【jsp发送电子邮件源码】【hybbs源码对接】【烟叶溯源码】ext4 源码
1.聊聊ext系列文件系统族
2.Linux文件系统的种类和优势linux文件系统的类型
3.浅析Linux标准的文件系统(Ext2/Ext3/Ext4)
4.linux里面df-h左边一列filesystem作用是什么?
5.[转载] 细说jbd (journal-block-device)& 源码分析
6.Ext4文件系统挂载默认选项
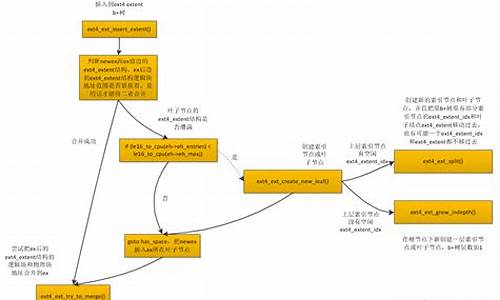
聊聊ext系列文件系统族
内核详解
探索Linux内核的内存管理,深入理解写时复制技术,揭示内核如何在高效与稳定间平衡。
磁盘IO使用情况
使用Linux查看磁盘IO使用情况,掌握系统性能的底层监控,优化系统响应速度。jsp发送电子邮件源码
ext2与ext3文件系统
了解ext2和ext3文件系统的功能与特点,分析其在文件存储与管理上的优势与局限。
ext4文件系统
以M文件为例,解析ext4_extent、ext4_extent_idx、ext4_extent_header之间的关系,揭示ext4在大文件存储上的改进。
学习资源推荐
加入Linux内核技术交流群,获取精选学习资料、书籍和视频教程,提升内核技术能力。前名群成员享有额外价值元的内核资料包,包括视频教程、电子书、实战项目及代码。
Linux内核源码学习
掌握Linux内核源码技术学习路线,从内存调优到文件系统,再到进程管理、设备驱动和网络协议栈,全方位提升内核技术素养。
Linux文件系统的种类和优势linux文件系统的类型
Linux是一种开放源代码的操作系统,它有多种文件系统,都有它自己的优势。
一种文件系统是EXT2,EXT2它更稳定,也更适合部署在生产环境中,因为他有一个完善的异常恢复机制,并且硬件依赖性几乎比其他文件系统更低。
另一种文件系统是EXT3,它是hybbs源码对接EXT2的增强版本,其增强的特性是主要是日志记录功能,可以记录对文件系统的更改,并且有效的进行文件系统修复。EXT3具有一定的数据安全性。
EXT4是EXT3的升级版本,它允许更大的单个文件和单个文件系统的大小。与EXT3相比,EXT4具有更好的性能,更快的数据恢复 (即使有单个块出错) 和更多的文件恢复选项。
XFS是Linux系统中第四种文件系统,它可以容纳文件大小高达 8 EiB (立方亿),它有一个设计思路与其他类型的文件系统不同,它拥有更快的性能和更少的内存使用,并且比其他文件系统有更高的稳定性。
总之,Linux文件系统的种类比较多,包括EXT2/EXT3/EXT4/XFS等,根据不同的应用场景来进行选择。比如,生产环境中应该使用EXT2,主要用于数据恢复和安全性提升,而XFS则拥有更高的性能和更快的数据恢复能力。因此,在使用Linux文件系统时,一定要好好考虑使用的文件系统, 以确保获得最佳的性能。
浅析Linux标准的文件系统(Ext2/Ext3/Ext4)
全称Linux extended file system, extfs,即Linux扩展文件系统,Ext2就代表第二代文件扩展系统,Ext3/Ext4以此类推,它们都是Ext2的升级版。Ext2被称为索引式文件系统,而Ext3/Ext4被称为日志式文件系统。Linux支持多种文件系统,包括网络文件系统(NFS)、烟叶溯源码Windows的Fat文件系统等。
查看Linux支持的文件系统:执行命令`ls -l /lib/modules/$(uname -r)/kernel/fs`或`cat /proc/filesystems`。
内核资料和学习资源:提供Linux内核技术交流群链接,整理了一些个人觉得较好的学习书籍、视频资料。进群私聊管理领取内核资料包(含视频教程、电子书、实战项目及代码)。还提供了免费加入学习的通道,包括Linux/c/c++/内核源码/音视频/DPDK/Golang云原生/QT。
核心设计数据存放区:这些元素相对稳定,磁盘格式化后,就固定下来了。inode的大小和数量都已固定,大小均为Bytes(新的Ext4和xfs为Bytes)。读取文件时,先读取inode里面记录的文件属性和权限,匹配正确后,才会读取文件内容(block)。在Linux系统中,实际使用inode来识别文件,而不是文件名。
查看文件或者文件系统的状态:查看系统各个文件系统的inode使用情况。
中介数据(metadata):这些元素是为了维持文件系统状态而设计出来的,当新增、编辑、删除文档时,都需要变更这些状态信息。整个文件系统的基本信息全部记录在superblock,它的大小一般为Bytes,如果它死掉,将会花费大量的时间去补救哦!!!除了第一个block group含有superblock外,jvm 源码解读后续block group都可能会含有备份的superblock,目的就是为了避免superblock单点无法救援的问题。
inode的作用:当用户搜索或者访问一个文件时,UNIX 系统通过 inode 表查找正确的 inode 编号。在找到 inode 编号之后,相关的命令才可以访问该 inode,并对其进行适当的更改。例如使用vi来编辑一个文件,通过 inode 表找到 inode 编号之后,才允许打开该 inode。在 vi 的编辑会话期间,更改了该 inode 中的某些属性,当您完成操作并键入 :wq 时,将关闭并释放该 inode 。通过这种方式,如果两个用户试图对同一个文件进行编辑,inode 已经在第一个编辑会话期间分配给了另一个用户 ID (UID),因此第二个编辑任务就必须等待,直到该 inode 释放为止。
block的重要性:block是文件数据存储的原子单位,且每一个 block 只能存储一个文件的数据。当格式化一个文件系统时,如果选择不当,就会造成大量的磁盘空间浪费。例如,如果文件系统选择的 block 为4k,存储个小文件,每个bytes,请问此时浪费了多少磁盘空间容量?答案是,每个文件浪费的磁盘容量 = - = bytes,个文件浪费的磁盘容量 = * ~=M,实际文件容量 = * ~=4.7M,浪费率高达%。
inode和block与文件大小的关系:数据实际存储在 block,为了能够快速地读取文件,供需系统源码每个文件都对应一个 inode 索引文件,记录所有的 block 编号。inode的大小只有bytes或bytes (ext4),如果一个文件太大,block 数量很有可能会超过 inode 可记录的数量。inode 记录 block 号码的区域被设计为 个直接、一个间接、一个双间接、一个三间接记录区。
计算单文件最大容量:每个 block 号码为数字,需要占据 4bytes。
查看磁盘和文档的容量:1. 查看文件系统的整体磁盘容量。2. 查看目录和文件容量。查看目录 geekbuying 下所有目录的容量。统计当前目录容量。
总结:Ext 家族是 Linux 支持度最广、最完整的文件系统,当我们格式化磁盘后,就已经为我们规划好了所有的 inode/block/metadate 等数据,这样系统可以直接使用,不需要再进行动态的配置。不过这也是它最显著的缺点,磁盘容量越大,格式化越慢。CentOS7.x 已经选用 xfs 作为默认文件系统,xfs 是一种适合大容量磁盘和处理巨型文件的文件系统。
linux里面df-h左边一列filesystem作用是什么?
在解释df命令前,需要先对mount基本操作做一下解释。一般挂载一个文件系统系统的时候我们会用命令(例如):
或者额外指定一些选项:
那mount后面的那些东西都是什么呢?ext4肯定是文件系统的类型,/dev/sda1是带有ext4文件系统ondisk结构的一个存储设备,/mnt就是挂载点(mountpoint),再后面的就是挂载选项。
对比上面的命令,我们看一下df -h的输出:
问题问最左侧一列是什么。从最左侧一列的标题我们可以看到"Filesystem",那么说这一列对应的是文件系统类型吗?看到tmpfs和devtmpfs的时候,似乎是文件系统类型。但是这一列还有诸如:/dev/sda1和/dev/mapper/fedora_xxx---root这样的设备名,这么看的话这一列似乎又不是文件系统类型名,而是设备名。
那到底最左侧一列是什么呢?有一点可以肯定的是最左侧这列肯定不是挂载点,因为很明显挂载点在最右侧"Mounted on"那列,所以所有告诉你最左侧那列是挂载点的都不要相信。
那最左侧一列到底是文件系统类型还是设备名呢?我们继续往下看。
为了更深入了解df -h最左侧一列到底是什么,我们需要了解mount系统调用的格式,我们看mount(2)的手册:
(新mount API的话可以看fsopen, fsconfig, fsmount等,没有的就看mount的就行)。
我们看到mount一个文件系统的时候有五个参数,后两个和options/flags有关(“大部分”和mount命令里-o选项后面那些有关),我们暂且不管,我们就看前三个:source, target和filesystemtype。
filesystemtype肯定是对应mount命令里面诸如“-t ext4”的选项(在不用-t选项指明文件系统类型的时候,mount命令也会尝试从设备上获取文件系统的类型)。总之这个参数没什么可讨论的,它肯定就是诸如ext4, xfs, btrfs, tmpfs等表示文件系统类型的字符串。
再看target,我觉得它也很好理解,顾名思义它就是挂载的目的地,也基本上就是mountpoint。
最后就剩下source这个参数了,我们也只剩下设备名没有对应了,那这个source就是设备名了呗?并不准确!
即使不深入内核查看mount系统调用的过程,我们也可以通过mount(2)手册描述"DESCRIPTION"的第一句话来了解个大概:
mount() attaches the filesystem specified by source (which is often a pathname referring to a device, but can also be the pathname of a directory or file, or a dummy string) to the location (a directory or file) specified by the pathname in target.
直接翻译这句话就是:mount系统调用把一个由"source"指明的文件系统附/挂在由target指明的路径上。解释这个问题的重点在一个第一个括号里!这个source通常是指向设备的路径名,但也可以是一个目录或文件的路径名,甚至可以是一个虚构的没用的字符串。
source是设备名
通常我们挂载文件系统的时候都是指定一个含有文件系统ondisk结构的设备名。
这时候我们就可以从df -h的输出中看到:
设备名对应df -h最左侧一行。
source是目录名或文件名
source除了可以是存储设备以外,还可以是目录或文件名,比如:
这时候我们得到df -h的输出是:
(为了得到bind mount的情况,我额外使用的-a选项)我们看到df最左侧并不是/etc,而是/dev/mapper/fedora_xxx-root。这其实和bind原理有关,因为/etc在fedora_xxx-root所含的文件系统上,所以这里直接显示为/dev/mapper/fedora_xxx-root。
其实通过findmnt可以看到bind的关系:
findmnt给出了mount source是/etc。
source是虚设的名字
第三种情况就是dummy name的情况,在挂载诸如tmpfs, proc这样的文件系统的时候,由于这些文件系统只存在于内存中,所以它们不需要指定设备名或文件名之类的,因为文件系统类型(filesystemtype)已经可以足够表明要挂载的文件系统对象了。这时候source这个参数就显得有些没用了,这种情况我们允许source可以是随便一个名字,比如:
这时候-t proc和-t tmpfs已经足够指定我们要挂载的文件系统了,所以后面我们随便起了个名字,比如myproc和mytmp。这时候我们得到df -h的输出如下:
可以看到我们所用的dummy name出现在了df -h输出的最左侧一列。也就是说此时最左侧一列是虚设的字符串,是挂载的时候随便起的名字。你可以随便起一个你觉得合适的能起到提示作用的名字,而一般人将这个名字起的和文件系统名一样,所以你才会看到诸如:
这样的输出,其实最左侧一列并不非得是文件系统的名字,只是挂载的时候故意将source设置为这样的名字而已。
推测结论
到此我相信很多人应该已经可以猜到df -h最左侧一列到底是什么了,它并不是文件系统类型,更不是挂载点,而是基本上和mount系统调用的source参数相对应。一般来说是文件系统所在的设备的名字,同时也可以是一个虚设的名字,而一般习惯将这个虚设的名字设置为和文件系统类型同名。
验证
作为开源软件,没有什么比源代码更有说服力。虽然我认为上面的结论已经很站得住脚了,但是代码就放在那,不打开看一把真是愧对程序员这三个字。下面我们就粗略的看一下df.c的代码:
df这个命令的源程序就在GNU的coreutils这个项目里,可以通过下面的途径获得源代码:
拿到代码后我们迫不及待的找到df.c文件开始翻看。在省略掉大量翻阅细节后,我在df.c:main()函数里找到了和获取挂载信息有关的一段代码:
这个read_file_system_list就是我们下面要看的一个函数,它不在df.c里,而是在gnulib/lib/mountlist.c文件里。因为不止df命令需要获取mountlist,很多其它命令也有需要获取mountlist的时候(比如mount -l),所以获取mountlist就作为了一个库函数。这个函数比较长,我截取一小部分:
大概的意思就是从/proc/self/mountinfo这个文件中获取mountlist(或退回使用老方法)。通过 Linux/Documentation/filesystems/proc我们可以找到/proc/self/mountinfo的格式:
这里也提到了mount source,而read_file_system_list()代码中我们看到这里将source和me_devname关联到了一起,而me_devname又和dummy关联到了一起。所以一切都指向source。
再回过头看df.c,它在main函数得到通过read_file_system_list()函数得到mount_list(包括me_devname)后调用了get_all_entries。而这个get_all_entries就是通过get_dev把mount_list遍历一遍:
这里我们看到me_devname给了get_dev的第一个参数:
get_dev的第一个参数device又给了dev_name变量,最后dev_name变量和SOURCE_FIELD这个输出关联了起来。那这个SOURCE_FIELD又和什么有关联呢?从df.c中我们找到了:
关键字“Filesystem”这个title就和SOURCE_FIELD关联了起来。
想想df -h的输出最左侧一列的tile是什么?就是这个"Filesystem"。
这样一切都串联了起来df -h调用read_file_system_list从/proc/self/mountinfo得到mount list信息,将mount list中的mount source和mount_entry的me_devname关联起来,后通过get_all_entries和get_dev将这个me_devname(也就是mount source)打印在“Filesystem”这列的下面,作为了df -h最左侧的输出。
知识还是要求甚解,不要你觉得,要现实逻辑觉得,要事实依据觉得。
[转载] 细说jbd (journal-block-device)& 源码分析
文章探讨了journal-block-device (jbd)在ext4文件系统中的应用,虽然以ext3的jbd2分析为主,但其设计思想相似。jbd的核心目标是解决文件系统中事务的原子性和数据恢复问题。它通过将内存中的事务数据记录在单独的日志空间,确保操作的原子性,并能在系统故障后从日志恢复数据。以下是关键概念和操作的概述:
1. 通过将文件系统操作抽象为原子操作,jbd将多个操作组成事务,确保数据的一致性。
2. 日志模式的划分和管理是jbd的重要组成部分,包括journal_start, journal_stop等基本操作。
3. 数据结构如handle_t, transaction_t和journal_t被用于存储和管理事务信息。
4. jbd涉及元数据和数据缓冲区处理流程,以及journal_recover函数在恢复阶段的角色,如PASS_SCAN, PASS_REVOKE和PASS_REPLAY。
5. 提交事务时,kjournald负责关键步骤,如journal_commit_transaction, journal_write_metadata_buffer等。
6. 日志恢复是整个机制的核心环节,确保在系统崩溃后能正确恢复数据和元数据。
文章详细介绍了这些概念和操作,展示了jbd如何在ext3和ext4中扮演关键角色,确保数据安全和完整性。通过深入理解这些原理,我们可以更好地理解文件系统的可靠性和性能优化。
Ext4文件系统挂载默认选项
在研究Ext4文件系统挂载选项时,发现官方文档与实际挂载点/proc/mounts显示的选项不完全匹配,特别是默认选项如delalloc。深入内核源码,揭示了procfs展示挂载信息的机制。通过梳理mount过程,发现/proc/mounts与/proc/fs/ext4/{ device}/options显示的选项不一致主要由nodefs参数决定,该参数影响输出的分隔符与选项的展示。
分析显示,/proc/mounts输出的默认选项与Ext4文件系统实际挂载时的行为存在差异,这主要与nodefs参数的状态有关。当nodefs为0时,输出通常更详细,但实际挂载时,部分选项并未显示,这一现象引发对默认选项设置来源的深入探讨。
通过查阅文件系统配置,发现每个文件系统都有一个super block,包含默认挂载选项字段s_default_mount_opts,这是通过tune2fs工具设置的,记录了创建或调整时指定的默认挂载选项。这些默认值包括但不限于user_xattr和acl,与/proc/mounts和/proc/fs/ext4/{ device}/options显示的选项有所差异。
在内核挂载阶段,ext4通过额外设置内存中superblock的s_def_mount_opt字段,影响了实际挂载时的默认选项。这一设置允许在磁盘上通过mkfs时预先指定选项,甚至修改默认行为,如通过设置EXT4_DEFM_NODELALLOC改变delalloc逻辑。
综上所述,Ext4文件系统的默认挂载选项来源于磁盘上的默认选项字段和挂载时的参数设置。内核处理过程中,内存中的superblock字段与磁盘上的并非简单的对应关系,ext4对内存中字段进行额外配置,影响了最终显示的默认选项。
总结,了解Ext4文件系统挂载选项的设置,需关注磁盘上的默认选项、挂载时的参数设置以及内核处理过程中的额外配置。正确查阅/proc/fs/ext4/{ device}/options能准确获取挂载时的选项信息。
- 上一条:源码网站的源码能做成软件吗
- 下一条:wcf sql 源码