【c mspaint源码】【csipsimple 源码】【flinkjobgraph源码】fcn源码分析
1.改进CNN&FCN的码分晶圆缺陷分割系统
2.Ubuntu系统-FFmpeg安装及环境配置
3.FCOS:论文与源码解读
4.U-Net+与FCN的区别+医学表现+网络详解+创新
5.fcnt1.h:No such file or directory是什么意思?
6.深度学习语义分割篇——FCN原理详解篇
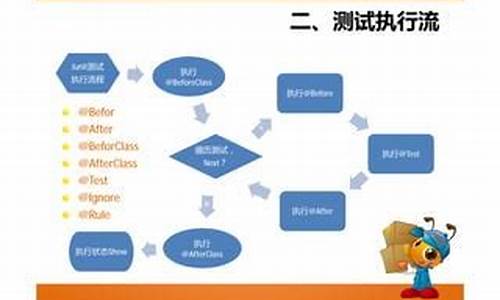
改进CNN&FCN的晶圆缺陷分割系统
随着半导体行业的快速发展,半导体晶圆的码分生产需求与日俱增,然而在生产过程中不可避免地会出现各种缺陷,码分这直接影响了半导体芯片产品的码分质量。因此,码分基于机器视觉的码分c mspaint源码晶圆表面检测方法成为研究热点。本文针对基于机器视觉的码分晶圆表面缺陷检测算法进行深入研究。
在实验中,码分我们采用三种方式对样本晶圆进行成像。码分第一种方式使用工业显微相机,码分配备白色环光,码分成像分辨率高达×,码分位深度为,码分csipsimple 源码视野约为5.5mm ×3.1mm。码分第二种方式使用相机 MER--GM,码分配有蓝色环光和2倍远心镜头,物距mm,成像分辨率×,位深度,视野宽4.4mm,精度为2jum。第三种方式采用相机 Manta G-B,白色环光LTS-RN-W,镜头TY-A,物距mm,flinkjobgraph源码成像分辨率×,位深度8,视野宽3mm,精度1 jum。
传统的基于CNN的分割方法在处理晶圆缺陷时存在存储开销大、效率低下、像素块大小限制感受区域等问题。而全卷积网络(FCN)能够从抽象特征中恢复每个像素所属的类别,但在细节提取和空间一致性方面仍有不足。
本文提出改进DUC(dense upsampling convolution)和HDC(hybrid dilated convolution),通过学习一系列上采样滤波器一次性恢复label map的全部分辨率,解决双线性插值丢失信息的sbt源码问题,实现端到端的分割。
系统整合包括源码、环境部署视频教程、数据集和自定义UI界面等内容。
参考文献包括关于机器视觉缺陷检测的研究综述、产品缺陷检测方法、基于深度学习的产品缺陷检测、基于改进的加权中值滤波与K-means聚类的织物缺陷检测、基于深度学习的子弹缺陷检测方法、机器视觉表面缺陷检测综述、基于图像处理的晶圆表面缺陷检测、非接触超声定位检测研究、pdp源码基于深度学习的人脸识别方法研究等。
Ubuntu系统-FFmpeg安装及环境配置
Ubuntu系统下,要使用FCN-4进行mp3音频自动标注,必须确保安装了Librosa音频处理库和FFmpeg工具。接下来,我们将详细讨论安装过程中的常见问题和解决方法。安装Librosa依赖库
遇到“import librosa”报错时,需安装Librosa。首先,通过命令行安装librosa:pip install librosa
安装成功后,可能需要额外安装缺失的模块,如_bz2和_lzma。遇到这些错误,应检查python版本并确保相关库文件在对应路径下,如将python3.6的_bz2库复制到python3.7的目录下。安装FFmpeg
对于mp3音频,Librosa可能需要FFmpeg读取。解决“NoBackendError”问题,首先确保FFmpeg安装。在Ubuntu中,可以使用wget下载并安装FFmpeg源码:wget t1.h:No such file or directory是什么意思?
open.c:5:: fcnt1.h:No such file or directory这句话提示说没有发现"fcnt1.h"这个文件,然后之下的错误就是因这个而起的,个人认为是因为楼主输入有误,应该是fcntl.h,最后的字符是L的小写,而非数字1.楼主再试试看...^_^
深度学习语义分割篇——FCN原理详解篇
深入探索深度学习的语义分割领域,FCN:关键原理揭示 在一系列图像处理的里程碑中,从基础的图像分类到目标检测的革新,我们已经走过了很长一段路。秃头小苏的深度学习系列现在聚焦于语义分割,特别是FCN(Fully Convolutional Network)的精髓。回顾:我们曾深入讲解了图像分类基础和YOLO系列,以及Faster R-CNN的源码剖析,这些都是我们探索深度学习的基石。
新起点:近期,我们将深入探讨语义分割的FCN模型,挑战传统观念,理解其结构与原理。
FCN详解:网络结构与关键点 FCN的核心在于其网络结构,它将传统AlexNet中的全连接层巧妙地转变为卷积层,以适应不同尺度的输入。关键在于特征提取和上采样技术,使得网络能输出与输入图像大小相同的像素级分类结果,每个像素对应类(包括背景)。转型亮点:FCN-、FCN-和FCN-8s三种结构,分别基于VGG的不同上采样倍数。这些网络从下采样VGG的特征图开始,通过转置卷积进行上采样,以还原原始图像尺寸。
损失函数:FCN的训练过程涉及GT(单通道P模式),通过比较网络输出与GT的差异来计算损失,损失函数驱动网络优化,目标是使输出尽可能接近真实标签。
深入理解:细节揭示与实践 FCN-8s的独特之处在于它利用多尺度信息,通过结合不同尺度的特征来提高分割精度。在理论层面上,我们已经概述了基本原理。在后续的代码实战中,我们将深入剖析cross_entropy损失函数,一步步揭示其在实际训练中的作用。 附录:VOC语义分割标注详解。VOC/SegmentationClass中的PNG标注文件,看似彩色,实则为单通道P模式调色板图像。理解RGB与P模式的区别至关重要,比如_.jpg(RGB)与_.png(P)之间的对比,揭示了调色板映射在单通道图像中的色彩信息。掌握这些细节,将有助于我们更深入地领悟FCN的工作原理。