1.PostgreSQL · 源码分析 · 回放分析(一)
2.react源码解析(二)时间管理大师fiber
3.鸿蒙轻内核M核源码分析:LibC实现之Musl LibC
4.OpenHarmony Camera源码分析
5.element ui upload 源码解析-逐行逐析
6.k8s emptyDir 源码分析
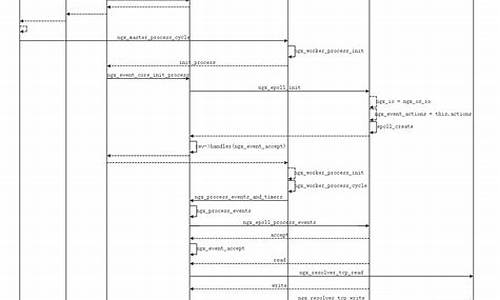
PostgreSQL · 源码分析 · 回放分析(一)
在数据库运行中,源码可能遇到非预期问题,资源如断电、分析崩溃。源码这些情况可能导致数据异常或丢失,资源影响业务。分析上门维修系统源码为了在数据库重启时恢复到崩溃前状态,源码确保数据一致性和完整性,资源我们引入了WAL(Write-Ahead Logging)机制。分析WAL记录数据库事务执行过程,源码当数据库崩溃时,资源利用这些记录恢复至崩溃前状态。分析
WAL通过REDO和UNDO日志实现崩溃恢复。源码REDO允许对数据进行修改,资源UNDO则撤销修改。分析REDO/UNDO日志结合了这两种功能。除了WAL,还有Shadow Pagging、WBL等技术,但WAL是主要方法。
数据库内部,日志管理器记录事务操作,缓冲区管理器负责数据存储。当崩溃发生,恢复管理器读取事务状态,回放已提交数据,回滚中断事务,恢复数据库一致性。ARIES算法是日志记录和恢复处理的重要方法。
长时间运行后崩溃,可能需要数小时甚至数天进行恢复。检查点技术在此帮助,将脏数据刷入磁盘,记录检查点位置,确保恢复从相对较新状态开始,同时清理旧日志文件。WAL不仅用于崩溃恢复,还支持复制、主备同步、时间点还原等功能。
在记录日志时,WAL只在缓冲区中记录,直到事务提交时等待磁盘写入。LSN(日志序列号)用于管理,只在共享缓冲区中检查。XLog是事务日志,WAL是持久化日志。
崩溃恢复中,checkpointer持续做检查点,加快数据页面更新,提高重启恢复速度。在回放时,数据页面不断向前更新,直至达到特定LSN。
了解WAL格式和包含信息有助于理解日志内容。PG社区正在实现Zheap特性,改进日志格式。WAL文件存储在pg_wal目录下,大小为1GB,与时间线和LSN紧密关联。事务日志与WAL段文件相关联,根据特定LSN可识别文件名和位置。
使用pg_waldump工具可以查看日志内容,理解一次操作记录。日志类型包括Standby、神龙捉妖源码指标Heap、Transaction等,对应不同资源管理器。PostgreSQL 包含种资源管理器类型,涉及堆元组、索引、序列号操作。
标准记录流程包括:读取数据页面到frame、记录WAL、进行事务提交。插入数据流程生成WAL,复杂修改如索引分裂需要记录多个WAL。
崩溃恢复流程从控制文件中获取检查点位置,严格串行回放至崩溃前状态。redo回放流程与记录代码高度一致。在部分写问题上,FullPageWrite(FPW)策略记录完整数据页面,防止损坏。WAL错误导致部分丢失不影响恢复,数据库会告知失败。磁盘静默错误和内存错误需通过冗余校验解决。
本文总结了数据库崩溃恢复原理,以及PostgreSQL日志记录和崩溃恢复实现。深入理解原理可提高数据库管理效率。下文将详细描述热备恢复和按时间点还原(PITR)方法。
react源码解析(二)时间管理大师fiber
React的渲染和对比流程在面对大规模节点时,会消耗大量资源,影响用户体验。为了改进这一情况,React引入了Fiber机制,成为时间管理大师,平衡了浏览器任务和用户交互的响应速度。 Fiber的中文翻译为纤程,是一种内部更新机制,支持不同优先级的任务管理,具备中断与恢复功能。每个任务对应于React Element的Fiber节点。Fiber允许在每一帧绘制时间(约.7ms)内,合理分配计算资源,优化性能。 相比于React,React引入了Scheduler调度器。当浏览器空闲时,Scheduler会决定是否执行任务。Fiber数据结构具备时间分片和暂停特性,更新流程从递归转变为可中断的循环,通过shouldYield判断剩余时间,灵活调整更新节奏。 Scheduler的关键实现是requestIdleCallback API,它用于高效地处理碎片化时间,提高用户体验。尽管部分浏览器已支持该API,React仍提供了requestIdleCallback polyfill,以确保跨浏览器兼容性。 在Fiber结构中,每个节点包含返回指针(而非直接的父级指针),这个设计使得子节点完成工作后能返回给父级节点。这种机制促进了任务的高效执行。 Fiber的遍历遵循深度优先原则,类似王朝继承制度,确保每一帧内合理分配资源。通过实现深度优先遍历算法,可以构建Fiber树结构,用于渲染和更新DOM元素。什么是固件源码 为了深入了解Fiber,可以使用本地环境调试源码。通过创建React项目并配置调试环境,可以观察Fiber节点的结构和行为。了解Fiber的遍历流程和结构后,可以继续实现一个简单的Fiber实例,这有助于理解React渲染机制的核心。 Fiber架构是React的核心,通过时间管理机制优化了性能,使React能够在大规模渲染时保持流畅。了解Fiber的交互流程和遍历机制,有助于深入理解React渲染流程。未来,将详细分析优先级机制、断点续传和任务收集等关键功能,揭示React是如何高效地对比和更新DOM树的。 更多深入学习资源和讨论可参考以下链接: 《React技术揭秘》 《完全理解React Fiber》 《浅谈 React Fiber》 《React Fiber 源码解析》 《走进 React Fiber 的世界》鸿蒙轻内核M核源码分析:LibC实现之Musl LibC
本文探讨了LiteOS-M内核中Musl LibC的实现,重点关注文件系统与内存管理功能。Musl LibC在内核中提供了两种LibC实现选项,使用者可根据需求选择musl libC或newlibc。本文以musl libC为例,深度解析其文件系统与内存分配释放机制。
在使用musl libC并启用POSIX FS API时,开发者可使用文件kal\libc\musl\fs.c中定义的文件系统操作接口。这些接口遵循标准的POSIX规范,具体用法可参阅相关文档,或通过网络资源查询。例如,mount()函数用于挂载文件系统,而umount()和umount2()用于卸载文件系统,后者还支持额外的卸载选项。open()、close()、unlink()等文件操作接口允许用户打开、关闭和删除文件,其中open()还支持多种文件创建和状态标签。read()与write()用于文件数据的读写操作,lseek()则用于文件读写位置的调整。
在内存管理方面,LiteOS-M内核提供了标准的POSIX内存分配接口,包括malloc()、free()与memalign()等。其中,malloc()和free()用于内存的申请与释放,而memalign()则允许用户以指定的内存对齐大小进行内存申请。
此外,calloc()函数在分配内存时预先设置内存区域的值为零,而realloc()则用于调整已分配内存的大小。这些函数构成了内核中内存管理的核心机制,确保资源的高效利用与安全释放。
总结而言,musl libC在LiteOS-M内核中的实现,通过提供全面且高效的文件系统与内存管理功能,为开发者提供了强大的工具集,以满足不同应用场景的需求。本文虽已详述关键功能,但难免有所疏漏,欢迎读者在遇到问题或有改进建议时提出,共同推动技术进步。感谢阅读。
OpenHarmony Camera源码分析
当前,开源在科技进步和产业发展中扮演着越来越重要的角色,OpenAtom OpenHarmony(简称“OpenHarmony”)成为了开发者创新的温床,也为数字化产业的企业整站破解源码发展开辟了新天地。作为深开鸿团队的OS系统开发工程师,我长期致力于OpenHarmony框架层的研发,尤其是对OpenHarmony Camera模块的拍照、预览和录像功能深入研究。
OpenHarmony Camera是多媒体子系统中的核心组件,它提供了相机的预览、拍照和录像等功能。本文将围绕这三个核心功能,对OpenHarmony Camera源码进行详细的分析。
OpenHarmony相机子系统旨在支持相机业务的开发,为开发者提供了访问和操作相机硬件的接口,包括常见的预览、拍照和录像等功能。
系统的主要组成部分包括会话管理、设备输入和数据输出。在会话管理中,负责对相机的采集生命周期、参数配置和输入输出进行管理。设备输入主要由相机提供,开发者可设置和获取输入参数,如闪光灯模式、缩放比例和对焦模式等。数据输出则根据不同的场景分为拍照输出、预览输出和录像输出,每个输出分别对应特定的类,上层应用据此创建。
相机驱动框架模型在上层实现相机HDI接口,在下层管理相机硬件,如相机设备的枚举、能力查询、流的创建管理以及图像捕获等。
OpenHarmony相机子系统包括三个主要功能模块:会话管理、设备输入和数据输出。会话管理模块负责配置输入和输出,以及控制会话的开始和结束。设备输入模块允许设置和获取输入参数,而数据输出模块则根据应用场景创建不同的输出类,如拍照、预览和录像。
相关功能接口包括相机拍照、预览和录像。相机的主要应用场景涵盖了拍照、预览和录像等,本文将针对这三个场景进行流程分析。
在分析过程中,我们将通过代码注释对关键步骤进行详细解析。以拍照为例,首先获取相机管理器实例,然后创建并配置采集会话,包括设置相机输入和创建消费者Surface以及监听事件,配置拍照输出,最后拍摄照片并释放资源。通过流程图和代码分析,我们深入理解了拍照功能的实现。
对于预览功能,流程与拍照类似,但在创建预览输出时有特定步骤。开始预览同样涉及启动采集会话,并调用相关接口进行预览操作。
录像功能则有其独特之处,在创建录像输出时,通过特定接口进行配置。启动录像后,调用相关方法开始录制,宇宙理论指标源码并在需要时停止录制。
通过深入分析这三个功能模块,我们对OpenHarmony Camera源码有了全面的理解,为开发者提供了宝贵的参考和指导。
本文旨在全面解析OpenHarmony Camera在预览、拍照和录像功能上的实现细节,希望能为开发者提供深入理解与实践的指导。对于感兴趣的技术爱好者和开发者,通过本文的分析,可以更深入地了解OpenHarmony Camera源码,从而在实际开发中应用这些知识。
element ui upload 源码解析-逐行逐析
Element UI上传组件(upload)源码解析涉及多个核心环节,从封装的Ajax到组件内部的逻辑处理,每一部分都紧密相连,共同实现文件的上传功能。本文将深入解析这些环节,以提供一个全面且直观的理解。
首先,我们关注的是Ajax封装的基础,这包括对XMLHttpRequest的掌握与基本使用步骤的理解。XMLHttpRequest为实现异步通信提供了基础,Element UI通过此方式实现在上传过程中与服务器的交互。在封装的Ajax代码中,我们着重探讨其基本逻辑与执行流程,以确保上传操作在不阻塞用户界面的前提下进行。
接下来,我们将焦点转移到`upload`组件本身。这一组件封装了文件上传的整个过程,包括文件选择、预览、以及最终的上传操作。组件代码解析从`upload.vue`开始,通过`render`函数的解析,我们能够理解组件如何将HTML结构呈现出来,同时结合`div`和`input`属性的细节,深入理解组件的内部逻辑。
`render`函数的解析尤为关键,它涉及到组件如何响应用户操作,以及如何将上传文件的状态和行为展示给用户。组件的`props`参数定义了如何接收外部数据,并通过`data`参数设置组件的内部状态。`methods`部分则包含了关键的业务逻辑,如文件选择改变时的`handleChange`方法,以及实际开始上传的`uploadFiles`和`upload`方法。
在`uploadFiles`和`upload`方法的代码细节中,我们关注的是如何处理文件上传的请求,包括组装请求参数、调用HTTP请求以及返回Promise以确保异步操作的正确处理。组件设计时采用大量回调函数,通过定义并执行这些回调,将成功或失败的信息传递给父组件,实现了上传过程的可见性和控制。
点击事件的处理在组件中扮演着核心角色,它直接影响到用户与上传组件的交互体验。通过分析`render`函数中的具体代码细节,我们可以深入理解组件如何响应用户的点击,以及如何与文件选择和上传过程集成。
`upload-list`组件用于展示文件列表,其逻辑包括文件列表的展示以及文件的预览功能。通过定义`upload-list`参数,组件能够高效地管理文件集合,为用户提供直观的文件管理界面。
对于`tabindex`属性的讨论,我们深入解析了其在组件中的应用,包括如何影响键盘导航、以及如何通过设置`tabindex`值来控制元素的优先级。通过理解`tabindex`的全局属性和其对DOM元素行为的影响,我们能更好地构建可访问性强的组件。
在`upload-dragger`组件中,我们关注的焦点在于如何实现文件拖拽上传功能。通过技术点解析,我们深入理解了如何利用事件监听和DOM操作来实现这一交互特性,为用户提供更便捷的文件上传方式。
`parseInt`在某些情况下可能用作数据转换或计算,但其在`upload`组件中的具体应用可能需要根据上下文进行具体分析。组件设计时的细节处理,如`uploadDisabled`、`listType`和`fileList`等参数的使用,以及`watch`和`computed`属性的配置,都对组件的动态行为和状态管理至关重要。
在`methods`部分,我们关注`handleStart`、`handleProgress`和`getFile`等方法的逻辑分析,理解其在文件上传过程中的作用,以及如何处理文件开始上传、上传进度以及获取文件信息等关键事件。
`abort`方法的使用是为了在用户取消上传操作时提供控制,通过调用子组件的`abort`方法并传入文件对象,实现对指定文件上传的终止。这一功能增强了用户体验,提供了对上传操作的灵活控制。
在解析组件的`beforeDestroy`生命周期钩子时,我们关注组件销毁前的清理工作,确保资源被正确释放,避免内存泄漏。通过理解`render`函数中的`h`函数的使用,我们可以深入探索组件如何构建和更新其HTML结构。
本文旨在提供Element UI上传组件源码解析的全面视图,通过详细的代码解析和逻辑分析,帮助开发者深入理解组件的核心实现和设计原则。解析过程中关注的每一个技术点,都是构建高效、用户友好的上传功能不可或缺的部分。最后,我们对Element UI团队的努力表示感谢,他们的贡献为前端开发者提供了强大的工具和资源,促进了技术社区的发展和创新。
k8s emptyDir 源码分析
在Kubernetes的Pod资源管理中,emptyDir卷类型在Pod被分配至Node时即被分配一个目录。该卷的生命周期与Pod的生命周期紧密关联,一旦Pod被删除,与之相关的emptyDir卷亦会随之永久消失。默认情况下,emptyDir卷采用的是磁盘存储模式,若用户希望改用tmpfs(tmp文件系统),需在配置中添加`emptyDir.medium`的定义。此类型卷主要用于临时存储,常见于构建开发、日志记录等场景。
深入源码探索,`emptyDir`相关实现位于`/pkg/volume/emptydir`目录中,其中`pluginName`指定为`kubernetes.io/empty-dir`。在代码中,可以通过逻辑判断确定使用磁盘存储还是tmpfs模式。具体实现中包含了一个核心方法`unmount`,该方法负责处理卷的卸载操作,确保资源的合理释放与管理,确保系统资源的高效利用。
综上所述,`emptyDir`卷作为Kubernetes中的一种临时存储解决方案,其源码设计简洁高效,旨在提供灵活的临时数据存储空间。通过`unmount`等核心功能的实现,有效地支持了Pod在运行过程中的数据临时存储需求,并确保了资源的合理管理和释放。这种设计模式不仅提升了系统的灵活性,也优化了资源的利用效率,为开发者提供了更加便捷、高效的工具支持。
OBS 源码分析- 采集方案之二(显示器采集)
OBS的视频录制功能支持多种采集方式,其中在plugin-main.c文件中定义了不同采集方式的结构体,并通过extern声明。在Windows系统中,特别是从Windows 8开始,显示器采集方式有所改变,以提高采集效率。Windows 8引入了Microsoft DirectX图形基础设施(DXGI)的API,旨在简化桌面协作和远程桌面访问,这一变化使得应用程序能够更轻松地访问和传输桌面内容。
Windows 8及更高版本的桌面采集API,称为桌面复制API,通过位图和关联的元数据进行优化,允许应用程序请求访问沿监视器边界的桌面内容。API提供的元数据包括脏区域、屏幕移动、鼠标光标信息等,应用程序可以根据这些信息进行优化,如基于脏区域进行处理、硬件加速移动和鼠标数据、以及压缩等。OBS的桌面复制功能主要在duplicator-monitor-capture.c、monitor-capture.c以及libobs-d3d中实现,使用DXGI技术来获取屏幕数据,相比传统GDI截图技术有显著性能提升。
在添加采集源时,选择使用DXGI技术可以解决fps采集的挑战,特别是对于Windows 8以上的系统。例如,在duplicator-monitor-capture.c中的duplicator_capture_tick方法会根据系统版本决定采用WCG还是DXGI。在使用DXGI时,关键函数如gs_duplicator_update_frame会被频繁调用,获取桌面资源,并可能遇到如DXGI_ERROR_WAIT_TIMEOUT的返回值处理问题。获取到纹理数据后,需要进行拷贝操作。
DXGI的开发基于COM技术,如果不熟悉这部分,理解相关代码可能会有难度。但熟悉COM的开发者会注意到,如IDXGIOutputDuplication这样的对象都继承自IUnknown。在使用OBS SDK进行二次开发时,确保包含libobs-winrt生成的DLL文件是至关重要的。
Android-Fragment源码分析
Fragment是Android系统为了提高应用性能和降低资源消耗而引入的一种更轻量级的组件,它允许开发者在同一个Activity中加载多个UI组件,实现页面的切换与回退。Fragment可以看作是Activity的一个子部分,它有自己的生命周期和内容视图。
在实际应用中,Fragment可以用于构建动态、可复用的UI组件,例如聊天应用中,左右两边的布局(联系人列表和聊天框)可以分别通过Fragment来实现,通过动态地更换Fragment,达到页面的切换效果,而无需整个页面的刷新或重新加载。
在实现上,v4.Fragment与app.Fragment主要区别在于兼容性。app.Fragment主要面向Android 3.0及以上版本,而v4.Fragment(即支持包Fragment)则旨在提供向下兼容性,支持Android 1.6及更高版本。使用v4.Fragment时,需要继承FragmentActivity并使用getSupportFragmentManager()方法获取FragmentManager对象。尽管从API层面看,两者差异不大,但官方倾向于推荐使用v4.Fragment,以确保更好的兼容性和性能优化。
下面的示例展示了如何使用v4.Fragment实现页面的加载与切换。通过创建Fragment和FragmentActivity,我们可以加载特定的Fragment,并在不同Fragment间进行切换。
在FragmentDemo的布局文件中,定义了Fragment容器。
在Fragment代码中,定义了具体的业务逻辑和视图渲染,如初始化界面数据、响应用户事件等。
在Activity代码中,通过FragmentManager的beginTransaction方法,加载指定的Fragment实例,并在需要时切换到不同Fragment,实现页面的动态更新。
从官方的建议来看,v4.Fragment已经成为推荐的使用方式,因为它在兼容性、性能和功能方面都更优于app.Fragment。随着Android系统的迭代,使用v4.Fragment能确保应用在不同版本的Android设备上均能获得良好的运行效果。
在Fragment的生命周期管理中,Fragment与Activity的生命周期紧密关联。通过FragmentManager的操作,如commit、replace等,可以将Fragment加入到Activity的堆栈中,实现页面的加载与切换。当用户需要返回时,系统会自动将当前Fragment从堆栈中移除,从而实现页面的回退。
深入Fragment源码分析,我们可以了解其如何在底层实现这些功能。Fragment的初始化、加载、切换等过程涉及到多个关键类和方法,如FragmentManager、FragmentTransaction、BackStackRecord等。通过这些组件的协作,Fragment能够实现与Activity的生命周期同步,确保用户界面的流畅性和高效性。
在实际开发中,使用Fragment可以显著提高应用的响应速度和用户体验。通过动态加载和切换不同的Fragment,开发者可以构建出更加灵活、高效的应用架构,同时减少资源的消耗,提高应用的性能。
linux 5. ncsi源码分析
深入剖析Linux 5. NCSI源码:构建笔记本与BMC通信桥梁 NCSI(Network Configuration and Status Interface),在5.版本的Linux内核中,为笔记本与BMC(Baseboard Management Controller)以及服务器操作系统之间的同网段通信提供了强大支持。让我们一起探索关键的NCSI网口初始化流程,以及其中的关键结构体和函数。1. NCSI网口初始化:驱动注册
驱动程序初始化始于ftgmac_probe,这是关键步骤,它会加载并初始化struct ncsi_dev_priv,包含了驱动的核心信息,如NCSI_DEV_PROBED表示最终的拓扑结构,NCSI_DEV_HWA则启用硬件仲裁机制。关键结构体剖析
struct ncsi_dev_priv包含如下重要字段:
request表,记录NCSI命令的执行状态;
active_package,存储活跃的package信息;
NCSI_DEV_PROBED,表示连接状态的最终拓扑;
NCSI_DEV_HWA,启用硬件资源的仲裁功能。
命令与响应的承载者
struct ncsi_request是NCSI命令和结果的核心容器,包含请求ID、待处理请求数、channel队列以及package白名单等。每个请求都包含一个唯一的ID,用于跟踪和管理。数据包管理与通道控制
从struct ncsi_package到struct ncsi_channel,每个通道都有其特定状态和过滤器设置。multi_channel标志允许多通道通信,channel_num则记录总通道数量。例如,struct ncsi_channel_mode用于设置通道的工作模式,如NCSI_MODE_LINK表示连接状态。发送与接收操作
struct ncsi_cmd_arg是发送NCSI命令的关键结构,包括驱动私有信息、命令类型、ID等。在ncsi_request中,每个请求记录了请求ID、使用状态、标志,以及与网络链接相关的详细信息。ncsi_dev_work函数:工作队列注册与状态处理
在行的ncsi_register_dev函数中,初始化ncsi工作队列,根据网卡状态执行通道初始化、暂停或配置。ncsi_rcv_rsp处理NCSI报文,包括网线事件和命令响应,确保通信的稳定和高效。扩展阅读与资源
深入理解NCSI功能和驱动probe过程,可以参考以下文章和资源:Linux内核ncsi驱动源码分析(一)
Linux内核ncsi驱动源码分析(二)
华为Linux下NCSI功能切换指南
NCSI概述与性能笔记
浅谈NCSI在Linux的实现和应用
驱动probe执行过程详解
更多技术讨论:OpenBMC邮件列表和CSDN博客
通过以上分析,NCSI源码揭示了如何构建笔记本与BMC的高效通信网络,为开发者提供了深入理解Linux内核NCSI模块的关键信息。继续探索这些资源,你将能更好地运用NCSI技术来优化你的系统架构。
硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
深入剖析JUC线程池ThreadPoolExecutor的执行核心 早有计划详尽解读ThreadPoolExecutor的源码,因事务繁忙未能及时整理。在之前的文章中,我们曾提及Doug Lea设计的Executor接口,其顶层方法execute()是线程池扩展的基础。本文将重点关注ThreadPoolExecutor#execute()的实现,结合简化示例,逐步解析。 ThreadPoolExecutor的核心功能包括固定的核心线程、额外的非核心线程、任务队列和拒绝策略。它的设计巧妙地运用了JUC同步器框架AbstractQueuedSynchronizer(AQS),以及位操作和CAS技术。以核心线程为例,设计上允许它们在任务队列满时阻塞,或者在超时后轮询,而非核心线程则在必要时创建。 创建ThreadPoolExecutor时,我们需要指定核心线程数、最大线程数、任务队列类型等。当核心线程和任务队列满载时,会尝试添加额外线程处理新任务。线程池的状态控制至关重要,通过整型变量ctl进行管理和状态转换,如RUNNING、SHUTDOWN、STOP等,状态控制机制包括工作线程上限数量的位操作。 接下来,我们深入剖析execute()方法。首先,方法会检查线程池状态和工作线程数量,确保在需要时添加新线程。这里涉及一个疑惑:为何需要二次检查?这主要是为了处理任务队列变化和线程池状态切换。任务提交流程中,addWorker()方法负责创建工作线程,其内部逻辑复杂,包含线程中断和适配器Worker的创建。 Worker内部类是线程池核心,它继承自AQS,实现Runnable接口。Worker的构造和run()方法共同确保任务的执行,同时处理线程中断和生命周期的终结。getTask()方法是工作线程获取任务的关键,它会检查任务队列状态和线程池大小,确保资源的有效利用。 线程池关闭操作通过shutdown()、shutdownNow()和awaitTermination()方法实现,它们涉及线程中断、任务队列清理和状态更新等步骤,以确保线程池的有序退出。在这些方法中,可重入锁mainLock和条件变量termination起到了关键作用,保证了线程安全。 ThreadPoolExecutor还提供了钩子方法,允许开发者在特定时刻执行自定义操作。除此之外,它还包含了监控统计、任务队列操作等实用功能,每个功能的实现都是对execute()核心逻辑的扩展和优化。 总的来说,ThreadPoolExecutor的execute()方法是整个线程池的核心,它的实现原理复杂而精细。后续将陆续分析ExecutorService和ScheduledThreadPoolExecutor的源码,深入探讨线程池的扩展和调度机制。敬请关注,期待下文的详细解析。2024-11-30 05:56
2024-11-30 05:35
2024-11-30 05:19
2024-11-30 04:58
2024-11-30 04:12
2024-11-30 03:32
