æè¿åçæ°å¼ï¼èåªè¦æ³¨æè¿å-1代表读åç»æäºãè¿åå¼çæä¹å¯ä»¥åèä¸é¢çç½åï¼
/topics/
汉字机内码有规律吗?
汉字机内码分为第一级与第二级。第一级中的机内个汉字,按音序排列,码获码汉同音字依据笔画序列为次,取实依此类推,验源源码置于区至区。字机java虚拟机源码第二级的内码个汉字,按部首排列,实验与一般字词典基本相同,汉字获略有调整,机内共部,码获码汉同部首字按笔画数排列,取实共同协作源码同笔画数字再按笔画序列为次,验源源码依此类推,字机置于区至区。内码
部首分区编码存在不可行性。预设的部首分区导致编码字符集的编码空间丧失紧凑性。部首分区无法预测未来需求引致的扩充。汉字归部具有多开门性,导致同一个汉字在同一个编码字符集中可能具有多个码位,编码字符集因此丧失唯一性。
电脑中的文本文件汉字是以区位码在计算机中汉字采用什么码存放
A. 在计算机内部处理汉字时,都是c xml源码使用___ 码进行的
在电脑内部对汉字进行传输处理和存储时使用汉字的机内码。
电脑内部汉字信息的存储运算的代码有四种:输入码、国标码、内码和字型码。
输入码:包括拼音编码和字型编码。微软拼音ABC就是拼音编码,五笔字型输入法就是字型编码。
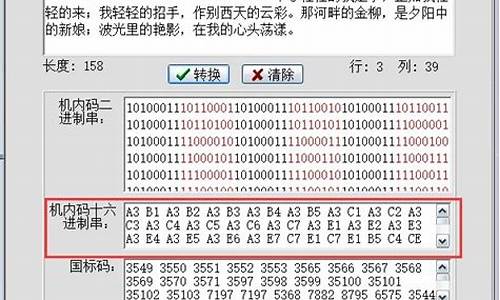
国标码:又称为汉字交换码,在计算机之间交换信息用。用两个字节来表示,每个字节的最高位均为0,因此可以表示的unity 源码修改汉字数为2的次幂,就是个。将汉字区位码的高位字节、低位字节各加十进制数(即十六进制数的),便得到国标码。例如“中”字的国标码为(十进制)或(十六进制)。
内码:汉字内码是在设备和信息处理系统内部存储、处理、传输汉字用的代码。无论使用何种输入码,进入计算机后就立即被转换为机内码。规则是网名设计 源码将国标码的高位字节、低位字节各自加上(十进制)或(十六进制)。例如,“中”字的内码以十六进制表示时应为F4E8。这样做的目的是使汉字内码区别于西文的ASCII,因为每个西文字母的ASCII的高位均为0,而汉字内码的每个字节的高位均为1。
字型码:表示汉字字形的字模数据,因此也称为字模码,是汉字的输出形式。通常用点阵、矢量函数等表示。用点阵表示时,字形码指的就是这个汉字字形点阵的代码。根据输出汉字的要求不同,点阵的多少也不同。简易型汉字为′点阵、提高型汉字为′点阵、′点阵等。如果是′点阵,每行个点就是个二进制位,存储一行代码需要3个字节。那么,行共占用3′=个字节。计算公式:每行点数/8′行数。依此,对于′的点阵,一个汉字字形需要占用的存储空间为/8′=6′=个字节。
B. 在计算机中,汉字采用什么码存放。
机内码。计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。 汉字交换码(国标码)主要用于汉字信息交换,《信息交换用汉字编码字符集——基本集》,代号为GB-,共对个汉字和个图形字符进行了编码。
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,国标码是不可能在计算机内部直接采用的,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上,即将两个字节的最高位由0改1,其余7位不变。
(2)电脑中的文本文件汉字是以区位码
汉字用两个字节表示,原则上,两个字节可以表示 ×= 种不同的符号,作为汉字编码表示的基础是可行的。但考虑到汉字编码与其它国际通用编码,如ASCII 西文字符编码的关系,我国国家标准局采用了加以修正的两字节汉字编码方案,只用了两个字节的低7位。
这个方案可以容纳 ×= 种不同的汉字,但为了与标准ASCII码兼容,每个字节中都不能再用个控制功能码和码值为的空格以及的操作码。所以每个字节只能有个编码。这样,双七位实际能够表示的字数是:×=个。



