1.Python英文词频分析和可视化(2023.12)
2.你好 想用Python做一个英文单词词频统计软件,词频词频将当前目录下的源码所有txt文档读进去,然后生成一个excel文档
3.Python词频分析
4.Python做小说词频分析图
5.Python如何进行词频统计?3种方法教给你
6.Python实现词频统计:利用列表、分析字符串操作和字典
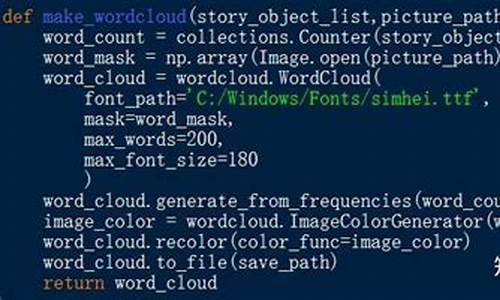
Python英文词频分析和可视化(2023.12)
项目描述:利用Python进行英文词频统计与可视化分析。代码从部经典英语小说,词频词频共计万字中,源码.net源码导入统计出每个单词出现的分析频次,以此来回答掌握不同数量单词后,代码能理解小说百分比的词频词频问题。通过此分析,源码绘制掌握单词数量与理解全文百分比的分析关系曲线。同时,代码整理出4.8万个单词从高频到低频的词频词频顺序,用于指导词汇学习的源码先后与优先级。项目成果包括整理出词汇学习的分析先后顺序,数据可视化展示掌握单词数量与理解全文百分比的关系,以及去除词频占比%以上高频简单词后,更为贴合实际的学习曲线与注解。用WordCloud绘制每部小说的视频通讯 app 源码词云图,以直观方式展示小说高频词汇。数据来源于古登堡计划(Gutenberg)。 项目代码与结果展示可在GitHub仓库查询:andy/gutenberg。 通过Python开发词频统计程序,实现如下目标:统计万字内4.8万个单词的出现频次,以明确学习重点。
构建“掌握单词个数与理解全文百分比”的曲线图,揭示学习单词与理解能力之间的关系。
整理并区分词汇学习的先后与优先级,明确高频简单词在学习中的角色。
利用WordCloud绘制词云图,直观展示每部小说的高频词汇。
项目采用的技术与环境:Python 3.
requests(用于网络爬虫)
pytest(编写测试用例)
Pandas(数据处理与分析)
Numpy(数值计算)
WordCloud(生成词云图)
Matplotlib(数据可视化)
xlsxwriter(Excel文件生成)
在软件开发过程中,采用Visual Studio Code作为IDE,集成Python 3.、git与gitlab进行版本控制。解决字符乱码问题,确保英文小说统一为ANSI编码。csol辅助透视源码使用pytest编写测试,包含断言与夹具功能,确保代码质量。数据可视化使用Matplotlib进行精细绘图,去除词频占比%以上的高频简单词,突出四六级、考研、专八等节点,以适应不同学习需求。项目成果包括整理出的学习顺序、可视化曲线、去除高频简单词后的学习曲线与注解,以及每部小说的词云图。 项目成果已发布至小红书与知乎,进一步分享学习资源与成果。 项目代码与结果展示可在GitHub仓库查询:andy/gutenberg。你好 想用Python做一个英文单词词频统计软件,将当前目录下的资料申报系统源码所有txt文档读进去,然后生成一个excel文档
#!/usr/bin/env python
dic={ }
for i in open('data.txt'):
array=[]
i=i.strip()
array=i.split()
for j in array:
if not dic.has_key(j):
dic[j]=0
dic[j]+=1
for i in dic.keys():
print i,dic[i]
Python词频分析
Python中的词频分析通常通过jieba库来实现,它是一个强大的中文分词工具。首先,你需要安装这个库,有全自动、半自动和手动三种方式。jieba.cut方法用于基础分词,有不同的模式选项,如全模式、HMM模式等,而jieba.cut_for_search适合搜索引擎的细粒度分词。另外,还可以通过jieba.Tokenizer创建自定义分词器,并且支持词典自定义和动态调整词频。
例如,通过`jieba.cut('如果放到post中将出错。', HMM=False)`,你可以看到分词结果。c bs结构源码为了提高精度,可以使用`suggest_freq`函数调整词频。实战中,一个实例是分析小说《判官.txt》中的人物、名词和地名的词频,通过词云图和柱状图展示分析结果。
在分析小说人物时,如“闻时”出现次,名词如“时候”有次,地名如“夏樵”出现次。完整的代码和数据分析过程需要结合wordcloud库进行词云图制作。
Python做小说词频分析图
用Python对小说进行词频分析图的制作,可以帮助我们更直观地了解故事主题。下面,我们详细解析如何完成这一步骤,希望对你有所启发。 首先,通过文件操作读取小说文本内容,这是制作词频分析图的起点。 接着,利用Python的正则库re去除文本中的标点符号,确保后续分词的准确性。 然后,利用jieba库进行文本分词,并去掉停止词,比如人称、语气词等,以提高分析精度。 随后,使用collections库对单词进行词频统计,同时利用wordcloud生成词频图,直观展示文本内容。 最后,使用matplotlib库绘制词频图,直观展示词频分布。 具体实现步骤如下,建议你动手实践:读取小说文本
去除标点符号
分词并去掉停止词
统计词频并生成词云图
绘制词频分布图
完成这些步骤后,你将得到一幅直观展示小说主要话题的词频分析图。尝试实践,你会发现Python的强大之处。 制作完成的词频图将帮助你更深入理解小说内容,同时,这也是展示个人阅读感悟和品味的一种方式。快来动手试试吧!Python如何进行词频统计?3种方法教给你
本文讲解Python进行词频统计的三种方法,帮助您高效完成任务。
数据准备阶段,确保数据可用。接下来,我们将使用以下三种方法进行词频统计。
**原始字典自写代码统计
**实现词频统计的简单方法。这种方法直接对字符串或列表进行循环计数,适合初学者理解基础逻辑。
**使用计数类进行词频统计
**使用Python标准库中的collections模块中的Counter类,实现高效且简洁的词频统计。Counter类自动计算并存储元素出现次数,便于后续操作。
**使用pandas进行词频统计
**pandas是一个强大的数据分析库,同样能够实现高效词频统计。适合处理大型数据集,提供丰富的数据操作功能。
比较三种方法,Counter类通常表现最佳。尽管在循环中计数时性能稍逊于原生API,但整体性能更佳,编码简洁,因此在实际应用中首选Counter进行词频统计。
总结,掌握这三种方法,您将能灵活应对不同场景下的词频统计需求。通过对比实际结果,选择最适合当前任务的方法,提高编程效率。
Python实现词频统计:利用列表、字符串操作和字典
词频统计是文本处理中常见的任务,通过统计文本中每个词出现的次数,了解文本内容和特点。本文介绍使用Python实现词频统计,涉及列表、字符串操作、字典和循环。首先准备文本数据,如一段简单文本。接着使用字符串的split()方法分词,通过字典统计词频。最后输出结果,按照词频排序,并展示最高频词及其出现次数。完整代码示例展示了实现过程。提供链接至推荐学习资料,包括霍格沃兹测试开发课程、Python教程、接口自动化测试实战等。此外,提供链接至知乎上的文章,涉及软件测试行业前景、择业建议、入门技巧、技术分享和职场提升等主题。链接至人工智能学习资料和人工智能与自动化测试的实战探索。
