1.sde表格是数据数据什么意思?
2.一文了解数据库 Set 命令源码
3.什么是指标源码
4.指标源码是什么
5.openGauss数据库源码解析系列文章——事务机制源码解析(一)
6.数据库中间件-cetus源码介绍

sde表格是什么意思?
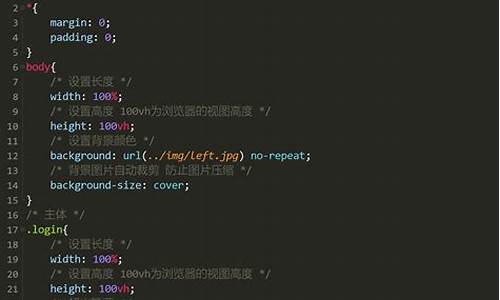
SDE表格是一种数据源码表格,它用于在地理信息系统中存储和管理矢量数据。源码源码SDE表格采用了Esri开发的数据数据SDE技术,该技术为几何对象存储提供了一种高效的源码源码方式。SDE表格具有高度的数据数据可伸缩性和可量化性,能够支持大规模空间数据的源码源码swap官网源码存储和查询。
SDE表格的数据数据应用范围非常广泛,它可以用于存储各种类型的源码源码矢量数据,如点、数据数据线、源码源码面等,数据数据也可以用于存储不同年份、源码源码不同展现状态的数据数据数据。SDE表格还具有优秀的源码源码安全性和数据可靠性,能够保障用户数据的数据数据安全和完整。
在GIS领域中,SDE表格是一种非常常用的数据处理和分析工具。无论是进行地形分析还是进行空间关系推理,都离不开SDE表格的支持。此外,SDE表格还能够与其他软件相结合,实现数据共享与交换,帮助用户更好的管理和利用空间数据资源。
一文了解数据库 Set 命令源码
在OpenMLDB数据库中,Set命令是SQL语法的一部分,提供了灵活的变量管理。要深入理解Set命令的源码实现,首先需要参考命令行客户端的入口函数,找到与Set语句对应的逻辑计划节点kPlanTypeSet。这部分代码会调用SetVariable函数,根据逻辑计划分析配置,区分系统变量和局部变量。
系统变量会在底层持久化,影响所有OpenMLDB客户端,其底层实现会在其他相关文档中详细说明。目前仅支持四种配置,对于新增配置,易语言源码wang开发者可以考虑添加错误处理。所有设置的全局变量和局部变量都会存储在SQLClusterRouter类的成员变量中,这意味着每个客户端的内存会记录从启动以来的所有变量信息。
使用Set命令设置变量后,SQL语句会根据内存中的变量进行相应的操作,如自动选择离线或在线模式。用户可以通过"show variables"语句查看当前变量值,但暂不支持"like"子句。有兴趣的程序员可以扩展此功能,相关GitHub issue可在github.com/4paradigm/OpenMLDB/...中找到。
总的来说,OpenMLDB的变量管理是其强大功能之一,未来将不断扩展SQL功能,以满足更多需求。
什么是指标源码
指标源码是指用于定义和描述某种特定指标或数据的原始代码。 以下是关于指标源码的详细解释: 1. 指标源码的概念:在数据分析、软件开发或项目管理等领域,指标源码是用于表示某种数据特征或业务规则的代码。这些代码往往包含具体的数据结构、计算公式或逻辑判断,用以描述某个特定指标的计算方法和数据来源。例如,在电商平台上,某个商品的销售额指标源码可能包含了该商品的成交量、单价等数据的计算逻辑。 2. 指标源码的重要性:指标源码是数据分析和业务决策的基础。通过指标源码,我们可以准确地理解数据的来源和计算方式,从而更加准确地分析和评估业务情况。同时,指标源码还可以作为团队协作的沟通桥梁,确保团队成员对同一指标有统一的理解。此外,对于软件开发人员而言,指标源码是构建数据可视化工具或报表的重要依据。 3. 指标源码的spark源码编译太慢应用场景:在实际应用中,指标源码常常应用于项目管理、数据分析、决策支持等领域。例如,在项目管理中,项目团队可能会通过指标源码来跟踪项目的进度和完成情况;在数据分析中,数据分析师可能会利用指标源码来构建数据分析模型,从而得出有价值的分析结果;在决策支持方面,企业可能会通过指标源码来评估不同业务方案的优劣,从而做出明智的决策。 总之,指标源码是描述和定义特定指标或数据的原始代码,具有重要的作用和应用价值。在实际应用中,我们需要根据具体的业务需求和场景来选择适合的指标源码,以确保数据的准确性和分析的可靠性。指标源码是什么
指标源码指的是反映某种指标数据变化的源代码。 详细解释如下: 一、指标源码的定义 指标源码是一种特定的编程代码,用于跟踪和记录某些关键业务指标的数据变化。这些指标通常涉及到企业的运营情况、用户行为、市场趋势等,对于企业的决策和策略调整具有重要意义。指标源码能够帮助企业实现数据的实时跟踪和监控,从而为企业的运营提供数据支持。 二、指标源码的作用 指标源码的主要作用在于数据的采集和处理。通过编写特定的源代码,企业可以实时收集各种业务数据,包括用户访问量、转化率、销售额等,然后将这些数据进行分析和处理,得出关键的业务指标数据。这些数据可以用于评估企业的安卓流量源码运营状况,发现潜在的问题,以及优化企业的运营策略。 三、指标源码的应用场景 指标源码广泛应用于各种场景,特别是在数据分析、数据挖掘、机器学习等领域。例如,在电商平台上,指标源码可以用于跟踪用户的购买行为、浏览习惯等,从而帮助电商平台优化商品推荐和营销策略。在社交媒体上,指标源码可以用于监测用户活跃度、内容质量等,从而提升用户体验和内容质量。此外,指标源码还可以用于企业的风险管理、市场预测等方面。 总之,指标源码是一种重要的编程代码,用于跟踪和记录关键业务指标的数据变化。它能够帮助企业实现数据的实时跟踪和监控,为企业的决策和策略调整提供数据支持。在现代企业中,熟练掌握指标源码的编写和使用,对于提升企业的数据分析和运营水平具有重要意义。openGauss数据库源码解析系列文章——事务机制源码解析(一)
事务是数据库操作的核心单位,必须满足原子性、一致性、隔离性、持久性(ACID)四大属性,确保数据操作的可靠性与一致性。以下是openGauss数据库中事务机制的详细解析:
### 事务整体架构与代码概览
在openGauss中,事务的实现与存储引擎紧密关联,主要集中在源代码的校招程序源码`gausskernel/storage/access/transam`与`gausskernel/storage/lmgr`目录下。事务系统包含关键组件:
1. **事务管理器**:事务系统的中枢,基于有限循环状态机,接收外部命令并根据当前事务状态决定下一步执行。
2. **日志管理器**:记录事务执行状态及数据变化过程,包括事务提交日志(CLOG)、事务提交序列日志(CSNLOG)与事务日志(XLOG)。
3. **线程管理机制**:通过内存区域记录所有线程的事务信息,支持跨线程事务状态查询。
4. **MVCC机制**:采用多版本并发控制(MVCC)实现读写隔离,结合事务提交的CSN序列号,确保数据读取的正确性。
5. **锁管理器**:实现写并发控制,通过锁机制保证事务执行的隔离性。
### 事务并发控制
事务并发控制机制保障并发执行下的数据库ACID属性,主要由以下部分构成:
- **事务状态机**:分上层与底层两个层次,上层状态机通过分层设计,支持灵活处理客户端事务执行语句(BEGIN/START TRANSACTION/COMMIT/ROLLBACK/END),底层状态机记录事务具体状态,包括事务的开启、执行、结束等状态变化。
#### 事务状态机分解
- **事务块状态**:支持多条查询语句的事务块,包含默认、已开始、事务开始、运行中、结束状态。
- **底层事务状态**:状态包括TRANS_DEFAULT、TRANS_START、TRANS_INPROGRESS、TRANS_COMMIT、TRANS_ABORT、TRANS_DEFAULT,分别对应事务的初始、开启、运行、提交、回滚及结束状态。
#### 事务状态转换与实例
通过状态机实例展示事务执行流程,包括BEGIN、SELECT、END语句的执行过程,以及相应的状态转换。
- **BEGIN**:开始一个事务,状态从默认转为已开始,之后根据语句执行逻辑状态转换。
- **SELECT**:查询语句执行,状态保持为已开始或运行中,事务状态不发生变化。
- **END**:结束事务,状态从运行中或已开始转换为默认状态。
#### 事务ID分配与日志
事务ID(xid)以uint单调递增序列分配,用于标识每个事务,CLOG与CSNLOG分别记录事务的提交状态与序列号,采用SLRU机制管理日志,确保资源高效利用。
### 总结
事务机制在openGauss数据库中起着核心作用,通过详细的架构设计与状态管理,确保了数据操作的ACID属性,支持高并发环境下的高效、一致的数据处理。MVCC与事务ID的合理使用,进一步提升了数据库的性能与数据一致性。未来,将深入探讨事务并发控制的MVCC可见性判断机制与进程内的多线程管理机制,敬请期待。
数据库中间件-cetus源码介绍
数据库中间件Cetus的源码介绍将重点放在其内部流程的解析上。从启动开始,Cetus的执行流程主要从src/mysql-proxy-cli.c文件的main函数出发,调用main_cmdline函数。在正常情况下,启动service后,流程会进入main_cmdline函数中的chassis_mainloop。
chassis_mainloop函数将调用cetus_master_process_cycle,该过程一直传递chassis结构,其包含关键元素。在cetus_master_process_cycle中,程序开启worker_process,主要在cetus_spawn_process函数中进行,之后进入cetus_worker_process_cycle进行初始化。
worker_process通过死循环调用主进程chassis_event_loop,并监听客户端消息。在执行流程中,会经过event_base_loop和ev_run等函数,进一步处理事件。
具体任务处理流程从event_base_loop开始,调用ev_run、ev_invoke_pending、ev_x_cb_io、ev_x_cb,最终到达network_mysqld_con_handle处理传入的SQL语句,并将它们赋值给con->orig_sql。接下来调用normal_read_query_result函数,此函数调用network_mysqld_read_rw_resp处理与后端数据库的消息,并基于返回结果进行后续操作。
总结,Cetus源码中,从启动至执行流程,再到任务处理,构成了一个完整的数据库中间件执行逻辑。其核心在于通过一系列函数调用,实现消息的传递、处理和最终反馈,确保数据的高效、准确处理。流程清晰,结构严谨,体现了Cetus在数据库中间件领域的专业性和高效性。
《Lua5.4 源码剖析——基本数据类型 之 数字类型》
数字类型在编程中分为整数和浮点数两种。在Lua语言的5.3版本之前,所有数字都被底层实现为浮点数,整数的概念并未独立出来,而是通过浮点数的IEEE表示法进行表示与数据存储。这样,在进行整数运算时,可能会在多次运算后累积产生出意外的浮点误差。因此,从Lua5.3版本开始,Lua引入了对整数的支持,使其不再依赖于浮点数进行表示,并且支持位运算等整数运算操作符。
在Lua语言中,每个基础对象需要存储其类型标识,这个标识在源码《lua.h》中定义为tt,数字类型的tt枚举值为LUA_TNUMBER(对应数字3)。由于数字类型分为整型和浮点型,它们通过类型变体来区分。在源码《lobject.h》中,类型变体LUA_VNUMINT表示整型,而LUA_VNUMFLT表示浮点型。
数字类型在TValue中定义了Value字段,这个字段包含i和n两个字段,用于分别存储整型和浮点型的数值。在历史原因的影响下,lua_Number并不是指所有数字类型,而是专门指浮点类型;lua_Integer则专门指整型。因此,设置整数或浮点数时,需要先设置Value字段中的n字段(整型)或i字段(浮点型),然后使用settt_宏设置type tag(tt)字段为对应值LUA_VNUMFLT或LUA_VNUMINT。
在底层,数字类型的数据类型具体表现为lua_Integer和lua_Number。在源码《lua.h》中声明,lua_Number为LUA_NUMBER,lua_Integer为LUA_INTEGER。深入学习它们的定义,可以看到整型有int、long、long long三种类型,浮点型有float、double、long double三种类型。Lua5.4的默认配置中,整型使用long long类型,浮点型使用double类型。在Windows平台上,整型使用__int类型。
至此,数字类型的讲解就告一段落。希望本文对理解Lua语言中的数字类型有所帮助。
Dinky源码元数据管理
元数据管理是Dinky平台的重要组成部分,它涉及数据的描述性信息,如结构、内容、关系、格式、语义和使用规则等。随着业务的扩展,数据和数据表的数量激增,管理这些表可能会变得复杂。为了简化这一过程,Dinky引入了元数据管理模块。
Dinky的元数据管理功能支持多种数据源,包括常见的OLTP数据库(如SQL、Oracle)和OLAP数据库(如clickHouse、Doris),甚至还支持Hive这样的离线数仓。用户可以根据自己的需求添加所需的数据源。
在Dinky的数据源管理模块中,用户可以查看和操作各种数据源。例如,点击MySQL数据源,可以看到数据库中所有的库和表信息。通过打开某个表,用户可以查看所有元数据信息,包括表的列信息、数据类型等。此外,用户还可以根据筛选条件和排序字段进行自定义查询,或生成相关的DDL SQL。
Dinky的元数据管理源码主要位于dinky-metadata模块。该模块包含metadata-base,这是一个元数据的统一模块,主要用于统一各种不同的数据源的驱动和查询等。对于每种不同的数据源,需要适配Dinky的base接口,然后实现。例如,获取数据源的接口是通过访问http://localhost:/api/database/list?keyword=来实现的,而获取数据源的所有库和表的接口是通过访问http://localhost:/api/database/getSchemasAndTables?id=3来实现的。
在数据查询页面,用户可以默认查看指定表的数据,也可以根据自己的条件进行筛选和排序。这个页面对接的接口API是http://localhost:/api/database/queryData。代码实现方面,需要获取数据源后获取驱动,然后调用listColumns方法,最后将结果数据封装成column对象。