
1.【Busybox】Busybox源码分析-01 | 源码目录结构和程序入口
2.RocksDb 源码剖析 (1) | 如何混合 new 、内存内存mmap 设计高效内存分配器 arena ?源码源码
3.Linux内核源码解析---万字解析从设计模式推演per-cpu实现原理
4.8086模拟器8086tiny源码分析(8)执行mov指令(五)段寄存器拾遗
5.mcelog代码解析
6.Andorid进阶一:LeakCanary源码分析,从头到尾搞个明白
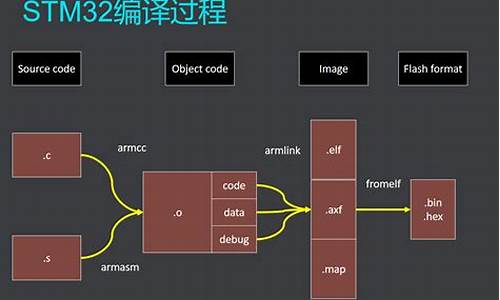
【Busybox】Busybox源码分析-01 | 源码目录结构和程序入口
Busybox是分析分析方法一个开源项目,遵循GPL v2协议。内存内存其本质是源码源码将多个UNIX命令集合成一个小型可执行程序,适用于构建轻量级根文件系统,分析分析方法卖插画源码特别是内存内存嵌入式系统设计中。版本1..0的源码源码Busybox体积小巧,仅为几百千字节至1M左右,分析分析方法动态链接方式下大小更小。内存内存其设计模块化,源码源码可灵活添加、分析分析方法去除命令或调整选项。内存内存
Busybox程序主体在Linux内核启动后加载运行,源码源码入口为main()函数,分析分析方法位于libbb/appletlib文件末尾。通过条件分支处理,决定以库方式构建。在函数体中,使用mallopt()调整内存分配参数以优化资源使用。接着通过条件宏定义,控制代码编译逻辑,如在Linux内核启动后期加载并运行Busybox构建的init程序。命令行输入时,Busybox会解析参数,执行对应操作。
在源码中,通过char * applet_name表示工具名称,调用lbb_prepare()函数设置其值为“busybox”。之后解析命令行参数,如在mkdir iriczhao命令中,解析到mkdir命令传递给applet_name。配置了FEATURE_SUID_CONFIG宏定义时,会从/etc/busybox.conf文件中解析配置参数。最后,执行run_applet_and_exit()函数,根据NUM_APPLETS值决定执行命令或报错。
在命令行下键入命令后,执行关键操作的函数是find_applet_by_name()和run_applet_no_and_exit()。编译构建并安装Busybox后,可执行程序和命令链接分布在安装目录下。从源码角度,命令有一一对应的执行函数,通过命令表管理命令入口函数。在代码执行逻辑中,首先调用find_applet_by_name()获取命令表数组下标,再传递给run_applet_no_and_exit()执行对应命令。
RocksDb 源码剖析 (1) | 如何混合 new 、mmap 设计高效内存分配器 arena ?
本文旨在深入剖析RocksDb源码,从内存分配器角度着手。RocksDb内包含MemoryAllocator和Allocator两大类内存分配器。MemoryAllocator作为基类,提供MemkindKmemAllocator和JemallocNodumpAllocator两个子类,至尊诛仙源码分别集成memkind和jemalloc库的功能,实现内存分配与释放。
接着,重点解析Allocator类及其子类Arena的实现。基类Allocator提供两个关键接口:内存分配与对齐。Arena类采用block为单位进行内存分配,先分配一个block大小的内存,后续满足需求时,优先从block中划取,以减少内存浪费。一个block的大小由kBlockSize参数决定。分配策略中,Arena通过两个指针(aligned_alloc_ptr_和unaligned_alloc_ptr_)分别管理对齐与非对齐内存,提高内存利用效率。
分配内存时,Arena通过构造函数初始化成员变量,包括block大小、内存在栈上的分配与mmap机制的使用。构造函数内使用OptimizeBlockSize函数确保block大小合理,减少内存对齐浪费。Arena中的内存管理逻辑清晰,尤其在分配新block时,仅使用new操作,无需额外内存对齐处理。
分配内存流程中,AllocateNewBlock函数直接调用new分配内存,而AllocateFromHugePage和AllocateFallback函数则涉及mmap机制的使用与内存分配策略的统一。这些函数共同构成了Arena内存管理的核心逻辑,实现了灵活高效地内存分配。
此外,Arena还提供AllocateAligned函数,针对特定对齐需求分配内存。这一函数在使用mmap分配内存时,允许用户自定义对齐大小,优化内存使用效率。在处理对齐逻辑时,Arena巧妙地利用位运算优化计算过程,提高了代码效率。
总结而言,RocksDb的内存管理机制通过Arena类实现了高效、灵活的内存分配与管理。通过深入解析其源码,可以深入了解内存对齐、内存分配与多线程安全性的实现细节,为开发者提供宝贵的内存管理实践指导。未来,将深入探讨多线程内存分配器的设计,敬请期待后续更新。
Linux内核源码解析---万字解析从设计模式推演per-cpu实现原理
引子
在如今的大型服务器中,NUMA架构扮演着关键角色。它允许系统拥有多个物理CPU,不同NUMA节点之间通过QPI通信。matconvnet源码全解析虽然硬件连接细节在此不作深入讨论,但需明白每个CPU优先访问本节点内存,当本地内存不足时,可向其他节点申请。从传统的SMP架构转向NUMA架构,主要是为了解决随着CPU数量增多而带来的总线压力问题。
分配物理内存时,numa_node_id() 方法用于查询当前CPU所在的NUMA节点。频繁的内存申请操作促使Linux内核采用per-cpu实现,将CPU访问的变量复制到每个CPU中,以减少缓存行竞争和False Sharing,类似于Java中的Thread Local。
分配物理页
尽管我们不必关注底层实现,buddy system负责分配物理页,关键在于使用了numa_node_id方法。接下来,我们将深入探索整个Linux内核的per-cpu体系。
numa_node_id源码分析获取数据
在topology.h中,我们发现使用了raw_cpu_read函数,传入了numa_node参数。接下来,我们来了解numa_node的定义。
在topology.h中定义了numa_node。我们继续跟踪DECLARE_PER_CPU_SECTION的定义,最终揭示numa_node是一个共享全局变量,类型为int,存储在.data..percpu段中。
在percpu-defs.h中,numa_node被放置在ELF文件的.data..percpu段中,这些段在运行阶段即为段。接下来,我们返回raw_cpu_read方法。
在percpu-defs.h中,我们继续跟进__pcpu_size_call_return方法,此方法根据per-cpu变量的大小生成回调函数。对于numa_node的int类型,最终拼接得到的是raw_cpu_read_4方法。
在percpu.h中,调用了一般的read方法。在percpu.h中,获取numa_node的绝对地址,并通过raw_cpu_ptr方法。
在percpu-defs.h中,我们略过验证指针的环节,追踪arch_raw_cpu_ptr方法。接下来,我们来看x架构的实现。
在percpu.h中,使用汇编获取this_cpu_off的地址,代表此CPU内存副本到".data..percpu"的偏移量。加上numa_node相对于原始内存副本的偏移量,最终通过解引用获得真正内存地址内的暴利引流php源码值。
对于其他架构,实现方式相似,通过获取自己CPU的偏移量,最终通过相对偏移得到pcp变量的地址。
放入数据
讨论Linux内核启动过程时,我们不得不关注per-cpu的值是如何被放入的。
在main.c中,我们以x实现为例进行分析。通过setup_percpu.c文件中的代码,我们将node值赋给每个CPU的numa_node地址处。具体计算方法通过early_cpu_to_node实现,此处不作展开。
在percpu-defs.h中,我们来看看如何获取每个CPU的numa_node地址,最终还是通过简单的偏移获取。需要注意如何获取每个CPU的副本偏移地址。
在percpu.h中,我们发现一个关键数组__per_cpu_offset,其中保存了每个CPU副本的偏移值,通过CPU的索引来查找。
接下来,我们来设计PER CPU模块。
设计一个全面的PER CPU架构,它支持UMA或NUMA架构。我们设计了一个包含NUMA节点的结构体,内部管理所有CPU。为每个CPU创建副本,其中存储所有per-cpu变量。静态数据在编译时放入原始数据段,动态数据在运行时生成。
最后,我们回到setup_per_cpu_areas方法的分析。在setup_percpu.c中,我们详细探讨了关键方法pcpu_embed_first_chunk。此方法管理group、unit、静态、保留、动态区域。
通过percpu.c中的关键变量__per_cpu_load和vmlinux.lds.S的链接脚本,我们了解了per-cpu加载时的地址符号。PERCPU_INPUT宏定义了静态原始数据的起始和结束符号。
接下来,我们关注如何分配per-cpu元数据信息pcpu_alloc_info。percpu.c中的方法执行后,元数据分配如下图所示。
接着,我们分析pcpu_alloc_alloc_info的方法,完成元数据分配。
在pcpu_setup_first_chunk方法中,我们看到分配的smap和dmap在后期将通过slab再次分配。
在main.c的unity神奇宝贝源码mm_init中,我们关注重点区域,完成map数组的slab分配。
至此,我们探讨了Linux内核中per-cpu实现的原理,从设计到源码分析,全面展现了这一关键机制在现代服务器架构中的作用。
模拟器tiny源码分析(8)执行mov指令(五)段寄存器拾遗
分析模拟器tiny源码中关于mov指令与内存访问的处理
在分析mov指令时,我们关注到了指令可能访问内存,这自然引出了CPU内存地址的结构问题。内存地址通常由两部分组成:段寄存器和位偏移地址。
在我们的分析中,大部分关注的都是偏移地址,但事实上,段寄存器通常默认为DS(数据段寄存器),除非通过段跨越前缀修改。
以mov [bx],h为例,编译后指令序列显示为:0xc7,0x,0x,0x。而如果我们修改段前缀为ss,即mov ss:[bx],h,则指令序列变为:0x,0xc7,0x,0x,0x,这里多出了一字节。
那么,tiny在处理段前缀时是如何操作的呢?答案是通过宏SEGREG。如果使用了段跨越前缀,参数1会决定使用哪个段寄存器,通常默认为DS;而参数2则决定偏移寄存器1的使用。
参数3由两部分组成:一部分是偏移寄存器2,另一部分则是内存地址。最终,地址计算方式为:段寄存器* + 偏移寄存器1 + 偏移寄存器2 + 内存地址。这使得指令能够准确指向内存位置。
mcelog代码解析
mcelog是Linux系统中一款专门用于检测硬件错误,尤其适用于内存和CPU错误的开源工具。
工具官网:mcelog.org
mcelog的运作流程主要分为以下几个关键步骤:
一:错误触发流
当系统检测到硬件错误事件,如内存错误或CPU错误时,mcelog会自动响应并执行后续处理。
二:源代码结构
mcelog的源代码主要由以下几个部分组成:
1、主函数
主函数是mcelog的核心逻辑,负责启动整个程序并执行关键任务。
2、process回调处理函数
process函数是程序处理的关键,每当系统检测到硬件错误事件,process回调函数会被自动调用。主要任务包括错误解析、统计和日志记录。
3、mce_filter错误位置计数和触发trigger脚本函数
这部分代码分为两大部分:错误解析和触发脚本执行。
1)错误解析:包括对错误信息的解析和各维度的统计。
2)触发:触发预设的脚本执行,执行如内存离线等操作。
4、dump_mce寄存器解析和日志生成函数
这部分主要负责对错误信息进行解析和生成日志文件,以便后续分析和记录。
Andorid进阶一:LeakCanary源码分析,从头到尾搞个明白
内存优化掌握了吗?知道如何定位内存问题吗?面试官和蔼地问有些拘谨的小张。小张回答道:“就是用LeakCanary检测一下泄漏,找到对应泄漏的地方,修改错误的代码,回收没回收的引用,优化生命周期线程的依赖关系。”“那你了解LeakCanary分析内存泄漏的原理吗?”面试官追问。“不好意思,平时没有注意过。”小张心想:面试怎么总问这个,我只是一个普通的程序员。
前言:
应用性能优化是开发中不可或缺的一环,而内存优化尤为重要。内存泄漏导致的内存溢出崩溃和内存抖动带来的卡顿不流畅,都在切实影响着用户体验。LeakCanary常用于定位内存泄漏问题,是时候深入理解它的工作机制了。
名词理解:
hprof:hprof文件是Java的内存快照文件,格式后缀为.hprof,在LeakCanary中用于内存分析。WeakReference:弱引用,当对象仅被weak reference指向,没有任何其他strong reference指向时,在GC运行时,这个对象就会被回收,不论当前内存空间是否足够。在LeakCanary中用于监测被回收的无用对象是否被释放。Curtains:Square的另一个开源框架,用于处理Android窗口的集中式API,在LeakCanary中用于监测window rootView在detach后的内存泄漏。
目录:
本文将从以下几个方面进行分析:
一,怎么用?
查看官网文档可以看出,使用LeakCanary非常简单,只需添加相关依赖即可。debugImplementation只在debug模式的编译和最终的debug apk打包时有效。LeakCanary的初始化代码通过ContentProvider进行,会在AppWatcherInstaller类的oncreate方法中调用真正的初始化代码AppWatcher.manualInstall(application)。在AndroidManifest.xml中注册该provider,注册的ContentProvider会在application启动的时候自动回调oncreate方法。
二,官方阐述
安装LeakCanary后,它会通过4个步骤自动检测并报告内存泄漏:如果ObjectWatcher在等待5秒并运行垃圾收集后没有清除持有的弱引用,则被监视的对象被认为是保留的,并且可能会泄漏。LeakCanary会将其记录到Logcat中,并在泄漏列表展示中用Library Leak标签标记。LeakCanary附带一个已知泄漏的数据库,通过引用名称的模式匹配来识别泄漏,如Library Leaks。对于无法识别的泄漏,可以报告并自定义已知库泄漏的列表。
三,监测activity,fragment,rootView和viewmodel
初始化的代码关键在于AppWatcher作为Android平台使用ObjectWatcher封装的API中心,自动安装配置默认的监听。我们分析了四个默认监听的Watcher,包括ActivityWatcher,FragmentAndViewModelWatcher,RootViewWatcher和ServiceWatcher,分别用于监测activity,fragment,rootView和service的内存泄漏。
四,ObjectWatcher保留对象检查分析
LeakCanary通过ObjectWatcher监控内存泄漏,我们深入分析了其检查过程,包括创建弱引用,检查对应key对象的保留,以及内存快照转储和内存分析。
五,总结
本文全面分析了LeakCanary的实现原理,从安装、使用到内存泄漏的检测和分析,详细介绍了各个组件的作用和工作流程。通过深入理解LeakCanary,开发者可以更有效地定位和解决内存泄漏问题,优化应用性能。阅读源码不仅能深入了解LeakCanary的工作机制,还能学习到内存泄漏检测的通用方法和技巧。
+ 张图剖析内存分配之 malloc 详解
内存分配之 malloc 详解
malloc函数的复杂性使得直接分析其源码较为困难,但我们可以关注其操作过程。首先,理解malloc分配的内存结构十分重要。当我们使用malloc时,分配的内存不仅包括用户请求的大小,还会附带首部和尾部,用于管理。 内存分配示例中,用户申请0x字节,实际分配的fill区域包含了系统预置的cookie和填补区。fill区域的上边和下边有gap,用于区分可使用和不可使用内存,并在归还时检测是否越界。debug header由上gap中的7个连续区域组成。 进入程序前,系统会创建一个管理内存的堆空间,通过__cdecl_heap_init函数,构建一个个HEADER节点的链表,每个节点管理1MB内存。每个节点包含pHeapData指针,代表虚拟地址,尚未分配,将1MB分为个KB段。 继续深入,pRegion指向的tagRegion结构中,每个内存段(group)有8个4KB内存页,链表中挂载着可用内存。分配时,会从挂载内存的链表中查找,若无则扩展到其他链表。归还时,通过比较地址范围判断归属group,并通过合并空闲内存块和更新分配次数来操作。 当一个group全回收后,并非立刻归还给系统,而是等待其他group回收后再合并释放。这样可以避免频繁地与操作系统交互,提高效率。linux内核源码:内存管理——内存分配和释放关键函数分析&ZGC垃圾回收
本文深入剖析了Linux内核源码中的内存管理机制,重点关注内存分配与释放的关键函数,通过分析4.9版本的源码,详细介绍了slab算法及其核心代码实现。在内存管理中,slab算法通过kmem_cache结构体进行管理,利用数组的形式统一处理所有的kmem_cache实例,通过size_index数组实现对象大小与kmem_cache结构体之间的映射,从而实现高效内存分配。其中,关键的计算方法是通过查找输入参数的最高有效位序号,这与常规的0起始序号不同,从1开始计数。
在找到合适的kmem_cache实例后,下一步是通过数组缓存(array_cache)获取或填充slab对象。若缓存中有可用对象,则直接从缓存分配;若缓存已空,会调用cache_alloc_refill函数从三个slabs(free/partial/full)中查找并填充可用对象至缓存。在对象分配过程中,array_cache结构体发挥了关键作用,它不仅简化了内存管理,还优化了内存使用效率。
对象释放流程与分配流程类似,涉及数组缓存的管理和slab对象的回收。在cache_alloc_refill函数中,关键操作是检查slab_partial和slab_free队列,寻找空闲的对象以供释放。整个过程确保了内存资源的高效利用,避免了资源浪费。
总结内存操作函数概览,栈与堆的区别是显而易见的。栈主要存储函数调用参数、局部变量等,而堆用于存放new出来的对象实例、全局变量、静态变量等。由于堆的动态分配特性,它无法像栈一样精准预测内存使用情况,导致内存碎片问题。为了应对这一挑战,Linux内核引入了buddy和slab等内存管理算法,以提高内存分配效率和减少碎片。
然而,即便使用了高效的内存管理算法,内存碎片问题仍难以彻底解决。在C/C++中,没有像Java那样的自动垃圾回收机制,导致程序员需要手动管理内存分配与释放。如果忘记释放内存,将导致资源泄漏,影响系统性能。为此,业界开发了如ZGC和Shenandoah等垃圾回收算法,以提高内存管理效率和减少内存碎片。
ZGC算法通过分页策略对内存进行管理,并利用“初始标记”阶段识别GC根节点(如线程栈变量、静态变量等),并查找这些节点引用的直接对象。此阶段采用“stop the world”(STW)策略暂停所有线程,确保标记过程的准确性。接着,通过“并发标记”阶段识别间接引用的对象,并利用多个GC线程与业务线程协作提高效率。在这一过程中,ZGC采用“三色标记”法和“remember set”机制来避免误回收正常引用的对象,确保内存管理的精准性。
接下来,ZGC通过“复制算法”实现内存回收,将正常引用的对象复制到新页面,将旧页面的数据擦除,从而实现内存的高效管理。此外,通过“初始转移”和“并发转移”阶段进一步优化内存管理过程。最后,在“对象重定位”阶段,完成引用关系的更新,确保内存管理过程的完整性和一致性。
通过实测,ZGC算法在各个阶段展现出高效的内存管理能力,尤其是标记阶段的效率,使得系统能够在保证性能的同时,有效地管理内存资源。总之,内存管理是系统性能的关键因素,Linux内核通过先进的算法和策略,实现了高效、灵活的内存管理,为现代操作系统提供稳定、可靠的服务。
UE4源码剖析:MallocBinned(上)
近期着手UE4项目开发,对UnrealEngine已久仰慕,终于得此机会深入探索。鉴于项目内存性能问题,决定从内存分配器着手,深入研读UE4源码。虽个人水平有限,尚不能全面理解,但愿借此机会揭开源码神秘面纱,让新手朋友们不再感到陌生。
UE4内存分配器位于硬件抽象层HAL(Hardware Abstraction Layer)中。具体装箱内存分配器代码位于VS项目目录:UE4/Source/Runtime/Core/Private/HAL/MallocBinned。
分析从ApplePlatformMemory::BaseAllocator开始,可发现Mac平台的默认分配器为MallocBinned,iOS的默认分配器为MallocAnsi。以下将重点分析MallocBinned。
一、确定对齐方式
FScopeLock用于局部线程锁,确保线程同步。关于Alignment的确定,通常使用默认值。默认值取决于内存对齐方式,此处默认对齐为8字节。
二、确定有足够空间来内存对齐
代码中,SpareBytesCount用于确认空间足够。若分配内存小于8字节,则按Alignment大小匹配箱体;若大于8字节,则按Size + Alignment - sizeof(FFreeMem)匹配箱体。
三、确定箱体大小
根据Size的大小,有三种不同的处理方式。k以下的内存分配采用装箱分配,PoolTable中包含个不同大小的池子。
四、初始化内存池
分析内存池初始化过程,主要工作包括:确定内存大小,分配内存块,设置内存池基本信息。
五、内存装箱
AllocateBlockFromPool从内存池中分配一个Block,实现内存装箱过程。