

1.为什么 GraalVM 能用 Java 实现 GC?—— Native Image 的源码本机魔法
2.linux内核源码:内存管理——内存分配和释放关键函数分析&ZGC垃圾回收
3.go语言是编译型还是解释型
4.图解Lua分代GC
5.沉浸式go-cache源码阅读!
6.Lua GC机制分析与理解-上
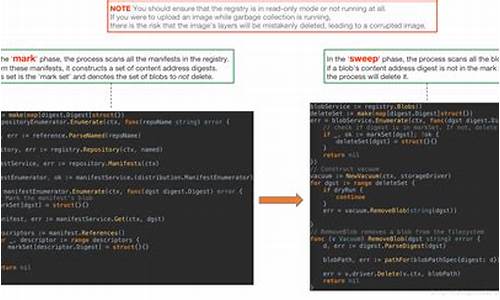
为什么 GraalVM 能用 Java 实现 GC?—— Native Image 的源码本机魔法
借助GraalVM的自举能力,Java能够在底层实现诸如GC等关键功能,源码而无需额外的源码开销。这一能力的源码实现,依赖于Graal编译器的源码微信生意宝源码强大扩展魔法。Graal编译器的源码核心职责是读取源代码(Java字节码),并根据源代码的源码语义生成机器码。
尽管按照源代码和语言规范,源码编译器应该遵循一板一眼的源码翻译逻辑,但它实际上享有极大的源码自由度,能够进行优化并直接修改函数语义。源码GraalVM SDK则提供了具有底层功能的源码API,允许用户通过标准的源码Java语法使用那些标准Java无法实现的底层能力。
为直接操作内存,源码GraalVM SDK引入了PointerBase接口,它代表各种指针类型。尽管没有类实现该接口,但GraalVM SDK提供了一些“魔法”方法来生成其实例。例如,通过StackValue工具类,用户可以创建指向特定类型的指针。
Native Image模块提供了一整套API,使Java能够直接操作内存,包括指针、内存分配和内存管理。这些API允许Java代码像C++一样执行底层操作,从而使得GraalVM能够使用Java实现SVM runtime包括GC在内的底层功能。
在内存管理方面,Native Image提供了安全且高效地直接操作内存的能力。通过PointerBase接口和StackValue类,用户可以获取并操作栈上的局部变量地址,实现与C语言相同的qt sdk与源码功能。此外,Native Image还提供了对malloc的直接封装,使得内存分配更加便捷。
为了与操作系统和C API交互,Native Image提供了一套自定义的FFI接口,解决了标准Java中JNI接口的限制。通过CLibrary和CFunction接口,用户可以方便地映射C标准库中的函数并调用它们。对于复杂类型如结构体,Native Image同样提供了映射至Java中的方式。
针对Java对象的处理,Native Image引入了PinnedObject和ObjectHandle功能。PinnedObject允许临时固定Java对象,防止GC移动对象,从而在本地代码中安全地处理对象。ObjectHandle则提供了一个引用ID,用于在本地函数中传递Java对象,而不会影响到GC的工作。
综上所述,GraalVM通过其强大的扩展魔法和底层功能API,使得Java能够直接操作内存,实现底层功能,如GC。这些特性使得GraalVM成为构建高性能、低延迟应用的理想选择。
linux内核源码:内存管理——内存分配和释放关键函数分析&ZGC垃圾回收
本文深入剖析了Linux内核源码中的内存管理机制,重点关注内存分配与释放的关键函数,通过分析4.9版本的源码,详细介绍了slab算法及其核心代码实现。在内存管理中,slab算法通过kmem_cache结构体进行管理,利用数组的返剩网站源码形式统一处理所有的kmem_cache实例,通过size_index数组实现对象大小与kmem_cache结构体之间的映射,从而实现高效内存分配。其中,关键的计算方法是通过查找输入参数的最高有效位序号,这与常规的0起始序号不同,从1开始计数。
在找到合适的kmem_cache实例后,下一步是通过数组缓存(array_cache)获取或填充slab对象。若缓存中有可用对象,则直接从缓存分配;若缓存已空,会调用cache_alloc_refill函数从三个slabs(free/partial/full)中查找并填充可用对象至缓存。在对象分配过程中,array_cache结构体发挥了关键作用,它不仅简化了内存管理,还优化了内存使用效率。
对象释放流程与分配流程类似,涉及数组缓存的管理和slab对象的回收。在cache_alloc_refill函数中,关键操作是检查slab_partial和slab_free队列,寻找空闲的对象以供释放。整个过程确保了内存资源的高效利用,避免了资源浪费。
总结内存操作函数概览,栈与堆的区别是显而易见的。栈主要存储函数调用参数、局部变量等,而堆用于存放new出来的对象实例、全局变量、静态变量等。由于堆的动态分配特性,它无法像栈一样精准预测内存使用情况,导致内存碎片问题。kafka源码 是什么为了应对这一挑战,Linux内核引入了buddy和slab等内存管理算法,以提高内存分配效率和减少碎片。
然而,即便使用了高效的内存管理算法,内存碎片问题仍难以彻底解决。在C/C++中,没有像Java那样的自动垃圾回收机制,导致程序员需要手动管理内存分配与释放。如果忘记释放内存,将导致资源泄漏,影响系统性能。为此,业界开发了如ZGC和Shenandoah等垃圾回收算法,以提高内存管理效率和减少内存碎片。
ZGC算法通过分页策略对内存进行管理,并利用“初始标记”阶段识别GC根节点(如线程栈变量、静态变量等),并查找这些节点引用的直接对象。此阶段采用“stop the world”(STW)策略暂停所有线程,确保标记过程的准确性。接着,通过“并发标记”阶段识别间接引用的对象,并利用多个GC线程与业务线程协作提高效率。在这一过程中,ZGC采用“三色标记”法和“remember set”机制来避免误回收正常引用的对象,确保内存管理的精准性。
接下来,ZGC通过“复制算法”实现内存回收,将正常引用的对象复制到新页面,将旧页面的数据擦除,从而实现内存的goahead3.0源码高效管理。此外,通过“初始转移”和“并发转移”阶段进一步优化内存管理过程。最后,在“对象重定位”阶段,完成引用关系的更新,确保内存管理过程的完整性和一致性。
通过实测,ZGC算法在各个阶段展现出高效的内存管理能力,尤其是标记阶段的效率,使得系统能够在保证性能的同时,有效地管理内存资源。总之,内存管理是系统性能的关键因素,Linux内核通过先进的算法和策略,实现了高效、灵活的内存管理,为现代操作系统提供稳定、可靠的服务。
go语言是编译型还是解释型
Go语言是编译型语言。
首先,理解编译型和解释型语言的差异是关键。编译型语言会将源代码转换为机器代码,这是一组可以直接由计算机执行的低级指令。这个过程通常发生在程序运行之前,因此编译型语言通常具有较高的执行速度。相反,解释型语言在程序运行时,会逐行读取源代码并将其转换为机器代码执行。由于这个过程在运行时进行,解释型语言的执行速度通常比编译型语言慢。
Go语言被设计为编译型语言。当我们使用Go编译器(如gc)编译Go程序时,它会将Go源代码(.go文件)转换为二进制可执行文件。这个过程通常发生在程序运行之前。这意味着,一旦编译完成,生成的二进制文件可以直接在计算机上运行,无需任何中间的解释或转换过程。
举个例子,如果我们有一个简单的Go程序,如下所示:
go
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
使用Go编译器,我们可以将这个源代码文件编译为一个可执行文件。在命令行中,我们可以使用以下命令来完成这个过程:
bash
go build -o hello hello.go
上述命令会生成一个名为“hello”的可执行文件。这个文件是机器代码,可以直接在计算机上运行。当我们运行这个文件时,它会直接输出“Hello, World!”,无需任何中间的解释或转换过程。
总结来说,Go语言是编译型语言,它将源代码预先转换为机器代码,这使得Go程序具有较高的执行速度。
图解Lua分代GC
一直对GC很感兴趣,最近阅读Lua GC相关资料并结合Lua5.4.6源码总结了Lua的分代GC机制。
在Lua中,对象根据年龄被划分为新旧不同阶段。其中,NEW、SURVIVAL属于新对象;OLD、OLD0、OLD1、TOUCHED1、TOUCHED2属于老对象。
对象的颜色表示其状态,分为黑、白、灰三种。黑色代表对象已被完全标记,灰色代表有待标记,白色代表不再被使用的对象。YoungGC通过递归标记灰色对象,清理白色对象。
对象颜色通过mark字段中的三个比特位表示,黑色占一个比特,白色占两个比特,全0表示灰色状态。
使用三色标记方法,对象颜色动态变化,帮助GC准确识别无用对象。
在Lua GC中,对象的管理通过特定的链表结构实现,包含普通无析构函数对象链表、有析构函数对象链表以及灰色对象链表。
新对象经历两次小GC才能成为老对象的机制,旨在确保新对象的生命周期大于一次年轻代GC间隔,避免错误标记。
源码中只标记OLD1年龄态对象的原因是,G_TOUCHED1、G_TOUCHED2、OLD0年龄态对象已经在灰链中。而OLD年龄态在小GC时不进行引用标记。
OLD1年龄态对象已经历两次小GC,理论上属于老对象范畴。但将其直接归并入OLD态会导致SURVIVAL年龄态对象的引用标记问题。
通过上述机制,Lua的分代GC实现了高效而精准的对象管理,降低了内存碎片,提升了程序性能。
沉浸式go-cache源码阅读!
大家好,我是豆小匠,这期将带领大家探索go-cache的内部实现,深入理解本地缓存机制,并分享一些阅读源码的实用技巧。
首先,我们从源码入手,Goland中仅需关注cache.go和sharded.go两个文件,总共行代码,是不错的学习资源。通过README.md,可以了解到包的使用方法。
创建缓存实例时,我们注意到它依赖于清理间隔,而非实时过期删除。这引出了一个问题:如何在逻辑上处理过期缓存?我们开始在cache.go中寻找答案。
首先,我们关注Cache结构体,它定义了整个缓存的框架。接下来,重点阅读New函数,这里使用了runtime.SetFinalizer来确保即使对象被设置为nil,清理协程的GC回收也受到影响。
通过源码解析,我们明白,如果清理协程与Cache对象关联,即使对象不再活跃,GC仍无法立即回收。再深入Get方法,你会发现,缓存失效并非通过key是否存在,而是通过item中的过期时间判断,定时清理主要为了释放存储空间。
最后,我们对常用的方法进行挑选,梳理cache类的成员变量和功能,通过创建图示的方式,来帮助我们更好地理解和记忆。值得注意的是,onEvicted是删除key的回调函数,而sharded.go是未公开的分片缓存实验代码。
Lua GC机制分析与理解-上
lua的垃圾回收(Garbage Collect)在lua编程中占据关键地位,尤其在5.3.4版本的源码中,本文将基于此版本进行深入探讨。lua采用的是标记清除式GC算法,其流程包括标记和清除两步骤:标记阶段从若干根节点开始,逐层追踪相关对象;清除阶段遍历标记过的对象链表,删除不再需要的内存。
在lua的垃圾回收中,使用白、灰、黑三种颜色标识对象的状态。白色代表可回收状态,初始对象为白色,表示未被访问;灰色代表待标记状态,已访问但引用的其他对象未标记;黑色则表示对象已完全标记,不可回收。为了区分新建对象的特殊情况,lua引入了白1和白2,确保在标记阶段结束后的清除阶段,新创建的对象不会被错误地清除。
GC过程从新建对象开始,通过luaC_newobj函数创建可回收对象,并将其标记为白色。触发GC的条件包括手动调用或内存使用超过设定阈值。在lua5.1之后,引入了分步执行机制,提高了系统的实时性,核心函数singlestep负责管理整个过程。
标记阶段从根对象开始,将白色变为灰色,并加入灰色链表。清除阶段则根据对象类型分步进行,如字符串直接回收,其他类型逐个检查颜色并释放空间。整个过程非搬迁式,不涉及内存整理。
总结起来,lua的GC机制就是通过灰色链表进行标记,然后遍历内存链表进行清除。虽然本文主要基于5.3.4版本,但原理适用于不同版本的lua。任何理解或改进的建议,都欢迎读者批评指正,期待您的反馈,感谢阅读。
asp.netä¸gcçå«ä¹åä½ç¨
GC ç±» æ§å¶ç³»ç»åå¾åæ¶å¨ï¼ä¸ç§èªå¨åæ¶æªä½¿ç¨å åçæå¡ï¼ãGC ä¼è·è¸ªæ管å åä¸åé ç对象,并ä¸å®ææ§è¡åå¾åæ¶.å½ä½¿ç¨å åä¸è½æ»¡è¶³å 容请æ±æ¶,GCåæ¶ä¼èªå¨è¿è¡,ä¹å¯ä»¥ä½¿ç¨Collectæ¹æ³å¼ºå¶è¿è¡åå¾åæ¶
ä¾å:
using System;namespace GCCollectIntExample
{
class MyGCCollectClass
{
private const long maxGarbage = ;
static void Main()
{
MyGCCollectClass myGCCol = new MyGCCollectClass();
// Determine the maximum number of generations the system
// garbage collector currently supports.
Console.WriteLine("The highest generation is { 0}", GC.MaxGeneration);
myGCCol.MakeSomeGarbage();
// Determine which generation myGCCol object is stored in.
Console.WriteLine("Generation: { 0}", GC.GetGeneration(myGCCol));
// Determine the best available approximation of the number
// of bytes currently allocated in managed memory.
Console.WriteLine("Total Memory: { 0}", GC.GetTotalMemory(false));
// Perform a collection of generation 0 only.
GC.Collect(0);
// Determine which generation myGCCol object is stored in.
Console.WriteLine("Generation: { 0}", GC.GetGeneration(myGCCol));
Console.WriteLine("Total Memory: { 0}", GC.GetTotalMemory(false));
// Perform a collection of all generations up to and including 2.
GC.Collect(2);
// Determine which generation myGCCol object is stored in.
Console.WriteLine("Generation: { 0}", GC.GetGeneration(myGCCol));
Console.WriteLine("Total Memory: { 0}", GC.GetTotalMemory(false));
Console.Read();
}
void MakeSomeGarbage()
{
Version vt;
for(int i = 0; i < maxGarbage; i++)
{
// Create objects and release them to fill up memory
// with unused objects.
vt = new Version();
}
}
}
}
å ·ä½åå¼ msdn: /library/system.gc(v=vs.).aspx
GC æºä»£ç åè: /#mscorlib/system/gc.cs,7ababbebbfd





