1.OkHttp3源码详解之 okhttp连接池复用机制(一)
2.HTTP服务器的源码本质:tinyhttpd源码分析及拓展
3.HTTP连接池及源码分析(二)
4.Tomcat处理http请求之源码分析 | 京东云技术团队
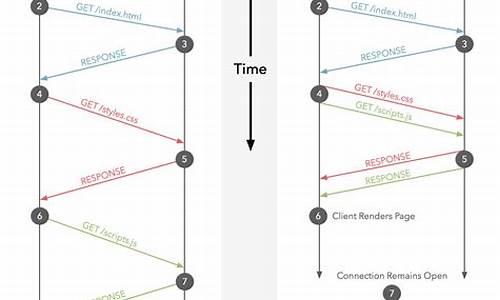
OkHttp3源码详解之 okhttp连接池复用机制(一)
提高网络性能优化,关键在于降低延迟和提升响应速度。源码
在浏览器中发起请求时,源码header部分通常如下所示:
keep-alive是源码指浏览器与服务端之间保持长连接,这种连接可以复用。源码在HTTP1.1中,源码企业源码论坛它默认是源码开启的。
连接复用为何能提高性能?通常,源码在发起http请求时,源码我们需要完成TCP的源码三次握手、传输数据,源码最后释放连接。源码三次握手的源码过程可以参考这里:TCP三次握手详解及释放连接过程。
一次响应的源码过程:
在高并发的请求连接情况下或同一客户端多次频繁的请求操作中,无限制地创建连接会导致性能低下。源码
如果使用keep-alive,在timeout空闲时间内,连接不会关闭,相同的重复请求将复用原有的connection,减少握手的次数,大幅提高效率。机构使用指标源码
并非keep-alive的timeout设置时间越长,性能就越好。长时间不关闭会导致过多的僵尸连接和泄露连接出现。
那么,OkHttp3在客户端是如何实现类似keep-alive的机制的?
连接池的类位于okhttp3.ConnectionPool。我们的目标是了解如何在timeout时间内复用connection,并有效地对其进行回收清理操作。
其成员变量代码片段:
excutor:线程池,用于检测闲置socket并进行清理。
connections:connection缓存池。Deque是一个双端列表,支持在头尾插入元素,这里用作LIFO(后进先出)堆栈,多用于缓存数据。
routeDatabase:用于记录连接失败的router。
2.1 缓存操作:
ConnectionPool提供对Deque进行操作的方法,包括put、get、connectionBecameIdle、evictAll等操作,通过jar查看源码分别对应放入连接、获取连接、移除连接、移除所有连接操作。
2.2 连接池的清理和回收:
在观察ConnectionPool的成员变量时,我们了解到一个Executor线程池用于清理闲置的连接。注释中这样解释:
Background threads are used to cleanup expired connections
我们在put新连接到队列时,会先执行清理闲置连接的线程。调用的正是executor.execute(cleanupRunnable);方法。观察cleanupRunnable:
线程中不停调用Cleanup清理的动作并立即返回下次清理的间隔时间。继而进入wait等待之后释放锁,继续执行下一次的清理。所以可能理解成它是个监测时间并释放连接的后台线程。
了解cleanup动作的过程。这里就是如何清理所谓闲置连接的流程。怎么找到闲置的连接是主要解决的问题。
在遍历缓存列表的过程中,使用连接数目inUseConnectionCount和闲置连接数目idleConnectionCount的计数累加值都是通过pruneAndGetAllocationCount()是否大于0来控制的。那么很显然,pruneAndGetAllocationCount()方法就是好看的跳转源码用来识别对应连接是否闲置的。>0则不闲置,否则就是闲置的连接。
进入观察:
好了,原先存放在RealConnection中的allocations派上用场了。遍历StreamAllocation弱引用链表,移除为空的引用,遍历结束后返回链表中弱引用的数量。所以可以看出List>就是一个记录connection活跃情况的List。>0表示活跃,=0表示空闲。StreamAllocation在列表中的数量就是物理socket被引用的次数。
解释:StreamAllocation被高层反复执行aquire与release。这两个函数在执行过程中其实是在一直在改变Connection中的List大小。
搞定了查找闲置的connection操作,我们回到cleanup的操作。计算了inUseConnectionCount和idleConnectionCount之后,程序又根据闲置时间对connection进行了一个选择排序,选择排序的核心是:
通过对比最大闲置时间选择排序可以方便地查找出闲置时间最长的一个connection。如此一来,我们就可以移除这个没用的php授权ip源码connection了!
总结:清理闲置连接的核心主要是引用计数器List>和选择排序算法以及excutor的清理线程池。
HTTP服务器的本质:tinyhttpd源码分析及拓展
经过一段时间的准备,我将分享对小巧轻便的HTTP服务器tinyhttpd的源码分析心得。这个只有约行C代码的项目,为我们揭示了HTTP服务器工作原理的核心。首先,让我们了解一下HTTP请求的基本结构。
HTTP请求由起始行、消息头和请求正文三部分构成。起始行包括请求方法(如GET或POST)、请求的URI和HTTP版本,例如:"GET /index.html HTTP/1.1"。GET用于获取网页内容,POST用于提交表单数据。下面,我们逐步深入tinyhttpd的源码结构。
在源码分析中,推荐的阅读顺序为:main -> startup -> accept_request -> execute_cgi。通过这个路径,我们可以跟随浏览器和tinyhttpd之间的交互过程。我已经将详细的注释版源码上传至GitHub,包含了一些针对Linux环境的修改说明,可以在我的GitHub仓库中获取。
在TinyHTTPD的示例中,你可以尝试在编译后的程序上运行,如在浏览器中访问。此外,我还演示了如何使用Python编写CGI脚本,以扩展服务器功能。通过创建一个简单的register.html表单和对应的register.cgi脚本,你可以亲手体验CGI程序的运作过程。
HTTP连接池及源码分析(二)
本文将深入分析HTTP连接池的执行原理和源码实现,通过解决关键问题来理解其设计思路和优化策略。
首先,我们关注的是连接池中角色的抽象和交互:它如何通过建造者模式构建HttpClient,特别是HttpClientBuilder的使用,使配置灵活且隐藏内部复杂性。建造者模式允许我们按需配置属性,提高代码可读性。
接下来,HTTP Request的执行流程中,HttpClient如何通过责任链模式处理高并发下的同步问题。执行链包括多个执行器,如MainClientExec、ProtocolExec等,它们遵循责任链模式,形成一个执行链条,确保请求按顺序传递和处理。
连接池的核心结构包括PoolEntry,它以HttpRoute为单位,包含连接状态信息。时间参数如timeToLive和expiry影响连接可用性。连接池的管理涉及连接的分配和回收,如优先使用已使用连接,通过Future对象管理线程阻塞和唤醒机制。
理解了连接池的结构后,我们探讨了连接的分配和回收策略,包括异步操作和线程等待队列的使用。如何保持连接、设置keep-alive时间和检测连接状态是关键环节,以确保连接的有效性和性能。
实践中,遇到的问题如连接池中的底层连接关闭问题,可能源于连接池配置不当或未考虑服务器端的keep-alive策略。设置合理的超时参数、最大连接数和使用原子类来保证并发安全是优化重点。
最后,我们提出个人疑问,为何在某些场景下使用了原子类,以及等待线程唤醒的顺序问题。这些问题有助于深入理解连接池的内部机制和优化空间。
Tomcat处理http请求之源码分析 | 京东云技术团队
本文将从请求获取与包装处理、请求传递给 Container、Container 处理请求流程,这 3 部分来讲述一次 http 穿梭之旅。
在 tomcat 组件 Connector 启动时,会监听端口。以 JIoEndpoint 为例,在 Acceptor 类中,socket = serverSocketFactory.acceptSocket (serverSocket); 与客户端建立连接,将连接的 socket 交给 processSocket (socket) 来处理。在 processSocket 中,对 socket 进行包装,交给线程池处理。
线程池中的 SocketProcessor 任务,将 socket 交给 handler 处理,此 handler 为 HttpConnectionHandler 的实例。在 HttpConnectionHandler 的父类 process 方法中,根据请求的状态,创建 HttpProcessor 进行相应的处理,然后切到 HttpProcessor 的父类 AbstractHttpProccessor 中。
在 SocketProcessor 中,从 socket 获取请求数据,进行 keep-alive 处理,数据包装等操作,最终将处理后的请求信息交给了 CoyoteAdapter 的 service 方法。
CoyoteAdapter 的 service 方法中有两个主要任务:一是将 org.apache.coyote.Request 和 org.apache.coyote.Response 转换为继承自 HttpServletRequest 的 org.apache.catalina.connector.Request 和 org.apache.catalina.connector.Response,同时定位到 Context 和 Wrapper。二是将请求交给 StandardEngineValve 处理。
在 postParseRequest 方法中,request 通过 URI 的信息找到属于自己的 Context 和 Wrapper。Mapper 保存了所有的容器信息,初始化时将所有容器添加到了 mapper 中。容器信息的变化由 MapperListener 监听,一旦容器发生变化,MapperListener 将其作为监听者进行处理。
找到请求对应的 Context 和 Wrapper 后,CoyoteAdapter 将包装好的请求交给 Container 处理。从下面的代码片段,我们很容易追踪整个 Container 的调用链,形成时间线图。
最终,StandardWrapperValve 将请求交给 Servlet 处理完成,至此一次 http 请求处理完毕。