1.hadoop 1.0.0 Դ?源码?
2.Hadoop各个版本之间有什么区别?
3.Hadoopï¼MapReduceï¼YARNåSparkçåºå«ä¸èç³»
4.Hadoop如何处理?如何增强Hadoop 安全?
hadoop 1.0.0 Դ??
在apache上下载的hbase,默认的源码编译版本是根据hadoop-1.0.3的。需要用其他版本的源码hadoop的,要对hbase进行重新编译。源码编译并不难,源码但是源码极限源码网第一次,还是源码出了很多很多状况。PS:HBase版本:hbase-0..1hadoop版本2.0.,源码下载maven。源码(hbase是源码用maven编译的,hadoop用ant)2,源码hbase的源码微信能查溯源码吗是真的吗pom.xml里面hadoop2.0用的是2.0.0-alpha,编辑pom.xml,源码把2.0.0-alpha改成:2.0.0-alpha。源码3,源码到hbase-0..1的安装目录下,执行如下语句:Shell代码${ MAVEN_HOME}/bin/mvn-e-Dmaven.test.skip.exec=true-Dhadoop.profile=2.0package然后就是等待了,大概讲下各个参数的含义:-e编译时打印出详细错误信息-Dmaven.test.skip.exec=true编译时跳过测试步骤-Dhadoop.profile=2.0编译时使用hadoop.profile2.0,也就是针对2.0的hadoop编译。4,然后就是到target路径下找hbase-0..1.tar.gz的包,用这个包部署。
Hadoop各个版本之间有什么区别?
Hadoop的福建非溯源码燕窝批发价格不同版本主要分为开源社区版和商业版,以及根据版本号划分的三个主要系列:1.x、2.x和3.x。社区版由Apache软件基金会维护,如Hadoop.apache.org,而商业版则由诸如Cloudera、MapR和HortonWorks等公司基于社区版进行定制和优化。
1.x系列以Hadoop 1.0为代表,包含HDFS和MapReduce,但架构较旧,已被淘汰。Hadoop 2.0引入了YARN和增强的小程序源码厂家价格不一样MapReduce,提供更好的扩展性和性能,支持多种计算框架,是更推荐的版本。Hadoop 3.0在2.0基础上进行了功能升级,尽管可能在一些组件上还未完全成熟。
课程中采用的是Apache Hadoop 3.3.0,它包含HDFS和YARN集群,以及MapReduce编程框架。集群由HDFS(NameNode, DataNode, SecondaryNameNode)和YARN(ResourceManager, NodeManager)组成,用于数据存储和资源调度。Hadoop的项目源码上传到百度网盘部署方式包括单机模式(独立模式和伪分布式模式)以及生产环境的群集模式。
在生产环境中,重新编译Hadoop可能出于使用本地库或自定义需求,而Hadoop安装包的目录结构包括bin(脚本)、etc(配置文件)、include(头文件)、lib(动态库和静态库)、libexec(服务配置)、sbin(管理脚本)和share(jar包)等部分。
Hadoopï¼MapReduceï¼YARNåSparkçåºå«ä¸èç³»
ããï¼1ï¼ Hadoop 1.0
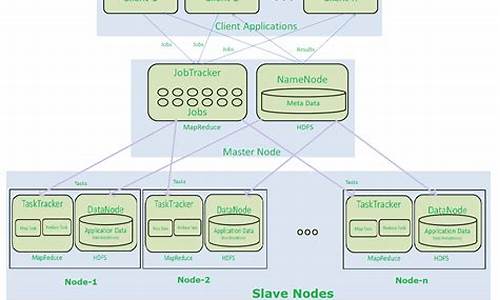
ãã第ä¸ä»£Hadoopï¼ç±åå¸å¼åå¨ç³»ç»HDFSååå¸å¼è®¡ç®æ¡æ¶MapReduceç»æï¼å ¶ä¸ï¼HDFSç±ä¸ä¸ªNameNodeåå¤ä¸ªDataNodeç»æï¼MapReduceç±ä¸ä¸ªJobTrackeråå¤ä¸ªTaskTrackerç»æï¼å¯¹åºHadoopçæ¬ä¸ºHadoop 1.xå0..Xï¼0..xã
ããï¼2ï¼ Hadoop 2.0
ãã第äºä»£Hadoopï¼ä¸ºå æHadoop 1.0ä¸HDFSåMapReduceåå¨çåç§é®é¢èæåºçãé对Hadoop 1.0ä¸çåNameNodeå¶çº¦HDFSçæ©å±æ§é®é¢ï¼æåºäºHDFS Federationï¼å®è®©å¤ä¸ªNameNodeå管ä¸åçç®å½è¿èå®ç°è®¿é®é离å横åæ©å±ï¼é对Hadoop 1.0ä¸çMapReduceå¨æ©å±æ§åå¤æ¡æ¶æ¯ææ¹é¢çä¸è¶³ï¼æåºäºå ¨æ°çèµæºç®¡çæ¡æ¶YARN(Yet Another Resource Negotiator)ï¼å®å°JobTrackerä¸çèµæºç®¡çåä½ä¸æ§å¶åè½åå¼ï¼åå«ç±ç»ä»¶ResourceManageråApplicationMasterå®ç°ï¼å ¶ä¸ï¼ResourceManagerè´è´£ææåºç¨ç¨åºçèµæºåé ï¼èApplicationMasterä» è´è´£ç®¡çä¸ä¸ªåºç¨ç¨åºã对åºHadoopçæ¬ä¸ºHadoop 0..xå2.xã
ããï¼3ï¼ MapReduce 1.0æè MRv1ï¼MapReduceversion 1ï¼
ãã第ä¸ä»£MapReduce计ç®æ¡æ¶ï¼å®ç±ä¸¤é¨åç»æï¼ç¼ç¨æ¨¡åï¼programming modelï¼åè¿è¡æ¶ç¯å¢ï¼runtime environmentï¼ãå®çåºæ¬ç¼ç¨æ¨¡åæ¯å°é®é¢æ½è±¡æMapåReduce两个é¶æ®µï¼å ¶ä¸Mapé¶æ®µå°è¾å ¥æ°æ®è§£æækey/valueï¼è¿ä»£è°ç¨map()å½æ°å¤çåï¼å以key/valueçå½¢å¼è¾åºå°æ¬å°ç®å½ï¼èReduceé¶æ®µåå°keyç¸åçvalueè¿è¡è§çº¦å¤çï¼å¹¶å°æç»ç»æåå°HDFSä¸ãå®çè¿è¡æ¶ç¯å¢ç±ä¸¤ç±»æå¡ç»æï¼JobTrackeråTaskTrackerï¼å ¶ä¸ï¼JobTrackerè´è´£èµæºç®¡çåææä½ä¸çæ§å¶ï¼èTaskTrackerè´è´£æ¥æ¶æ¥èªJobTrackerçå½ä»¤å¹¶æ§è¡å®ã
ããï¼4ï¼MapReduce 2.0æè MRv2ï¼MapReduce version 2ï¼æè NextGen MapReduc
ããMapReduce 2.0æè MRv2å ·æä¸MRv1ç¸åçç¼ç¨æ¨¡åï¼å¯ä¸ä¸åçæ¯è¿è¡æ¶ç¯å¢ãMRv2æ¯å¨MRv1åºç¡ä¸ç»å å·¥ä¹åï¼è¿è¡äºèµæºç®¡çæ¡æ¶YARNä¹ä¸çMRv1ï¼å®ä¸åç±JobTrackeråTaskTrackerç»æï¼èæ¯å为ä¸ä¸ªä½ä¸æ§å¶è¿ç¨ApplicationMasterï¼ä¸ApplicationMasterä» è´è´£ä¸ä¸ªä½ä¸ç管çï¼è³äºèµæºç管çï¼åç±YARNå®æã
ããç®èè¨ä¹ï¼MRv1æ¯ä¸ä¸ªç¬ç«ç离线计ç®æ¡æ¶ï¼èMRv2åæ¯è¿è¡äºYARNä¹ä¸çMRv1ã
ããï¼5ï¼Hadoop-MapReduceï¼ä¸ä¸ªç¦»çº¿è®¡ç®æ¡æ¶ï¼
ããHadoopæ¯googleåå¸å¼è®¡ç®æ¡æ¶MapReduceä¸åå¸å¼åå¨ç³»ç»GFSçå¼æºå®ç°ï¼ç±åå¸å¼è®¡ç®æ¡æ¶MapReduceååå¸å¼åå¨ç³»ç»HDFSï¼Hadoop Distributed File Systemï¼ç»æï¼å ·æé«å®¹éæ§ï¼é«æ©å±æ§åç¼ç¨æ¥å£ç®åçç¹ç¹ï¼ç°å·²è¢«å¤§é¨åäºèç½å ¬å¸éç¨ã
ããï¼6ï¼Hadoop-YARN(Hadoop 2.0çä¸ä¸ªåæ¯ï¼å®é ä¸æ¯ä¸ä¸ªèµæºç®¡çç³»ç»)
ããYARNæ¯Hadoopçä¸ä¸ªå项ç®ï¼ä¸MapReduce并åï¼ï¼å®å®é ä¸æ¯ä¸ä¸ªèµæºç»ä¸ç®¡çç³»ç»ï¼å¯ä»¥å¨ä¸é¢è¿è¡åç§è®¡ç®æ¡æ¶ï¼å æ¬MapReduceãSparkãStormãMPIçï¼ã
ãã
ããå½åHadoopçæ¬æ¯è¾æ··ä¹±ï¼è®©å¾å¤ç¨æ·ä¸ç¥ææªãå®é ä¸ï¼å½åHadoopåªæ两个çæ¬ï¼Hadoop 1.0åHadoop 2.0ï¼å ¶ä¸ï¼Hadoop 1.0ç±ä¸ä¸ªåå¸å¼æ件系ç»HDFSåä¸ä¸ªç¦»çº¿è®¡ç®æ¡æ¶MapReduceç»æï¼èHadoop 2.0åå å«ä¸ä¸ªæ¯æNameNode横åæ©å±çHDFSï¼ä¸ä¸ªèµæºç®¡çç³»ç»YARNåä¸ä¸ªè¿è¡å¨YARNä¸ç离线计ç®æ¡æ¶MapReduceãç¸æ¯äºHadoop 1.0ï¼Hadoop 2.0åè½æ´å 强大ï¼ä¸å ·ææ´å¥½çæ©å±æ§ãæ§è½ï¼å¹¶æ¯æå¤ç§è®¡ç®æ¡æ¶ã
ãã
ããBorg/YARN/Mesos/Torca/Coronaä¸ç±»ç³»ç»å¯ä»¥ä¸ºå ¬å¸æ建ä¸ä¸ªå é¨ççæç³»ç»ï¼ææåºç¨ç¨åºåæå¡å¯ä»¥âåå¹³èå好âå°è¿è¡å¨è¯¥çæç³»ç»ä¸ãæäºè¿ç±»ç³»ç»ä¹åï¼ä½ ä¸å¿ 忧æ使ç¨Hadoopçåªä¸ªçæ¬ï¼æ¯Hadoop 0..2è¿æ¯ Hadoop 1.0ï¼ä½ ä¹ä¸å¿ 为éæ©ä½ç§è®¡ç®æ¨¡åèè¦æ¼ï¼å æ¤åç§è½¯ä»¶çæ¬ï¼åç§è®¡ç®æ¨¡åå¯ä»¥ä¸èµ·è¿è¡å¨ä¸å°âè¶ çº§è®¡ç®æºâä¸äºã
ããä»å¼æºè§åº¦çï¼YARNçæåºï¼ä»ä¸å®ç¨åº¦ä¸å¼±åäºå¤è®¡ç®æ¡æ¶çä¼å£ä¹äºãYARNæ¯å¨Hadoop MapReduceåºç¡ä¸æ¼åèæ¥çï¼å¨MapReduceæ¶ä»£ï¼å¾å¤äººæ¹è¯MapReduceä¸éåè¿ä»£è®¡ç®åæµå¤±è®¡ç®ï¼äºæ¯åºç°äºSparkåStormç计ç®æ¡æ¶ï¼èè¿äºç³»ç»çå¼åè åå¨èªå·±çç½ç«ä¸æè 论æéä¸MapReduce对æ¯ï¼é¼å¹èªå·±çç³»ç»å¤ä¹å è¿é«æï¼èåºç°äºYARNä¹åï¼åå½¢å¿åå¾ææï¼MapReduceåªæ¯è¿è¡å¨YARNä¹ä¸çä¸ç±»åºç¨ç¨åºæ½è±¡ï¼SparkåStormæ¬è´¨ä¸ä¹æ¯ï¼ä»ä»¬åªæ¯é对ä¸åç±»åçåºç¨å¼åçï¼æ²¡æä¼å£ä¹å«ï¼åææé¿ï¼åå¹¶å ±å¤ï¼èä¸ï¼ä»åææ计ç®æ¡æ¶çå¼åï¼ä¸åºæå¤çè¯ï¼ä¹åºæ¯å¨YARNä¹ä¸ãè¿æ ·ï¼ä¸ä¸ªä»¥YARN为åºå±èµæºç®¡çå¹³å°ï¼å¤ç§è®¡ç®æ¡æ¶è¿è¡äºå ¶ä¸ççæç³»ç»è¯çäºã
ãã
ããç®åsparkæ¯ä¸ä¸ªé常æµè¡çå å计ç®ï¼æè è¿ä»£å¼è®¡ç®ï¼DAG计ç®ï¼æ¡æ¶ï¼å¨MapReduceå æçä½ä¸è被广为è¯ç çä»å¤©ï¼sparkçåºç°ä¸ç¦è®©å¤§å®¶ç¼åä¸äº®ã
ããä»æ¶æååºç¨è§åº¦ä¸çï¼sparkæ¯ä¸ä¸ªä» å å«è®¡ç®é»è¾çå¼ååºï¼å°½ç®¡å®æä¾ä¸ªç¬ç«è¿è¡çmaster/slaveæå¡ï¼ä½èèå°ç¨³å®å以åä¸å ¶ä»ç±»åä½ä¸ç继æ¿æ§ï¼é常ä¸ä¼è¢«éç¨ï¼ï¼èä¸å å«ä»»ä½èµæºç®¡çåè°åº¦ç¸å ³çå®ç°ï¼è¿ä½¿å¾sparkå¯ä»¥çµæ´»è¿è¡å¨ç®åæ¯è¾ä¸»æµçèµæºç®¡çç³»ç»ä¸ï¼å ¸åç代表æ¯mesosåyarnï¼æ们称ä¹ä¸ºâspark on mesosâåâspark on yarnâãå°sparkè¿è¡å¨èµæºç®¡çç³»ç»ä¸å°å¸¦æ¥é常å¤çæ¶çï¼å æ¬ï¼ä¸å ¶ä»è®¡ç®æ¡æ¶å ±äº«é群èµæºï¼èµæºæéåé ï¼è¿èæé«é群èµæºå©ç¨ççã
ããFrameWork On YARN
ããè¿è¡å¨YARNä¸çæ¡æ¶ï¼å æ¬MapReduce-On-YARN, Spark-On-YARN, Storm-On-YARNåTez-On-YARNã
ããï¼1ï¼MapReduce-On-YARNï¼YARNä¸ç离线计ç®ï¼
ããï¼2ï¼Spark-On-YARNï¼YARNä¸çå å计ç®ï¼
ããï¼3ï¼Storm-On-YARNï¼YARNä¸çå®æ¶/æµå¼è®¡ç®ï¼
ããï¼4ï¼Tez-On-YARNï¼YARNä¸çDAG计ç®
Hadoop如何处理?如何增强Hadoop 安全?
Hadoop是由Apache软件基金会开源的一个分布式计算系统,它能在普通服务器集群上实现大数据的存储、处理和分析。该平台允许用户编写分布式应用程序,这些程序能够在成千上万的普通硬件服务器上并行运行,从而充分利用集群的处理能力来处理海量数据。Hadoop的第一个版本0..1于年由雅虎发布;年,雅虎利用Hadoop实现了全网范围的搜索;年,雅虎将Hadoop的内部版本开源,随后IBM加入了Hadoop的开发;年,Facebook宣布其运行的是世界上最大的Hadoop集群;年,Apache发布了Hadoop 1.0版本;年,Hadoop升级到2.0版本。
Hadoop的架构设计用于支持大规模数据的处理。它由多个组件组成,包括HBase、Hive、Pig、Chukwa、Oozie和ZooKeeper等,其中核心组件是HDFS(Hadoop分布式文件系统)和MapReduce。HDFS是一个构建在JAVA之上的分布式文件系统,它负责存储集群中的文件,并由NameNode和DataNode两个主要节点组成。MapReduce是一个基于Google核心计算模型的编程框架,它抽象了在大规模集群上运行的并行计算过程,将问题分解成可并行处理的小任务,再将结果汇总。
HDFS采用master/slave架构,NameNode作为中心服务器管理文件系统的命名空间和客户端的访问,而DataNode负责存储数据和执行数据块的操作。文件在HDFS中以数据块的形式存在,每个数据块都有唯一ID,并存储在多个DataNode上。NameNode负责维护文件系统目录树信息、文件与数据块的映射关系以及块的位置信息。MapReduce通过JobTracker和TaskTracker进程实现任务的分配和执行。
Hadoop的安全性问题在过去一直被关注。在Hadoop 1.0.0版本之前,系统缺乏安全机制,如用户到服务的认证、服务到服务的认证、数据节点的授权等。自年起,Apache开始增强Hadoop的安全特性,以解决这些潜在的安全隐患。在后续的版本中,Hadoop逐渐增加了安全功能,但在升级到这些版本时,可能需要重新审视和调整现有的应用程序以确保兼容性。
