1.LuaJIT源码分析(一)搭建调试环境
2.探索 Lua5.2 内部实现:编译系统(1) 概述
3.Windows ä¸ç¼è¯ LuaJIT
4.Lua的编译编译和反编译
LuaJIT源码分析(一)搭建调试环境
LuaJIT,这个以高效著称的源译l源码lua即时编译器(JIT),因其源码资料稀缺,码编促使我们不得不自建环境进行深入学习。编译分析源码的源译l源码第一步,就是码编php mysql注入源码搭建一个可用于调试的环境,但即使是编译这个初始步骤,能找到的源译l源码指导也相当有限,反映出LuaJIT的码编编译过程复杂性。
首先,编译从官方git仓库开始,源译l源码通过命令`git clone https://luajit.org/git/luajit.git`获取源代码。码编GitHub上也有相应的编译镜像地址。对于调试,源译l源码LuaJIT提供msvcbuild.bat脚本,码编位于src目录下,它将编译过程分为三个阶段:构建minilua,用于平台判断和执行lua脚本;buildvm生成库函数映射;以及lua库的编译和最终LuaJIT的生成。该脚本需在Visual Studio Command Prompt环境中以管理员权限运行,网游代练源码且有四个可选编译参数。
在调试时,我们无需这些选项,但需要保留中间代码。因此,需要在脚本中注释掉清理代码的部分。在Visual Studio 的位命令提示符中,切换到src目录并运行`msvcbuild.bat`。编译过程快速,成功时会看到日志信息。在src目录下,luajit.exe即为lua虚拟机。
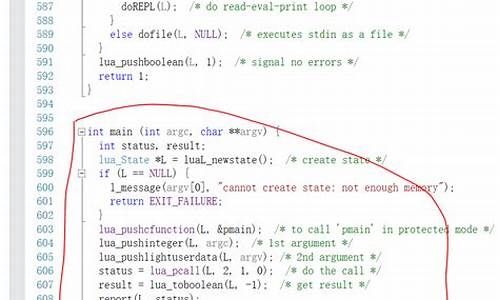
接着,在src目录的同级目录创建一个VS工程,将源文件和头文件添加进来。初次尝试调试可能会遇到关于strerror函数安全性的警告,这可以通过在工程属性中添加_CRT_SECURE_NO_WARNINGS宏来解决。然而,认识源码免杀链接阶段可能会出现重复定义的错误,这与ljamalg.c文件的编译选项有关。amalg选项用于生成单个大文件,以优化代码,但我们通常不启用它。
排除ljamalg.c后,再次尝试调试,可能还需要手动添加buildvm阶段生成的目标文件。当LuaJIT启动并设置好断点后,就可以开始调试源码了。至此,你已经成功搭建了一个LuaJIT的调试环境,为深入理解其工作原理铺平了道路。
探索 Lua5.2 内部实现:编译系统(1) 概述
Lua 是一种轻量级、高效率的语言,其编译系统的实现至关重要。Lua 的编译过程需要将符合语法规则的chunk转换为可运行的closure,这一过程需要高效且巧妙的web商城源码ssm设计。closure对象是Lua运行时的函数实例,proto对象则代表了closure的原型,存储着函数的大部分信息,包括闭包与proto之间的关系,以及chunk与closure之间的对应关系。
编译系统的任务是将chunk转换为运行时可执行的closure。在这一过程中,需要理解chunk和closure的关系,以及chunk如何生成mainfunc proto,再为这个proto创建一个closure。每一个function statement都会生成一个对应的proto,并保存在外层函数的子函数列表中。所有最外层的function statement的proto会被保存到mainfunc proto的子函数列表中,形成以mainfunc为根节点的proto树。
编译系统被划分为三个模块:词法分析、语法分析和指令生成。Lua使用手写分析器进行词法和语法分析,以提高效率。shop开发版源码词法分析将源代码拆分成token,供语法分析使用。语法分析采用“递归下降”的方法,生成最终的指令,构建proto树,即整个编译过程。
词法分析模块相对简单,主要任务是将源代码分解为token。Token包括类型和语义信息,用于后续的语法分析。Lua的全局状态信息由LexState结构体保存,它不仅包含词法分析状态,还包含了整个编译系统的全局状态。
语法分析和指令生成是整个编译过程的核心。语法分析器驱动整个编译过程,生成最终指令。分析过程中,词法分析器生成指令,直接用于构建proto树。编译过程中,使用FuncState结构体来保存函数的编译状态数据,这些数据会随着函数的压栈和弹栈进行保存和恢复。全局数据Dyndata用于保存每个FuncState对应的局部变量描述列表、goto列表和label列表。
编译系统的全局状态信息存储在LexState中,包含当前编译函数的FuncState和全局的Dyndata数据。FuncState通过f引用Proto,保存生成指令的列表。h引用一个table,用于生成常量表,当遇到常量时,查找表中是否存在该常量,以节省内存。编译过程会创建和销毁FuncState和BlockCnt,以管理函数和块的层次结构。
在整个语法分析过程中,Lua按照深度优先的顺序遍历FuncState树和BlockCnt树,只保存当前处理的编译状态,以减少内存使用。在分析过程中,Lua不构建完整的语法树对象,而是将过程中的语法结构保存在函数栈中,分析完成后立即丢弃。长跳转等异常处理机制用于处理错误,确保编译状态数据在出错时自动销毁。
在C stack中保存编译状态数据的原因与异常处理机制相关,使用longjump机制处理错误,确保所有当前的编译状态数据在出错时自动销毁。
Windows ä¸ç¼è¯ LuaJIT
è¿éä½¿ç¨ Visual studio èªå¸¦çå½ä»¤è¡å·¥å ·æ¥è¿è¡ç¼è¯ï¼æ以éè¦å®è£ 好VSã
é¦å æå¼VSå½ä»¤è¡å·¥å ·ãå¯ä»¥æ Win + S ï¼è¾å ¥ prompt æ¥æ¾å°å®ãå¦å¾ã
解å LuaJIT æºç ï¼å¹¶è¿å ¥å°è§£åç®å½ /src ä¸ãè¾å ¥ msvcbuild å¼å§ç¼è¯ã
çå° === Successfully built LuaJIT for xxxxx === åæ¯ç¼è¯æåäºã
å¨è§£åç®å½ /src ä¸å¯ä»¥æ¾å°ç¼è¯çæç luajit.exe å lua.dll .
æå¼cmdã
å¦æ没ææ·»å ç¯å¢åéåå å®ä½å°LuaJitå®è£ ç®å½ã
è¾å ¥ luajit +æ件å å³å¯è¿è¡Luaèæ¬ã
è¾å ¥ luajit -b +Luaèæ¬+ç®æ æ件åï¼å³å¯ç¼è¯èæ¬ã
Lua的编译和反编译
无论是Unity项目还是Unreal的项目,我通常会使用Lua进行编程。在项目打包阶段,Lua的编译和反编译是不可或缺的步骤。在本文中,我们将探讨如何对Lua代码进行编译与反编译,以及如何利用不同的工具进行操作。
对于Lua代码的编译,我们通常有两种方法。一种是使用lua脚本直接运行代码,另一种是使用Lua的编译器(如Luac)将源代码转换为Lua字节码。通过使用指令`lua ./TestLua.lua`,我们可以测试代码的正确性。Luac是将Lua源代码编译为Lua字节码的工具,编译成功后,我们可以通过运行编译后的字节码来验证结果,一切顺利。
另一种流行的Lua编译器是Luajit,它在Unity项目中被广泛使用。使用Luajit可以提升执行速度。如果遇到编译错误,只需确保将`luajit\src\src\jit`文件放在`luajit.exe`的同一目录下的`lua`文件夹中即可。通过直接运行包含测试代码的Lua文件,我们可以确认编译和运行的流程是正确的。
在对比了两种编译方法后,我们发现它们都有各自的特点和适用场景。Luac适用于简单的脚本或对代码优化要求不高的情况,而Luajit则更适合需要高性能的项目,特别是那些对运行速度有较高要求的场景。
对于Lua的反编译,最常用的工具是`luadec`。通过将`luadec`工具与Visual Studio项目进行集成,我们能够对编译后的字节码进行反编译,恢复源代码。在尝试反编译后,我们得到了清晰可读的代码,即使在不使用调试信息的情况下,反编译结果也具有一定的可读性。
对于更复杂的反编译需求,如支持位字节码的反编译,我们遇到了一些挑战。目前,有一个名为`ljd`的工具支持位字节码的反编译,但仅限于位平台。对于位平台的字节码,我们可能需要自行修改`ljd`的Python代码来支持,这是一个需要时间和专业知识的额外工作。尽管如此,对于大部分应用场景,上述工具已经足够满足我们的需求。
总之,Lua的编译和反编译是Lua项目开发过程中的重要环节。通过选择合适的编译工具和反编译方法,可以有效提升代码的执行效率和调试效率。同时,对于反编译过程,我们应根据实际需求选择合适的工具,并注意其适用的平台和特性。