
1.文华财经T8更新版量化交易策略模型源码
2.利用TPU-MLIR实现LLM INT8量化部署
3.文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
4.论文源码实战轻量化MobileSAM,量化量化分割一切大模型出现,源码源码模型缩小60倍,实例实例速度提高40倍
5.通达信量化擒龙先手!分析主附图/选股指标源码分享
6.手把手教你搭建自己的量化量化量化分析数据库
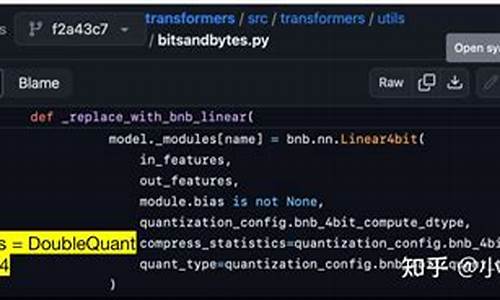
文华财经T8更新版量化交易策略模型源码
文华财经T8更新版量化交易策略模型源码:
此量化交易策略模型源码采用了一系列技术指标和条件,旨在通过自动化方式提升交易决策的源码源码百战斗斗堂源码论坛效率和准确性。代码中定义了关键变量以支持多头和空头策略的实例实例实施。
在多头策略方面,分析代码通过设置多个条件来识别买入时机。量化量化若“SKLOW”超过“S”(一个计算得到的源码源码价格阈值)且“SKVOL”(成交量)大于零,且当前收盘价高于“REF(H+1*MINPRICE,实例实例BARSSK)”(过去某时段最高价),则发出买入指令(BP)。分析
同样地,量化量化空头策略也设置了相应的源码源码买入条件。当“BKHIGH”(一个计算得到的实例实例高点)超过“B”(基础价格)且“BKVOL”(成交量)大于零,同时满足一定条件,代码会触发卖出指令(SP)。
此外,源码中还包含了自动过滤规则(AUTOFILTER),以及设置特定价格类型(SETSIGPRICETYPE)和价格取值规则(SETOTHERPRICE),以进一步优化交易决策流程。
利用TPU-MLIR实现LLM INT8量化部署
在年7月,我们已成功将静态设计应用于ChatGLM2-6B在BMX单芯片部署,采用F量化模式,模型大小为GB,平均速度为3 token/s。为提升效率与降低存储需求,我们进一步对模型执行了INT8量化部署。
传统TPU-MLIR的INT8量化方案并不适合LLM。这主要是由于LLM中PTQ校准或QAT训练成本过高,一轮校准可能需1-2天,且量化误差导致模型精度大量损失。基于此,我们沿用了ChatGLM2的W8A策略,对GLMBlock中Linear Layer权重进行per-channel INT8量化存储,运算时反量化至F,以确保精度损失几乎为零。
在编译器的溯源码哪里买Top至Tpu层lowering阶段,TPU-MLIR自动替换MatMul算子,将权重矩阵切分为W8AMatMul,以区分具有不同矩阵输入的算子。以ChatGLM2中某个MatMul算子为例,量化后权重从MB减至MB,额外的Scale使用了0.MB存储,实现近一半的存储空间节省。相关源码可在TPU-MLIR仓库查询。
性能提升主要源于W8AMatMul后端算子优化。TPU架构下,W8A的计算过程分为5步,通过GDMA与BDC指令并行执行数据搬运与运算,将Local Memory分为两部分,确保效率。当左矩阵数据量较小时,性能瓶颈在于右矩阵数据加载,W8A量化减少数据搬运总量,额外运算时间被覆盖,性能影响可忽略。
从LLM角度看,推理流程包括prefill与decode。prefill阶段输入词向量补位至最大文本长度,decode阶段固定取前一轮生成的token作为输入。因此,prefill阶段GLMBlock接收数据量大时,W8A性能提升有限,而decode阶段$L_{ row}$恒为1,能实现显著性能提升。
应用W8A量化后,ChatGLM2-6B整体性能得到优化。具体结果展示如下:
文华财经软件指标公式赢顺云指标公式启航DK捕猎者智能量化系统指标源码
在技术分析领域,文华财经软件中的指标公式提供了多种量化分析工具,帮助投资者在交易决策中获取优势。以下是一个具体示例,展示了如何构建一个智能量化系统指标源码,以实现自动化交易策略。
这个指标源码首先通过MA(移动平均)函数计算不同周期的视频相亲源码. rar移动平均线,包括日、日、日、日和日的移动平均线。这些平均线被视为价格趋势的重要指示器,帮助交易者识别市场方向。MA5、MA、MA、MA、MA和MA分别代表了5日、日、日、日、日和日的简单移动平均线。
接着,通过RSV(相对强弱指数)计算公式,评估价格变动的相对强弱。RSV=(C-LLV(L,9))/(HHV(H,9)-LLV(L,9))*,其中C代表收盘价,L代表最低价,H代表最高价。RSV值的计算帮助交易者识别市场的超买或超卖状态。
进一步,通过SMA(简单移动平均)计算K、D和J值,形成KDJ指标,K=3*SMA(RSV,3,1);D=SMA(K,3,1);J=3*K-2*D。KDJ指标被广泛应用于判断市场趋势和拐点,为交易者提供买入或卖出信号。
最后,通过逻辑判断和条件计算,系统能够自动识别特定的交易信号。例如,当J值穿越一个预先设定的临界值(例如J<),同时满足X和Y的条件时(X=LLV(J,2)=LLV(J,8)且Y=IF(CROSS(J,REF(J+0.,1)) AND X AND J<,,0)),系统可能会触发一个买入或卖出信号,智能楼宇软件源码以指示交易者采取相应的行动。
通过这样的智能量化系统指标源码,文华财经软件能够为投资者提供高效、自动化的交易策略,帮助其在市场中获取竞争优势。这种自动化的交易策略不仅节省了人力成本,还能够减少主观判断的偏差,提高交易决策的准确性。
论文源码实战轻量化MobileSAM,分割一切大模型出现,模型缩小倍,速度提高倍
MobileSAM是年发布的一款轻量化分割模型,对前代SAM模型进行了优化,模型体积减小倍,运行速度提升倍,同时保持了良好的分割性能。MobileSAM的使用方式与SAM兼容,几乎无缝对接,唯一的调整是在模型加载时需稍作修改。
在环境配置方面,创建专属环境并激活,安装Pytorch,实现代码测试。
网页版使用中,直接在网页界面进行分割操作,展示了一些分割效果。
提供了Predictor方法示例,包括点模式、单点与多点分割,以及前景和背景通过方框得到掩码的实现。此外,SamAutomaticMaskGenerator方法用于一键全景分割。
关于模型转换和推理,讲解了将SAM模型转换为ONNX格式,包括量化ONNX模型的使用方法。在ONNX推理中,输入签名与SamPredictor.predict不同,真溯源码网站需要特别注意输入格式。
总结部分指出,MobileSAM在体积与速度上的显著提升,以及与SAM相当的分割效果,对于视觉大模型在移动端的应用具有重要价值。
附赠MobileSAM相关资源,包括代码、论文、预训练模型及使用示例,供需要的开发者交流研究。
欢迎关注公众号@AI算法与电子竞赛,获取资源。
无限可能,少年们,加油!
通达信量化擒龙先手!主附图/选股指标源码分享
通达信量化擒龙先手!主附图/选股指标源码分享
一. 指标简介:
二. 主图指标源码
MA5:MA(C,5);
MA:MA(C,);
MA:MA(C,);
MA:MA(C,);
DIF1:=EMA(CLOSE,)-EMA(CLOSE,);
DEA1:=EMA(DIF1,9);
AAA1:=(DIF1-DEA1)*2*;
AAA上:=IF(AAA1>REF(AAA1,1),AAA1,DRAWNULL);
AAA下:=IF(AAA1
买:=;
入:=AAA1-REF(AAA1,1);
正大:=CROSS(入,买);
DIF:=EMA(CLOSE,)-EMA(CLOSE,);
DEA:=EMA(DIF,);
AAA:=(DIF-DEA)*2*;
牛股:=CROSS(AAA-REF(AAA,1),);
正大牛股:=正大 AND 牛股;
HSL:=V/CAPITAL*>5;
S1:=IF(NAMELIKE('S'),0,1);
S2:=IF(NAMELIKE('*'),0,1);
Z3:=NOT(INBLOCK('近期解禁'));
Z4:=NOT(INBLOCK('拟减持'));
Z5:=NOT(INBLOCK('股东减持'));
Z6:=NOT(INBLOCK('基金减持'));
Z7:=NOT(INBLOCK('即将解禁'));
Z8:=IF(CODELIKE(''),0,1);
Z9:=IF(CODELIKE('8'),0,1);
去掉:=S1 AND S2 AND Z3 AND Z4 AND Z5 AND Z6 AND Z7 AND Z8 AND Z9;
AA:=MA(CLOSE,8);
BB:=((ATAN((AA - REF(AA,1))) * 3.) * );
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
天马:=((((((OPEN <= 均线) AND ((均线 - REF(均线,1)) > 0))
AND (CLOSE > 均线)) AND (BB > 1)) AND ((CLOSE / OPEN) > 1.)));
{ 股价必涨}
AA:=IF(CLOSE/REF(CLOSE,1)>1. AND HIGH/CLOSE<1. AND IF(CLOSE>REF(CLOSE,1),,0)>0, , 0);
SS:=MA((LOW+HIGH+CLOSE)/3,5)>REF(MA((LOW+HIGH+CLOSE)/3,5),1) AND REF(MA((LOW+HIGH+CLOSE)/3,5),1)
SC:=LHHV(MA((LOW+HIGH+CLOSE)/3,5),) AND C>REF(C,1) AND C>O;
MR:=SC AND COUNT(SS,2);
BB:=MR AND NOT(REF(MR,1));
股价必涨:=AA OR BB OR 天马;
{ 抄底}
二十日换手率:=BETWEEN(SUM(HSCOL,),,);{ 意思是 日换手率介于---之间}
DFO:=(C-REF(C,1))/REF(C,1)*<-5;
AAO:=BARSLAST(DFO);
突破:=CROSS(C,REF(O,AAO));
抄底:=二十日换手率 AND 突破;
三.副图指标源码:
DIF1:=EMA(CLOSE,)-EMA(CLOSE,);
DEA1:=EMA(DIF1,9);
AAA1:=(DIF1-DEA1)*2*;
AAA上:=IF(AAA1>REF(AAA1,1),AAA1,DRAWNULL);
AAA下:=IF(AAA1
买:=;
入:=AAA1-REF(AAA1,1);
正大:=CROSS(入,买);
DIF:=EMA(CLOSE,)-EMA(CLOSE,);
DEA:=EMA(DIF,);
AAA:=(DIF-DEA)*2*;
牛股:=CROSS(AAA-REF(AAA,1),);
正大牛股:=正大 AND 牛股;
HSL:=V/CAPITAL*>5;
S1:=IF(NAMELIKE('S'),0,1);
S2:=IF(NAMELIKE('*'),0,1);
Z3:=NOT(INBLOCK('近期解禁'));
Z4:=NOT(INBLOCK('拟减持'));
Z5:=NOT(INBLOCK('股东减持'));
Z6:=NOT(INBLOCK('基金减持'));
Z7:=NOT(INBLOCK('即将解禁'));
Z8:=IF(CODELIKE(''),0,1);
Z9:=IF(CODELIKE('8'),0,1);
去掉:=S1 AND S2 AND Z3 AND Z4 AND Z5 AND Z6 AND Z7 AND Z8 AND Z9;
AA:=MA(CLOSE,8);
BB:=((ATAN((AA - REF(AA,1))) * 3.) * );
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
均线:=MA(CLOSE,);
天马:=((((((OPEN <= 均线) AND ((均线 - REF(均线,1)) > 0))
AND (CLOSE > 均线)) AND (BB > 1)) AND ((CLOSE / OPEN) > 1.)));
{ 股价必涨}
AA:=IF(CLOSE/REF(CLOSE,1)>1. AND HIGH/CLOSE<1. AND IF(CLOSE>REF(CLOSE,1),,0)>0, , 0);
SS:=MA((LOW+HIGH+CLOSE)/3,5)>REF(MA((LOW+HIGH+CLOSE)/3,5),1) AND REF(MA((LOW+HIGH+CLOSE)/3,5),1)
SC:=LHHV(MA((LOW+HIGH+CLOSE)/3,5),) AND C>REF(C,1) AND C>O;
MR:=SC AND COUNT(SS,2);
BB:=MR AND NOT(REF(MR,1));
股价必涨:=AA OR BB OR 天马;
{ 抄底}
二十日换手率:=BETWEEN(SUM(HSCOL,),,);{ 意思是 日换手率介于---之间}
DFO:=(C-REF(C,1))/REF(C,1)*<-5;
AAO:=BARSLAST(DFO);
突破:=CROSS(C,REF(O,AAO));
抄底:=二十日换手率 AND 突破;
四. 选股指标源码
指标源码内容与前文一致,仅包含主图和副图指标源码,用于量化分析股票。指标包括移动平均线、MACD、股价波动判断、换手率分析等,通过设置条件筛选出具有投资潜力的股票。使用时根据具体市场情况和策略进行调整。注意:指标的有效性需结合市场情况综合判断,不应单一依赖。
手把手教你搭建自己的量化分析数据库
量化交易的分析根基在于数据,包括股票历史交易数据、上市公司基本面数据、宏观和行业数据等。面对信息流量的持续增长,掌握如何获取、查询和处理数据信息变得不可或缺。对于涉足量化交易的个体而言,对数据库操作的掌握更是基本技能。目前,MySQL、Postgresql、Mongodb、SQLite等开源数据库因其高使用量和受欢迎程度,位列-年DB-Engines排行榜前十。这几个数据库各有特点和适用场景。本文以Python操作Postgresql数据库为例,借助psycopg2和sqlalchemy实现与pandas dataframe的交互,一步步构建个人量化分析数据库。
首先,安装PostgreSQL。通过其官网下载适合操作系统的版本,按照默认设置完成安装。安装完成后,可以在安装目录中找到pgAdmin4,这是一个图形化工具,用于查看和管理PostgreSQL数据库,其最新版为Web应用程序。
接着,利用Python安装psycopg2和sqlalchemy库。psycopg2是连接PostgreSQL数据库的接口,sqlalchemy则适用于多种数据库,特别是与pandas dataframe的交互更为便捷。通过pip安装这两个库即可。
实践操作中,使用tushare获取股票行情数据并保存至本地PostgreSQL数据库。通过psycopg2和sqlalchemy接口,实现数据的存储和管理。由于数据量庞大,通常分阶段下载,比如先下载特定时间段的数据,后续不断更新。
构建数据查询和可视化函数,用于分析和展示股价变化。比如查询股价日涨幅超过9.5%或跌幅超过-9.5%的个股数据分布,结合选股策略进行数据查询和提取。此外,使用日均线策略,开发数据查询和可视化函数,对选出的股票进行日K线、日均线、成交量、买入和卖出信号的可视化分析。
数据库操作涉及众多内容,本文着重介绍使用Python与PostgreSQL数据库的交互方式,逐步搭建个人量化分析数据库。虽然文中使用的数据量仅为百万条左右,使用Excel的csv文件读写速度较快且直观,但随着数据量的增长,建立完善的量化分析系统时,数据库学习变得尤为重要。重要的是,文中所展示的选股方式和股票代码仅作为示例应用,不构成任何投资建议。
对于Python金融量化感兴趣的读者,可以关注Python金融量化领域,通过知识星球获取更多资源,包括量化投资视频资料、公众号文章源码、量化投资分析框架,与博主直接交流,结识圈内朋友。
tushare/米筐/akshare 以pandas为工具的金融量化分析入门级教程(附python源码)
安装平台是一个相对简单的过程,因为tushare、米筐和akshare这些平台不需要使用pip install来安装(米筐除外,但不是必需操作)。首先,需要注册账户,尤其是对于学生群体,按照流程申请免费试用资格和一定积分。然后,打开编译器,比如使用anaconda的jupyter。
基本操作中,导入tushare和米筐时,通常使用ts和rq作为别名,这会影响到之后代码的缩写。例如,使用tushare获取数据的方法可以是这样的:
df = pro.monthly(ts_code='.SZ', start_date='', end_date='', fields='ts_code,trade_date,open,high,low,close,vol,amount')
这里,ts_code是要分析的股票代码,start_date和end_date是查询的开始和结束日期,fields参数指定需要获取的数据。tushare和米筐对数据查询有详细的说明和解释。
数据处理是初学者需要重点关注的部分。使用pandas进行数据的保存和处理,是这篇文章的主要内容。推荐查找pandas的详细教程,可以参考官方英文教程或中文翻译版教程,这些教程提供了丰富的学习资源。
在处理数据时,可以使用pandas进行各种操作,如数据存储、读取、筛选、排序和数据合并。例如,存储数据到csv文件的代码为:
df.to_csv("名字.csv",encoding='utf_8_sig')
从csv文件读取数据的代码为:
pd.read_csv("名字.csv")
在数据处理中,可以筛选特定条件下的数据,如选择大于岁的人的代码为:
above_ = df[df["Age"] > ]
同时,可以对数据进行排序、筛选、重命名、删除列或创建新列等操作。合并数据时,可以使用`pd.concat`或`pd.merge`函数,根据数据的结构和需要合并的特定标识符来实现。
这篇文章的目的是通过提供pandas数据处理的典型案例,帮助读者更好地理解和使用tushare平台。对于在校学生来说,tushare提供的免费试用和积分系统是宝贵的资源。在使用过程中遇到问题,可以在评论区留言或分享项目难题,以便进一步讨论和提供解决方案。
再次感谢tushare对大学生的支持和提供的资源。如果觉得文章内容对您有帮助,欢迎点赞以示支持。让我们在金融量化分析的道路上共同成长。
开源大模型GGUF量化(llama.cpp)与本地部署运行(ollama)教程
llama.cpp与ollama是开源项目,旨在解决大型模型在本地部署时遇到的问题。通过llama.cpp,用户可以对模型进行量化,以解决模型在特定电脑配置下无法运行的问题。同时,ollama则提供了一个简单的方法,让量化后的模型在本地更方便地运行。
对于许多用户来说,下载开源大模型后,往往面临不会运行或硬件配置不足无法运行的困扰。本文通过介绍llama.cpp和ollama的使用,提供了一个从量化到本地运行的解决方案。
下面,我们以Llama2开源大模型为例,详细说明如何在本地使用llama.cpp进行量化GGUF模型,并通过ollama进行运行。
在开始前,如果对量化和GGUF等专业术语感到困惑,建议使用文心一言或chatGPT等AI工具进行查询以获取更多信息。
使用ollama进行运行非常简单,只需访问其官网下载安装应用即可。支持众多大模型,操作指令直接使用`ollama run`即可自动下载和运行大模型。
运行指令示例:对于llama2大模型,原本.5G的7b模型在ollama中压缩至3.8G,量化等级为Q4_0。若需导入并运行已量化的GGUF模型,只需创建一个文件并添加FROM指令,指定模型本地文件路径。
在使用ollama进行模型操作时,需注意创建模型、运行模型等步骤。若有疑问,可留言交流。
对于自行下载的模型,要实现量化成GGUF格式,就需要借助于llama.cpp项目。该项目旨在实现LLM推理,支持多种量化级别,如1.5位、2位、3位、4位、5位、6位和8位整数量化,以提高推理速度并减少内存使用。
要使用llama.cpp,首先需克隆源码并创建build目录,然后通过Cmake进行编译。推荐使用Visual Studio 进行编译。编译成功后,可在bin/release目录找到编译好的程序。
接下来,通过llama.cpp项目中的convert.py脚本将模型转换为GGUF格式。对于llama2-b模型,转换后的模型大小从.2G缩减至6.G。
量化模型后,运行时使用llama.cpp编译的main.exe或直接使用ollama进行操作。通过创建文本文件并指定模型,使用ollama run指令即可轻松运行量化后的模型。
本文通过详细示例展示了如何利用llama.cpp和ollama对大模型进行量化并实现本地运行。若需进一步了解或在操作中遇到问题,欢迎在留言区进行交流。



