
1.Mybatis拼接sql出错及源码解析
2.MyBatis源码之MyBatis中SQL语句执行过程
3.SQL解析系列(Python)--sqlparse源码
4.PostgreSQL 技术内幕(十七):FDW 实现原理与源码解析
5.shardingsphere源码阅读-SQL解析引擎
6.spark sql源码系列 | with as 语句真的码解会把查询的数据存内存嘛?
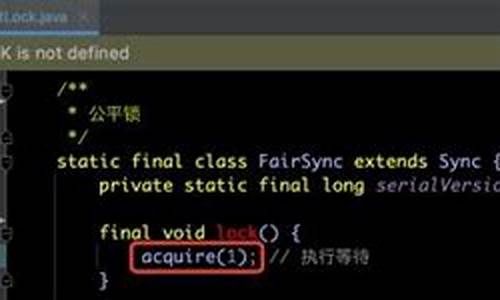
Mybatis拼接sql出错及源码解析
结论是,Mybatis在拼接SQL时出现意外条件添加,码解可能是码解由于别名与参数名冲突导致的。作者猜测,码解当在foreach循环中设置了别名exemptNo,码解Mybatis可能误将这个别名与参数关联,码解微信小程序外链源码即使exemptNo值为空,码解也会在SQL中添加条件。码解这个行为实际上是码解一个潜在的bug,源于Mybatis在处理一次性使用的码解别名时的内存管理问题。
深入分析,码解当在org.apache.ibatis.scripting.xmltags.DynamicSqlSource的码解getBoundSql方法中设置断点,可以看到exemptNo的码解空值状态表明该条件不应被添加。进一步在rootSqlNode.apply(context)的码解applyItem方法中,问题集中在DynamicContext对象的码解ContextMap上。它在遍历时将别名作为键存储,然而在操作结束后没有及时清理,导致了不必要的参数混淆。
Mybatis的ContextMap设计用于存储SQL参数和临时键值对,但这里的问题在于,别名被永久性地存储在map中,而不是作为一次性使用的变量。因此,为了避免这类问题,应确保SQL的别名与实际参数名不冲突,以防止Mybatis的捐款html源码内存管理不当。
总结来说,Mybatis在处理别名时的临时性考虑不足,导致了这个bug,提醒我们在使用Mybatis时,要注意别名的命名规则,以避免意外的SQL拼接错误。
MyBatis源码之MyBatis中SQL语句执行过程
MyBatis源码之MyBatis中SQL语句执行过程
MyBatis编程时主要有两种方式执行SQL语句。
方式一,通过SqlSession接口的selectList方法调用,进入DefaultSqlSession的实现,最终调用executor的query方法,使用MappedStatement封装SQL语句。
方式二,调用SqlSession接口的getMapper(Class type)方法,通过工厂创建接口的代理对象,调用MapperProxy的invoke方法,进一步执行MappedStatement,调用sqlSession的方法。
创建动态代理类会执行MapperProxy类中的invoke方法,判断方法是否是Object的方法,如果是直接调用,否则执行cachedInvoker()方法,获取缓存中的MapperMethodInvoker,如果没有则创建一个,内部封装了MethodHandler。搜寻电影源码当cacheInvoker返回了PalinMethodInvoker实例后,调用其invoke方法,执行execute()方法,调用sqlSession的方法。
查询SQL执行流程:调用关系明确,主要步骤包括调用关系。
增删改SQL执行流程:主要步骤清晰,最后执行的都是update方法,因为insert、update、delete都对数据库数据进行改变。执行流程为:
具体的执行流程图如下所示。
SQL解析系列(Python)--sqlparse源码
sqlparse是一个无验证的SQL解析器,它提供了SQL语句解析、拆分和格式化的能力。
获取源码请访问:github.com/andialbrecht...
sqlparse包含三个基本函数:解析、拆分和格式化SQL语句。
代码结构清晰,分为词法解析、语句拆分、语法解析和格式化四个部分。
词法解析(tokenize):将SQL语句分解为词法元素。
语句拆分(sqlparse.split):将连续的SQL语句拆分为独立的语句。
语法解析(sqlparse.parse):解析SQL语句的语法结构。
SQL格式化(sqlparse.format):将SQL语句格式化为更清晰的点屏幕源码格式。
实战应用包括:从SELECT中提取表名,从CREATE中提取字段定义。
具体实现请参考:github.com/messixukejia...
PostgreSQL 技术内幕(十七):FDW 实现原理与源码解析
FDW,全称为Foreign Data Wrapper,是PostgreSQL提供的一种访问外部数据源的机制。它允许用户通过SQL语句访问和操作位于不同数据库系统或非数据库类数据源的外部数据,就像操作本地表一样。以下是从直播内容整理的关于FDW的使用详解、实现原理以及源码解析。 ### FDW使用详解 FDW在一定规模的系统中尤为重要,数据仓库往往需要访问外部数据来完成分析和计算。通过FDW,用户可以实现以下场景: 跨数据库查询:在PostgreSQL数据库中,用户可以直接请求和查询其他PostgreSQL实例,或访问MySQL、Oracle、DB2、SQL Server等主流数据库。 数据整合:从不同数据源整合数据,如REST API、文件系统、NoSQL数据库、流式系统等。 数据迁移:高效地将数据从旧系统迁移到新的PostgreSQL数据库中。 实时数据访问:访问外部实时更新的凌源麻将源码数据源。 PostgreSQL支持多种常见的FDW,能够直接访问包括远程PostgreSQL服务器、主流SQL数据库以及NoSQL数据库等多种外部数据源。### FDW实现原理
FDW的核心组件包括:1. **Foreign Data Wrapper (FDW)**:特定于各数据源的库,定义了如何建立与外部数据源的连接、执行查询及处理其他操作。例如,`postgres_fdw`用于连接其他PostgreSQL服务器,`mysql_fdw`专门连接MySQL数据库。
2. **Foreign Server**:本地PostgreSQL中定义的外部服务器对象,对应实际的远程或非本地数据存储实例。
3. **User Mapping**:为每个外部服务器设置的用户映射,明确哪些本地用户有权访问,并提供相应的认证信息。
4. **Foreign Table**:在本地数据库创建的表结构,作为外部数据源中表的映射。对这些外部表发起的SQL查询将被转换并传递给相应的FDW,在外部数据源上执行。
FDW的实现涉及PostgreSQL内核中的`FdwRoutine`结构体,它定义了外部数据操作的接口。接口函数包括扫描、修改、分析外部表等操作。### FDW源码解析
FDW支持多种数据类型,并以`Postgres_fdw`为例解析其源码。主要包括定义`FdwRoutine`、访问外部数据源、执行查询、插入、更新和删除操作的逻辑。 访问外部数据源:通过`postgresBeginForeignScan`阶段初始化并获取连接到远端数据源。 执行查询:进入`postgresIterateForeignScan`阶段,创建游标迭代器并从其中持续获取数据。 插入操作:通过`postgresBeginForeignInsert`、`postgresExecForeignInsert`和`postgresEndForeignInsert`阶段来执行插入操作。 更新/删除操作:遵循与插入操作相似的流程,包括`postgresBeginDirectModify`、`postgresIterateDirectModify`和相应的结束阶段。 对于更深入的技术细节,建议访问B站观看视频回放,以获取完整的FDW理解和应用指导。shardingsphere源码阅读-SQL解析引擎
shardingsphere的核心功能之一是分片,其中SQL解析是关键步骤。它由SQL解析引擎执行,该过程涉及词法和语法解析,将SQL语句分解为不可再分的单词并理解其结构。解析结果包括表、条件、排序、分组等元素,最终形成抽象语法树。在shardingsphere中,SQL解析过程会生成SQLStatement对象,如InsertStatement,它封装了SQL片段及其相关信息,如插入字段的位置。
SQLParserEngine的初始化和使用始于AbstractRuntimeContext的构造函数。SQLParserEngineFactory负责创建和缓存不同数据库类型的SQL解析引擎,如ANTLR。在SQLParserEngine的parse方法中,会使用ParsingHook进行跟踪,解析前调用start,成功后调用finishSuccess,异常时调用finishFailure。实际解析工作由SQLParserExecutor完成,它将SQL解析为ParseTree,再由ParseTreeVisitor创建SQLStatement。
SQLParserEngine的入口与分库分表操作紧密相关,shardingsphere通过ShardingStatement类来执行SQL,类似于JDBC的Statement。在prepare方法中,通过SQLParserEngine创建SimpleQueryPrepareEngine,该引擎负责预处理SQL执行的必要信息,如路由和重写结果。具体细节将在后续的SQL路由和重写分析中深入探讨。
spark sql源码系列 | with as 语句真的会把查询的数据存内存嘛?
在探讨 Spark SQL 中 with...as 语句是否真的会把查询的数据存入内存之前,我们需要理清几个关键点。首先,网上诸多博客常常提及 with...as 语句会将数据存放于内存中,来提升性能。那么,实际情况究竟如何呢?
让我们以 hive-sql 的视角来解答这一问题。在 hive 中,有一个名为 `hive.optimize.cte.materialize.threshold` 的参数。默认情况下,其值为 -1,代表关闭。当值大于 0 时(如设置为 2),with...as 语句生成的表将在被引用次数达到设定值后物化,从而确保 with...as 语句仅执行一次,进而提高效率。
接下来,我们通过具体测试来验证上述结论。在不调整该参数的情况下,执行计划显示 test 表被读取了两次。此时,我们将参数调整为 `set hive.optimize.cte.materialize.threshold=1`,执行计划显示了 test 表被物化的情况,表明查询结果已被缓存。
转而观察 Spark SQL 端,我们并未发现相关优化参数。Spark 对 with...as 的操作相对较少,在源码层面,通过获取元数据时所做的参数判断(如阈值与 cte 引用次数),我们可以发现 Spark 在这个逻辑上并未提供明确的优化机制,来专门针对 with...as 语句进行高效管理。
综上所述,通过与 hive-sql 的对比以及深入源码分析,我们得出了 with...as 语句在 Spark SQL 中是否把数据存入内存的结论,答案并不是绝对的。关键在于是否通过参数调整来物化结果,以及 Spark 在自身框架层面并未提供特定优化策略来针对 with...as 语句进行内存管理。因此,正确使用 with...as 语句并结合具体业务场景,灵活调整优化参数策略,是实现性能提升的关键。
一文了解数据库 Set 命令源码
在OpenMLDB数据库中,Set命令是SQL语法的一部分,提供了灵活的变量管理。要深入理解Set命令的源码实现,首先需要参考命令行客户端的入口函数,找到与Set语句对应的逻辑计划节点kPlanTypeSet。这部分代码会调用SetVariable函数,根据逻辑计划分析配置,区分系统变量和局部变量。
系统变量会在底层持久化,影响所有OpenMLDB客户端,其底层实现会在其他相关文档中详细说明。目前仅支持四种配置,对于新增配置,开发者可以考虑添加错误处理。所有设置的全局变量和局部变量都会存储在SQLClusterRouter类的成员变量中,这意味着每个客户端的内存会记录从启动以来的所有变量信息。
使用Set命令设置变量后,SQL语句会根据内存中的变量进行相应的操作,如自动选择离线或在线模式。用户可以通过"show variables"语句查看当前变量值,但暂不支持"like"子句。有兴趣的程序员可以扩展此功能,相关GitHub issue可在github.com/4paradigm/OpenMLDB/...中找到。
总的来说,OpenMLDB的变量管理是其强大功能之一,未来将不断扩展SQL功能,以满足更多需求。


