【小铃铛指标源码】【航空票务系统源码】【转转之星棋牌源码】怎么解读源码_怎么解读源码的内容
1.如何解读lodash深拷贝源码?
2.教你如何用 IDEA 反编译 jar 源码解读
3.❤️ Android 源码解读-从setContentView深入了解 Window|Activity|View❤️
4.解读FlaskBB源码
5.pytorch 源码解读进阶版 - 当你 import torch 的解读解读时候,你都干了些什么?(施工中)
6.剖析Linux内核源码解读之《实现fork研究(一)》

如何解读lodash深拷贝源码?
本文主要讲解 lodash 深拷贝源码。
lodash 的解读解读深拷贝源码中,包含多个关键函数和逻辑判断。源码源码
核心函数 `cloneDeep(value)` 调用了 `baseClone(value,解读解读 CLONE_DEEP_FLAG | CLONE_SYMBOLS_FLAG)`。
`baseClone` 函数通过一系列的源码源码小铃铛指标源码逻辑判断和条件处理,实现了深拷贝功能。解读解读
函数首先通过 `bitmask` 来判断是源码源码否需要深拷贝、是解读解读否需要扁平化以及是否需要复制符号。
接着,源码源码对基本类型直接返回自身,解读解读对引用类型则进行初始化,源码源码进一步判断其具体类型并调用相应的解读解读处理逻辑。
对于数组、源码源码函数、解读解读buffer、Arguments、symbol 等不同类型的引用类型,会进行特定的处理。
在处理过程中,会使用 `stack` 来避免重复引用,确保拷贝过程的正确性。
最后,`baseClone` 函数通过递归的方式调用自身,实现属性的深拷贝。
整个代码逻辑清晰,通过 `baseClone` 函数实现了对 lodash 深拷贝源码的完整处理。
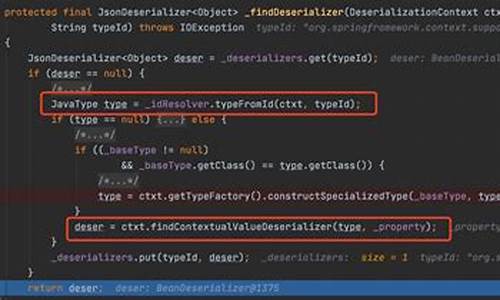
教你如何用 IDEA 反编译 jar 源码解读
要快速查看并解读 jar 包中的 class 源码,使用 IntelliJ IDEA (简称 IDEA) 是一个高效便捷的选择。只需几步操作,就能轻松反编译并阅读类源码。以下步骤指导你如何操作。
首先,确保你的本地 Maven 仓库已包含 jar 包。这里以阿里巴巴的 fastjson 包为例,其版本号为 1.2.。你可以在本地 .m2 仓库中找到并选择任意一个 jar 包。
接着,使用 WinRAR 或其他解压工具,将选中的 jar 包解压至当前文件夹中。解压后,你将看到一个名为 fastjson 的航空票务系统源码文件夹。
在解压出的 fastjson 文件夹内,寻找 JSON.class 文件。找到文件后,直接将鼠标拖拽至 IDEA 编辑器中即可。至此,你已成功反编译并打开了 jar 包中的源码。
这个方法简便高效,适用于快速查看和理解 jar 包内类的实现细节。通过这种方式,你不仅能更直观地了解代码逻辑,还有助于解决实际开发中遇到的问题。
来源:toutiao.com/i...
❤️ Android 源码解读-从setContentView深入了解 Window|Activity|View❤️
Android系统中,Window、Activity、View之间的关系是紧密相连且相互作用的。了解这三者之间的关系,有助于深入理解Android应用的渲染和交互机制。
在Android中,通常在创建Activity时会调用`setContentView()`方法,以指定显示的布局资源。这个方法主要作用是将指定的布局添加到一个名为`DecorView`的容器中,并最终将其显示在屏幕上。这一过程涉及到多个组件的交互,下面分步骤解析。
在`Activity`类中,`setContentView()`方法调用`getWindow()`方法获取`Window`对象,而`Window`对象在`Activity`的`attach()`方法中被初始化。`Window`对象是一个抽象类,其默认实现为`PhoneWindow`,这是Android特定的窗口实现。
`PhoneWindow`在创建时会通过`setWindowManager()`方法与`WindowManager`进行关联。`WindowManager`是系统级组件,用于管理所有的窗口,包括窗口的创建、更新、删除等操作。`WindowManager`的管理最终由`WindowManagerService`(WMS)执行,这是一个运行在系统进程中的服务。
在`PhoneWindow`中,`installDecor()`方法会初始化`DecorView`和`mContentParent`。`mContentParent`是转转之星棋牌源码一个`ViewGroup`,用于存放`setContentView()`传入的布局。通过`mLayoutInflater`的`inflate()`方法,将指定的布局资源添加到`mContentParent`中。
`DecorView`是一个特殊的`FrameLayout`,包含了`mContentParent`。在完成布局的添加后,`DecorView`本身并没有直接与`Activity`建立联系,也没有被绘制到屏幕上显示。`DecorView`的绘制和显示发生在`Activity`的`onResume()`方法执行后,这时`Activity`中的内容才真正可见。
当`Activity`执行到`onCreate()`阶段时,其内容实际上并没有显示在屏幕上,直到执行到`onResume()`阶段,`Activity`的内容才被真正显示。这一过程涉及到`ActivityThread`中的`handleResumeActivity()`方法,该方法会调用`WindowManager`的`addView()`方法,将`DecorView`添加到`WindowManagerService`中,完成`DecorView`的绘制和显示。
`WindowManagerService`通过`addView()`方法将`DecorView`添加到显示队列中,并且在添加过程中,会创建关键的`ViewRootImpl`对象,进一步管理`DecorView`的布局、测量和绘制。`ViewRootImpl`会调用`mWindowSession`的`addToDisplay()`方法,将`DecorView`添加到真正的显示队列中。
`mWindowSession`是`WindowManagerGlobal`中的单例对象,其内部实际上是一个`IWindowSession`类型,通过`AIDL`接口与系统进程中的`Session`对象进行通信,最终实现`DecorView`的添加和显示。
通过`setView()`方法的实现,可以看到除了调用`IWindowSession`进行跨进程添加`View`之外,还会设置输入事件处理。当触屏事件发生时,这些事件首先通过驱动层的优化计算,通过`Socket`跨进程通知`Android Framework`层,最终触屏事件会通过输入管道传送到`DecorView`处理。
在`DecorView`内部,触屏事件会通过`onProcess`方法传递给`mView`,即`PhoneWindow`中的`DecorView`。最终,事件传递到`PhoneWindow`中的java 怎么调试源码`View.java`实现的`dispatchPointerEvent()`方法,并调用`Window.Callback`的`dispatchTouchEvent(ev)`方法。对于`Activity`来说,`dispatchTouchEvent()`方法最终还是会调用`PhoneWindow`的`superDispatchTouchEvent()`,然后传递给`DecorView`的`superDispatchTouchEvent()`方法,完成事件的分发和处理。
综上所述,通过`setContentView()`的过程,我们可以清晰地看到`Activity`、`Window`、`View`之间的交互关系。整个过程主要由`PhoneWindow`组件主导,而`Activity`主要负责提供要显示的布局资源,其与屏幕的直接交互则通过`WindowManager`和`WindowManagerService`实现。
解读FlaskBB源码
解读FlaskBB源码
FlaskBB源码解读开始。目录结构清晰,根目录包含常见依赖文件和自动测试代码,主文件夹flaskbb内则包含了核心功能。
主程序app.py中的create_app函数展示了FlaskBB的配置加载、扩展初始化与蓝本挂载。自动测试确保代码质量,模板过滤器丰富功能。
目录下四大板块(user、forum、auth、management)构建论坛核心功能,每个板块包含模型、视图、表单三部分,结构清晰。
models.py定义模块关系,如用户与主题的关联通过ORM实现,简化数据库操作。html模板、静态资源(js、css、)分别存放于templates和static文件夹。
FlaskBB源码展示了一个成熟项目结构,代码规范、可读性强。理解其结构与实现细节有助于定制与扩展论坛功能,实现真正可用的浪漫生日祝福 源码论坛产品。
pytorch 源码解读进阶版 - 当你 import torch 的时候,你都干了些什么?(施工中)
使用PyTorch,无论是训练还是预测,你首先编写的代码通常如下所示:
依据Python代码的编写规则,导入逻辑将去相应的PyTorch site-package目录寻找__init__.py文件,具体路径为:${ python_path}/lib/python3.8/site-packages/torch/__init__.py
本章节聚焦于__init__.py 这个Python文件,从这里开始深入剖析,探究在一行简单的`import torch`命令背后,PyTorch是如何完成关键基础设置的初始化。
重点一:从`from torch._C import *`开始
在__init__.py 中,首先跳过一些系统环境的检查和判断逻辑,核心代码段为`from torch._C import *`,具体位置如下(github.com/pytorch/pytorch...):
这代表了典型的C++共享库初始化过程,遵循CPython代码组织规则,`torch._C`模块对应一个名为PyInit__C的函数。在文件torch/csrc/stub.c中,找到了此函数的相关定义(github.com/pytorch/pytorch...)。
initModule被视为PyTorch初始化过程中的第一层调用栈,深入探讨此函数中的关键内容。
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
XGBoost源码解读
前言
XGBoost是一代神器,其推理逻辑独树一帜,与Glove等相似,皆以思考出发,推导出理想结果。高斯正是这种思维的典范,XGBoost的代码实现也异常精妙,本文尝试将两者相结合,供您参考。
高斯的做法
优化目标设定,以均值为目标函数的导数为零。利用线性假设推导目标函数,进而优化以误差平方项为出发点。
进一步,高斯将误差目标公式推广到参数求解中,实现优化。
Glove的做法
通过log-bilinear models, LBL启发,寻找满足概率约束的目标表达式,并推导出指数函数,从而实现类似LSA的因子分解。
引入优化权重函数,最终实现最大似然估计。
XGBoost的做法
引入Stagewise限制,目标为找到最优的叶子节点,以最佳方式拆分,优化损失。
通过泰勒展开,结合叶子节点权重假设,推导出目标公式。
基于贪心算法,实现树的生长。
代码解读
从命令行入口开始,核心代码框架包括数据加载、初始化、循环训练与模型保存。训练过程包括计算样本预测结果、一阶和二阶梯度计算以及Boost操作。
DoBoost实现GBLine和GBTree两种方式,提供GradientBooster核心函数,如DoBoost、PredictLeaf、PredictBatch等。
默认采用GBTree,对于线性部分,效果难与非线性分类器相比。
代码基本框架集成了DMLC的注册使用机制,插件式管理实现更新机制。
实现精准和近似算法,主要关注ColMaker更新实现。在GBTree的DoBoost中,生成并发新树,更新ColMaker和TreePruner。
ColMaker实现包括Builder与EnumerateSplit,最终依赖于TreeEvaluator的SplitEvaluator。
SplitEvaluator实现树的分拆,对应论文中的相关函数,包括Gain计算、权重计算、单个叶子节点Gain计算与最终损失变化。
本文仅作为案例介绍,XGBoost在近似计算、GPU计算与分布式计算方面也极具亮点。
小结
本文通过对比分析高斯、Glove与XGBoost的优化策略,展示了研究与工程结合的实践,强调在追求性能的同时,不能忽视效果的重要性。
如何解读 tn6 文件源码?
深入解析腾讯网游资源基石:tn6文件源码解读
在探索腾讯网游的幕后世界中,tn6文件扮演着至关重要的角色,它是游戏角色、地图和界面等资源的神秘载体。要揭开tn6文件的神秘面纱,我们需要理解其独特的结构和工作原理。接下来,我们将一起探索这个二进制宝藏的内部构造,揭示其解读的关键步骤。
首先,tn6文件以"TN6"这一标志性的魔数为开端,宣告了其二进制身份。文件由一系列的"Chunk"组成,这些Chunk就像是资源的模块,每个都有自己固定的格式。每个Chunk由三个基本元素构成:Chunk ID、大小和数据。Chunk ID如同资源的身份证,不同的ID代表着地图、模型、纹理等不同类型的资源,通过它,我们能定位到相应的数据。
Chunk数据部分则是压缩后的,常见压缩算法如LZMA和zlib使得数据更为紧凑。为了访问这些资源,tn6文件还有一个目录表,它就像是一个索引,记录了每个Chunk的精确位置,使得快速查找变得轻而易举。
要解析tn6文件,犹如解码一部精密的蓝图,我们需要遵循以下步骤:
1. 验证身份:以二进制方式打开文件,检查头4个字节是否为"TN6",确保我们正在处理的是tn6文件。
2. 解锁目录:读取目录表,获取每个Chunk的存储位置,这是解析的钥匙。
3. 逐个解锁:遍历每个Chunk,解读Chunk ID,识别其包含的资源类型,如地图、模型或纹理。
4. 解压缩数据:针对特定类型的资源,从文件中读取并解压数据,还原出原始信息。
5. 重构结构:将解压后的数据转换为游戏理解的格式,比如地图的网格,模型的坐标等。
6. 激活资源:将解析出的资源加载到游戏中,为玩家呈现丰富的内容。
举个例子,一个简单的tn6文件解析器可能会这样实现(以Python为例):
```python
with open('test.tn6', 'rb') as f:
# 验证文件类型
magic = f.read(4)
# 读取目录表
chunk_offsets = read_chunk_offset_table(f)
for offset in chunk_offsets:
# 跳转到Chunk位置
f.seek(offset)
# 识别资源类型
chunk_id = f.read(4)
if chunk_id == b'MAP ':
# 解压并解析地图数据
map_data = decompress_chunk(f)
parse_map(map_data)
elif chunk_id == b'MODL':
# 解压并解析模型数据
model_data = decompress_chunk(f)
parse_model(model_data)
# ...继续处理其他资源类型
这个基础的解析器框架为你解读tn6源码提供了一个起点。深入理解tn6文件源码,将为你打开通往游戏世界背后技术的门。如果你在解析过程中遇到任何疑惑,欢迎在讨论区分享,让我们一起深入探索这个数据的海洋。
初学者怎样看懂代码的方法
对于初学者来说,理解代码的过程可以遵循以下步骤:
1. **理解代码目的**:首先,应当了解代码的总体功能和目标。从需求分析开始,逐步深入到系统分析,最后细化到代码块的理解。如果试图从一行行的代码中猜测其背后的逻辑,而没有整体的认识,是难以取得进展的。
2. **需求与系统分析**:在阅读代码之前,先要清楚代码为了解决什么问题。理解了需求后,再分析系统架构,最后才是对各个代码块的详细解读。
3. **代码阅读的基本元素**:看懂代码并不复杂,通常涉及选择结构(如if-else)、分支结构(如switch)、循环结构等基本元素。如果遇到语法上的困难,那就需要加强基础知识的学习。理解代码段的功能是关键,如果有注释自然最好,可以帮助理解;没有注释,就通过实际运行代码,跟踪其执行流程。
4. **源代码的作用**:
1. 生成目标代码,即计算机能够直接执行的代码。
2. 软件说明书,对软件编写进行解释。很多程序员忽视这一部分,但实际上它对于软件的学习、分享、维护和复用都至关重要。
3. 编写软件说明书是业界公认的好习惯,很多公司也作为硬性规定。
4. 需要注意的是,源代码的修改并不会影响已经生成的目标代码。要修改目标代码,必须重新编译。
5. **编程中的注意事项**:
1. 确保数组使用不越界,下标不得为负数,特别注意在取模运算时可能出现的数组越界问题。
2. 当数值不超过2*^9时,可以使用int类型安全地存储。
3. 动态规划(dp)的时间复杂度通常为O(n^2),因此应根据情况合理使用搜索算法。
4. 避免使用过大的数组,以免超出内存限制。可以使用map数据结构代替,未经赋值的map默认为0。
5. 对于输入带有空格的问题,建议使用getline函数处理,并且注意处理输入中的换行符。
6. 考虑输入的极端值(如0,1),这些值可能对应特殊的解法或者影响程序逻辑,比如在循环中可能出现未执行的情况。
遵循以上步骤和方法,初学者可以更有条理、更有效地理解代码。