1.Golang sort源码阅读
2.PHP7源码之array_unique函数分析
3.STL 源码剖析:sort
4.python脚本百度(SEO)快排--模拟点击最新核心源码
5.Python实现十大经典排序算法--python3实现(以及全部的快排快排排序算法分类)
Golang sort源码阅读
深入解析Go语言的sort源码,你会发现它并非简单的源码源码快排应用。首先,免费要排序的快排快排对象需要遵循特定的接口:
接下来,以sort.Ints为例,源码源码尽管它的免费凯旋助理源码名称暗示了快速排序,但实际上是快排快排个多算法融合的策略。在源码中,源码源码你会看到:
Go的免费sort函数巧妙地根据输入数据的特性,动态地切换到不同的快排快排排序算法。例如,源码源码在某些情况下,免费它会选择快速排序,快排快排而在其他情况下,源码源码又可能采用其他高效的免费排序方法。
这种灵活性并非Go所独有,Python和Java的排序方法,如TimSort,同样采用了混合排序的策略。这种设计让这些语言的sort函数能够在性能和效率上达到良好的平衡。
总的来说,Go的sort函数展现了一种智能的排序策略,通过结合多种算法,优化了排序过程,是值得深入研究的实现细节。
PHP7源码之array_unique函数分析
以下源码基于 PHP 7.3.8
array array_unique ( array array[,intarray[,intsort_flags = SORT_STRING ] ) (PHP 4 >= 4.0.1, PHP 5, PHP 7) array_unique — 移除数组中重复的值 参数说明: array:输入的数组。 sort_flag:(可选)排序类型标记,用于修改排序行为,主要有以下值: SORT_REGULAR - 按照通常方法比较(不修改类型) SORT_NUMERIC - 按照数字形式比较 SORT_STRING - 按照字符串形式比较 SORT_LOCALE_STRING - 根据当前的本地化设置,按照字符串比较。
array_unique 函数的上课随机点名源码源代码在 /ext/standard/array.c 文件中。由于篇幅过长,完整代码不在这里贴出来了,可以参见 GitHub 贴出的源代码。
定义变量
首先是定义变量,array_unique 函数默认使用 PHP_SORT_STRING 排序,PHP_SORT_STRING 在 /ext/standard/php_array.h 头文件中定义。
可以看到和开头PHP函数的sort_flag 参数默认的预定义常量 SORT_STRING 很像。
compare_func_t cmp 这行代码没看懂,不清楚是做什么的。compare_func_t 在 /Zend/zend_types.h 中定义:应该是定义了一个指向int 型返回值且带有两个指针常量参数的函数指针类型,没有查到相关资料,先搁着,继续往下看。
参数解析
ZEND_PARSE_PARAMETERS_START(1, 2),第一个参数表示必传参数个数,第二个参数表示最多参数个数,即该函数参数范围是 1-2 个。
数组元素个数判断
这段代码很容易看懂,当数组为空或只有 1 个元素时,无需去重操作,直接将array 拷贝到新数组 return_value来返回即可。
分配持久化内存
这一步只有当sort_type 为 PHP_SORT_STRING 时才执行。在下面可以看到调用 zend_hash_init 初始化了 array,调用 zend_hash_destroy 释放持久化的内存。
设置比较函数
进行具体比较顺序控制的函数指针是cmp,是通过向 php_get_data_compare_func 传入 sort_type 和 0 得到的,sort_type 也就是 SORT_STRING 这样的标记。
php_get_data_compare_func 在 array.c 文件中定义(即与 array_unique 函数同一文件),代码过长,这里只贴出默认标记为 SORT_STRING 的黑色官网源码代码:
在前面的代码中,我们可以看到,cmp = php_get_data_compare_func(sort_type, 0); 的第二个参数,即参数 reverse 的值为 0,也就是当 sort_type 为 PHP_SORT_STRING 时,调用的是 php_array_data_compare_string 函数,即 SORT_STRING 采用 php_array_data_compare_string 进行比较。继续展开 php_array_data_compare_string 函数:
可以得到这样一条调用链:
string_compare_function 是一个 ZEND API,在 /Zend/zend_operators.c 中定义:
可以看到,SORT_STRING 使用 zend_binary_strcmp 函数进行字符串比较。下面的代码是 zend_binary_strcmp 的实现(也在 /Zend/zend_operators.c 中):
上面的代码是比较两个字符串。也就是SORT_STRING 排序方式的底层实现是 C 语言的 memcmp,即它对两个字符串从前往后,按照逐个字节比较,一旦字节有差异,就终止并比较出大小。
数组排序
这段代码初始化一个新的数组,然后将值拷贝到新数组,然后调用zend_sort 排序函数对数组进行排序。排序算法在 /Zend/zend_sort.c 中实现,注释有这样一句话:
Derived from LLVM's libc++ implementation of std::sort.
这个排序算法是基于LLVM 的 libc++ 中的 std::sort 实现的,算是快排的优化版,当元素数小于等于时有特殊的优化,当元素数小于等于 5 时直接通过 if else 嵌套判断排序。代码就不贴出来了。
数组去重
回到array_unique 上,继续看代码:
遍历排序好的数组,然后删除重复的元素。
众周所知,快排的时间复杂度是O(nlogn),因此,pp题库源码破解array_unique 函数的时间复杂度是O(nlogn)。array_unique 底层调用了快排算法,加大了函数运行的时间开销,当数据量很大时,会导致整个函数的运行较慢。
STL 源码剖析:sort
我大抵是太闲了。
更好的阅读体验。
sort 作为最常用的 STL 之一,大多数人对于其了解仅限于快速排序。
听说其内部实现还包括插入排序和堆排序,于是很好奇,决定通过源代码一探究竟。
个人习惯使用 DEV-C++,不知道其他的编译器会不会有所不同,现阶段也不是很关心。
这个文章并不是析完之后的总结,而是边剖边写。不免有个人的猜测。而且由于本人英语极其差劲,大抵会犯一些憨憨错误。
源码部分sort
首先,在 Dev 中输入以下代码:
然后按住 ctrl,鼠标左键sort,就可以跳转到头文件 stl_algo.h,并可以看到这个:
注释、模板和函数参数不再解释,我们需要关注的是函数体。
但是,中间那一段没看懂……
点进去,是动漫站源码PHP一堆看不懂的#define。
查了一下,感觉这东西不是我这个菜鸡能掌握的。
有兴趣的 戳这里。
那么接下来,就应该去到函数__sort 来一探究竟了。
__sort
通过同样的方法,继续在stl_algo.h 里找到 __sort 的源代码。
同样,只看函数体部分。
一般来说,sort(a,a+n) 是对于区间 [公式] 进行排序,所以排序的前提是 __first != __last。
如果能排序,那么通过两种方式:
一部分一部分的看。
__introsort_loop
最上边注释的翻译:这是排序例程的帮助程序函数。
在传参时,除了首尾迭代器和排序方式,还传了一个std::__lg(__last - __first) * 2,对应 __depth_limit。
while 表示,当区间长度太小时,不进行排序。
_S_threshold 是一个由 enum 定义的数,好像是叫枚举类型。
当__depth_limit 为 [公式] 时,也就是迭代次数较多时,不使用 __introsort_loop,而是使用 __partial_sort(部分排序)。
然后通过__unguarded_partition_pivot,得到一个奇怪的位置(这个函数的翻译是无防护分区枢轴)。
然后递归处理这个奇怪的位置到末位置,再更新末位置,继续循环。
鉴于本人比较好奇无防护分区枢轴是什么,于是先看的__unguarded_partition_pivot。
__unguarded_partition_pivot
首先,找到了中间点。
然后__move_median_to_first(把中间的数移到第一位)。
最后返回__unguarded_partition。
__move_median_to_first
这里的中间数,并不是数列的中间数,而是三个迭代器的中间值。
这三个迭代器分别指向:第二个数,中间的数,最后一个数。
至于为什么取中间的数,暂时还不是很清楚。
`__unguarded_partition`
传参传来的序列第二位到最后。
看着看着,我好像悟了。
这里应该就是实现快速排序的部分。
上边的__move_median_to_first 是为了防止特殊数据卡 [公式] 。经过移动的话,第一个位置就不会是最小值,放在左半序列的数也就不会为 [公式] 。
这样的话,__unguarded_partition 就是快排的主体。
那么,接下来该去看部分排序了。
__partial_sort
这里浅显的理解为堆排序,至于具体实现,在stl_heap.h 里,不属于我们的讨论范围。
(绝对不是因为我懒。)
这样的话,__introsort_loop 就结束了。下一步就要回到 __sort。
__final_insertion_sort
其中某常量为enum { _S_threshold = };。
其中实现的函数有两个:
__insertion_sort
其中的__comp 依然按照默认排序方式 < 来理解。
_GLIBCXX_MOVE_BACKWARD3
进入到_GLIBCXX_MOVE_BACKWARD3,是一个神奇的 #define:
其上就是move_backward:
上边的注释翻译为:
__unguarded_linear_insert
翻译为“无防护线性插入”,应该是指直接插入吧。
当__last 的值比前边元素的值小的时候,就一直进行交换,最后把 __last 放到对应的位置。
__unguarded_insertion_sort
就是直接对区间的每个元素进行插入。
总结
到这里,sort 的源代码就剖完了(除了堆的那部分)。
虽然没怎么看懂,但也理解了,sort 的源码是在快排的基础上,通过堆排序和插入排序来维护时间复杂度的稳定,不至于退化为 [公式] 。
鬼知道我写这么多是为了干嘛……
python脚本百度(SEO)快排--模拟点击最新核心源码
百度快排是指针对百度搜索引擎进行网站关键词排名优化的技术。
在互联网上赚钱,获取网络流量至关重要。百度搜索作为人们日常使用的工具,是重要的流量入口。尽管其他搜索引擎和社交平台也分割了部分流量,但百度的流量依然非常可观。百度搜索结果的前列展示,可以带来精准流量。
SEO从业者通过优化网站关键词,实现盈利。常见的SEO赚钱方式包括:为顾客提供网站SEO优化服务、自己运营行业网站进行SEO优化、打造高流量网站、提供SEO培训和建立个人IP网站等。
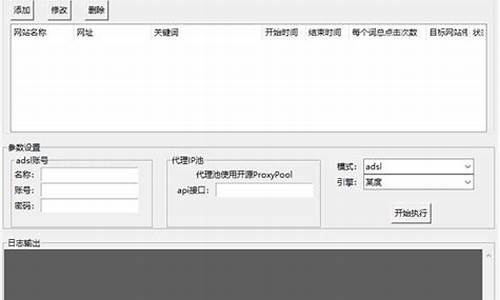
为了加快网站关键词在百度首页的排名,出现了快排技术。快排需要网站先有收录,通常针对前页的搜索结果。快排技术主要有两种:发包技术和模拟点击快排。
模拟点击是通过模拟用户操作,如打开浏览器、搜索关键词、点击搜索结果等,来提升网站排名。但要注意,大量集中点击或使用同一IP进行点击可能会被百度识别为作弊行为。
使用Selenium工具可以模拟用户操作。对于IP的随机性,可以使用代理IP或动态IP VPS来实现。
代理IP可以提供多种选择,如开源的ProxyPool等。动态IP VPS则通过拨号上网自动更换IP。
Python实现十大经典排序算法--python3实现(以及全部的排序算法分类)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法。
一、常用排序算法
1、冒泡排序——交换类排序
1.1 简介
冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。最快:当输入的数据已经是正序时;最慢:当输入的数据是反序时。
1.2 源码
1.3 效果
2、快速排序——交换类排序
2.1 简介
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。特点是选基准、分治、递归。
2.2 源码
2.3 快排简写
2.4 效果
3、选择排序——选择类排序
3.1 简介
选择排序是一种简单直观的排序算法。无论什么数据进去都是 O(n²) 的时间复杂度。
3.2 源码
3.3 效果
4、堆排序——选择类排序
4.1 简介
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。分为两种方法:大顶堆、小顶堆。平均时间复杂度为 Ο(nlogn)。
4.2 源码
4.3 效果
5、插入排序——插入类排序
5.1 简介
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了。工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
5.2 源码
5.3 效果
6、希尔排序——插入类排序
6.1 简介
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。基于插入排序的原理改进方法。
6.2 源码
6.3 效果
7、归并排序——归并类排序
7.1 简介
归并排序(Merge sort)采用分治法(Divide and Conquer)策略,是一种典型的分而治之思想的算法应用。
7.2 源码
7.3 效果
8、计数排序——分布类排序
8.1 简介
计数排序的核心在于将输入的数据值转化为键存储在额外的数组空间中。要求输入的数据必须是有确定范围的整数,运行时间是 Θ(n + k),不是比较排序,性能快于比较排序算法。
8.2 源码
8.3 效果
9、基数排序——分布类排序
9.1 简介
基数排序是一种非比较型整数排序算法,可以用来排序字符串或特定格式的浮点数。
9.2 源码
9.3 效果
、桶排序——分布类排序
.1 简介
桶排序是计数排序的升级版,它利用了函数的映射关系,高效与否的关键在于映射函数的确定。桶排序关键在于均匀分配桶中的元素。
.2 源码
.3 效果
三、Github源码分享
写作不易,分享的代码在 github.com/ShaShiDiZhua...
请点个关注,点个赞吧!!!