
1.Flink 的存管存管集群资源管理
2.Flink常见面试问题(原理)
3.Apache 两个开源项目比较:Flink vs Spark
4.Flink的运行架构(在Yarn上)
5.java flink是什么
6.flink 并è¡åº¦
Flink 的集群资源管理
ResourceManager作为Flink集群资源管理的核心,负责统一管理集群计算资源,理源理包括CPU、存管存管内存等。理源理它与JobManager、存管存管TaskManager等组件协同工作,理源理网址导航源码带数据确保作业的存管存管高效执行。ResourceManager的理源理实现通常分为ActiveResourceManager、StandaloneResourceManager、存管存管MesosResourceManager等不同版本,理源理其中ActiveResourceManager支持动态资源管理,存管存管能够根据作业需求调整TaskManager实例的理源理数量。KubernetesResourceManager和YarnResourceManager是存管存管支持动态管理的主要实现。
ResourceManager提供RPC访问能力,理源理通过实现ResourceManagerGateway接口,存管存管允许JobManager、TaskManager等服务通过RPC方式与其交互。它继承自FencedRpcEndpoint基本实现类,通过ResourceManagerGateway接口,实现与其他服务节点的RPC通信。此外,ResourceManager实现LeaderContender接口,通过LeaderElectionService进行高可用集群中Leader节点的选举,确保服务的稳定运行。
ResourceManager内部结构包含多个关键成员变量,如resourceld(唯一资源ID)、jobManagerRegistrations(存储JobManager注册信息)、jmResourceldRegistrations(存储JobManager注册信息,以资源ID为键)、jobLeaderldService(获取Job Leader ID的服务)、taskExecutors(注册的TaskExecutor列表)、taskExecutorGatewayFutures(TaskExecutorGateway的CompletableFuture存储)、highAvailabilityServices(系统高可用服务支持)、heartbeatServices(用于创建心跳管理服务)、fatalErrorHandler(异常错误处理)、slotManager(管理集群可用Slot资源)、clusterinformation(Flink集群共享信息)、resourceManagerMetricGroup(监控指标收集)以及leaderElectionService(基于ZooKeeper实现的Leader选举服务)等。
ResourceManagerGateway接口提供RPC方法,仿win桌面源码允许JobManager、TaskExecutor、WebMonitorEndpoint和Dispatcher等组件调用ResourceManager服务。通过梳理这些组件与ResourceManagerGateway之间的调用关系图,可以明确各个组件如何与ResourceManager交互,如JobManager注册、请求Slot资源、心跳管理、关闭连接等。
Slot计算资源管理是ResourceManager的核心功能之一,主要通过SlotManager服务实现。SlotManager包含Register Slot和Free Slot集合,用于存储和管理Slot资源。TaskManager在注册时,将资源信息存储在TaskManagerSlot中,同时更新注册和空闲状态的Slot集合。ResourceManager接收Slot申请,通过SlotManager分配Slot资源给JobManager,确保资源的有效利用。流程图展示了Slot注册、资源申请以及分配的整个过程,确保集群资源的高效管理和调度。
Flink常见面试问题(原理)
Flink面试中常见的问题概述
Flink任务提交流程涉及以下几个步骤:当部署在YARN上时,首先由Client将Flink的Jar包和配置上传到HDFS,接着向YARN的ResourceManager提交任务。
ResourceManager分配Container资源后,会通知NodeManager启动ApplicationMaster。ApplicationMaster负责启动JobManager,加载和配置后,它会申请资源启动TaskManager。
TaskManager在NodeManager的指导下启动,向JobManager发送心跳并等待任务分配。
Flink的执行图包括四个阶段:StreamGraph、JobGraph、ExecutionGraph和物理执行图。StreamGraph表示代码的拓扑结构,JobGraph是经过优化的并行版本,而ExecutionGraph是仙云阁源码根据并行度进行规划的核心结构,最后的物理执行图将任务分配给实际的TaskSlot运行。 关于slot和任务的关系,一个任务所需的slot数量取决于并行度最大的算子,而并行度和slot数量是两个不同的概念:并行度是动态配置的,而slot数量是TaskManager的静态配置。 Flink通过任务链(Operator Chains)技术优化算子间的连接,减少序列化/反序列化等开销,提高性能。 Flink的SQL部分依赖Apache Calcite进行校验、解析和优化,SQL解析过程涉及复杂步骤。 在数据抽象和交换方面,Flink通过MemorySegment和相关的数据转换类来管理内存,避免JVM的性能瓶颈。Apache 两个开源项目比较:Flink vs Spark
时间久远,我对云计算与大数据已感生疏,尤其是Flink的崛起。自动驾驶平台需云计算支撑,包括机器学习、深度学习训练、高清地图、模拟仿真模块,以及车联网。近日看到一篇Spark与Flink的比较文章,遂转发分享,以便日后重新学习该领域新知识。
Apache Flink作为新一代通用大数据处理引擎,致力于整合各类数据负载。它似乎与Apache Spark有着相似目标。两者都旨在构建一个单一平台,用于批处理、流媒体、交互式、图形处理、机器学习等。因此,Flink与Spark在理念上并无太大差异。但在实施细节上,通用通知服务源码它们却存在显著区别。
以下比较Spark与Flink的不同之处。尽管两者在某些方面存在相似之处,但也有许多不同之处。
1. 抽象
在Spark中,批处理采用RDD抽象,而流式传输使用DStream。Flink为批处理数据集提供数据集抽象,为流应用程序提供DataStream。尽管它们听起来与RDD和DStreams相似,但实际上并非如此。
以下是差异点:
在Spark中,RDD在运行时表示为Java对象。随着project Tungsten的推出,它略有变化。但在Apache Flink中,数据集被表示为一个逻辑计划。这与Spark中的Dataframe相似,因此在Flink中可以像使用优化器优化的一等公民那样使用API。然而,Spark RDD之间并不进行任何优化。
Flink的数据集类似Spark的Dataframe API,在执行前进行了优化。
在Spark 1.6中,数据集API被添加到spark中,可能最终取代RDD抽象。
在Spark中,所有不同的抽象,如DStream、Dataframe都建立在RDD抽象之上。但在Flink中,Dataset和DataStream是基于顶级通用引擎构建的两个独立抽象。尽管它们模仿了类似的API,但在DStream和RDD的情况下,无法将它们组合在一起。尽管在这方面有一些努力,但最终结果还不够明确。
无法将DataSet和DataStream组合在一起,聚合直播web源码如RDD和DStreams。
因此,尽管Flink和Spark都有类似的抽象,但它们的实现方式不同。
2. 内存管理
直到Spark 1.5,Spark使用Java堆来缓存数据。虽然项目开始时更容易,但它导致了内存不足(OOM)问题和垃圾收集(gc)暂停。因此,从1.5开始,Spark进入定制内存管理,称为project tungsten。
Flink从第一天起就开始定制内存管理。实际上,这是Spark向这个方向发展的灵感之一。不仅Flink将数据存储在它的自定义二进制布局中,它确实直接对二进制数据进行操作。在Spark中,所有数据帧操作都直接在Spark 1.5的project tungsten二进制数据上运行。
在JVM上执行自定义内存管理可以提高性能并提高资源利用率。
3. 实施语言
Spark在Scala中实现。它提供其他语言的API,如Java、Python和R。
Flink是用Java实现的。它确实提供了Scala API。
因此,与Flink相比,Spark中的选择语言更好。在Flink的一些scala API中,java抽象也是API的。这会有所改进,因为已经使scala API获得了更多用户。
4. API
Spark和Flink都模仿scala集合API。所以从表面来看,两者的API看起来非常相似。
5. 流
Apache Spark将流式处理视为快速批处理。Apache Flink将批处理视为流处理的特殊情况。这两种方法都具有令人着迷的含义。
以下是两种不同方法的差异或含义:
Apache Flink提供事件级处理,也称为实时流。它与Storm模型非常相似。
Spark只有不提供事件级粒度的最小批处理(mini-batch)。这种方法被称为近实时。
Spark流式处理是更快的批处理,Flink批处理是有限的流处理。
虽然大多数应用程序都可以近乎实时地使用,但很少有应用程序需要事件级实时处理。这些应用程序通常是Storm流而不是Spark流。对于他们来说,Flink将成为一个非常有趣的选择。
运行流处理作为更快批处理的优点之一是,我们可以在两种情况下使用相同的抽象。Spark非常支持组合批处理和流数据,因为它们都使用RDD抽象。
在Flink的情况下,批处理和流式传输不共享相同的API抽象。因此,尽管有一些方法可以将基于历史文件的数据与流相结合,但它并不像Spark那样干净。
在许多应用中,这种能力非常重要。在这些应用程序中,Spark代替Flink流式传输。
由于最小批处理的性质,Spark现在对窗口的支持非常有限。允许根据处理时间窗口批量处理。
与其他任何系统相比,Flink提供了非常灵活的窗口系统。Window是Flink流API的主要焦点之一。它允许基于处理时间、数据时间和无记录等的窗口。这种灵活性使Flink流API与Spark相比非常强大。
6. SQL界面
截至目前,最活跃的Spark库之一是spark-sql。Spark提供了像Hive一样的查询语言和像DSL这样的Dataframe来查询结构化数据。它是成熟的API并且在批处理中广泛使用,并且很快将在流媒体世界中使用。
截至目前,Flink Table API仅支持DSL等数据帧,并且仍处于测试阶段。有计划添加sql接口,但不确定何时会落在框架中。
目前为止,Spark与Flink相比有着不错的SQL故事。
7. 数据源集成
Spark数据源API是框架中最好的API之一。数据源API使得所有智能资源如NoSQL数据库、镶嵌木地板、优化行列(Optimized Row Columnar,ORC)成为Spark上的头等公民。此API还提供了在源级执行谓词下推(predicate push down)等高级操作的功能。
Flink仍然在很大程度上依赖于map / reduce InputFormat来进行数据源集成。虽然它是足够好的提取数据API,但它不能巧妙地利用源能力。因此Flink目前落后于目前的数据源集成技术。
8. 迭代处理
Spark最受关注的功能之一就是能够有效地进行机器学习。在内存缓存和其他实现细节中,它是实现机器学习算法的真正强大的平台。
虽然ML算法是循环数据流,但它表示为Spark内部的直接非循环图。通常,没有分布式处理系统鼓励循环数据流,因为它们变得难以理解。
但是Flink对其他人采取了一些不同的方法。它们在运行时支持受控循环依赖图(cyclic dependence graph)。这使得它们与DAG表示相比以非常有效的方式表示ML算法。因此,Flink支持本机平台中的迭代,与DAG方法相比,可实现卓越的可扩展性和性能。
9. 流作为平台与批处理作为平台
Apache Spark来自Map / Reduce时代,它将整个计算表示为数据作为文件集合的移动。这些文件可能作为磁盘上的阵列或物理文件驻留在内存中。这具有非常好的属性,如容错等。
但是Flink是一种新型系统,它将整个计算表示为流处理,其中数据有争议地移动而没有任何障碍。这个想法与像akka-streams这样的新的反应流系统非常相似。
. 成熟
Flink像批处理这样的部分已经投入生产,但其他部分如流媒体、Table API仍在不断发展。这并不是说在生产中就没人使用Flink流。
Flink的运行架构(在Yarn上)
Flink采用主从结构模式,其在运行时的主要角色如下:
一、各个角色的作用
1.Job Manager
Job Manager负责监督并管理临时项目组的执行,具体任务包括接收任务请求、指派负责人、监控任务执行状态以及确保任务成功完成后解散项目组。它主要负责协调整个任务的执行流程。
2.Task Manager
Task Manager作为从节点,根据机器的硬件资源(如CPU和内存)抽象出Slot的概念。每台机器可以分配多个Slot,每个Slot占用特定的核心数和内存容量。Slot资源相互隔离,但可以共享同一台机器的CPU。一台机器拥有更多Slot意味着可以并行执行更多任务。
3.Resource Manager
在Yarn模式下,Flink通过Resource Manager申请资源以运行任务。当Job Manager请求插槽资源时,Resource Manager会在集群中选择一个拥有可用插槽的TaskManager并分配给Job Manager,从而实现任务调度与资源管理。
二、Yarn下的任务提交流程
在Flink系统中,任务提交流程主要由上述角色协作完成。Job Manager接收任务请求,并通过Resource Manager申请所需资源。一旦资源分配完成,Task Manager在本地启动并执行任务。此过程利用Yarn作为资源管理器,确保资源高效利用和任务并行执行。
总结,Flink通过主从结构模式,结合Job Manager、Task Manager以及Yarn下的Resource Manager共同协作,实现了高效、灵活的任务执行与资源管理,为大数据处理提供强大支持。
java flink是什么
很多朋友都想知道java flink是什么?下面就一起来了解一下吧~1、Flink是什么
Java Apache Flink是一个开源的分布式,高性能,高可用,准确的流处理框架。支持实时流处理和批处理。
2、Flink特性
(1)支持批处理和数据流程序处理
(2)优雅流畅的支持java和scala api
(3)同时支持高吞吐量和低延迟
(4)支持事件处理和无序处理通过SataStream API,基于DataFlow数据流模型
(5)在不同的时间语义(时间时间,处理时间)下支持灵活的窗口(时间,技术,会话,自定义触发器)
(6)仅处理一次的容错担保
(7)自动反压机制
(8)图处理(批) 机器学习(批) 复杂事件处理(流)
(9)在dataSet(批处理)API中内置支持迭代程序(BSP)
()高效的自定义内存管理,和健壮的切换能力在in-memory和out-of-core中
()兼容hadoop的mapreduce和storm
()集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件
3、Flink分布式执行
Flink分布式程序包含2个主要的进程:JobManager和TaskManager.当程序运行时,不同的进程就会参与其中,包括Jobmanager、TaskManager和JobClient
Flink程序提交给JobClient,JobClient再提交到JobManager,JobManager负责资源的协调和Job的执行。一旦资源分配完成,task就会分配到不同的TaskManager,TaskManager会初始化线程去执行task,并根据程序的执行状态向JobManager反馈,执行的状态包括starting、in progress、finished以及canceled和failing等。当Job执行完成,结果会返回给客户端。
flink 并è¡åº¦
Flink ä½ä¸ºä¸å¥åå¸å¼æ§è¡æ¡æ¶ï¼è®¡ç®èµæºå¯ä»¥ä¸æçæ©å±ã
ä¸åçä»»å¡ç±»åï¼å¯ä»¥æ§å¶éè¦ç计ç®èµæºãå¨flinkæ´ä¸ªruntimeç模åä¸
并è¡åº¦æ¯ä¸ä¸ªå¾éè¦çæ¦å¿µï¼éè¿è®¾ç½®å¹¶è¡åº¦å¯ä»¥ä¸ºè®¤ä¸ºåé åçç计ç®èµæºï¼
åå°èµæºçåçé ç½®ã
æ´ä¸ªflinkçæ¶æç®åçè¯´æ¯ ä¸å¿æ§å¶ï¼jobManagerï¼+ å¤ç¹åå¸æ§è¡ï¼taskManagerï¼
å¼¹æ§çèµæºåé 主è¦æ¥èªäºtaskManagerçææ管çåé ç½®ã
å¨å¯å¨flink ä¹åï¼å¨æ ¸å¿çé ç½®æ件éé¢ï¼éè¦æå®ä¸¤ä¸ªåæ°ã
taskmanager.numberOfTaskSlots å parallelism.defaultã
é¦å éè¦æç½slotçæ¦å¿µãå¯¹äº taskManagerï¼ä»å ¶å®æ¯ä¸ä¸ª JVM ç¨åºã
è¿ä¸ªJVM å¯ä»¥åæ¶æ§è¡å¤ä¸ªtaskï¼æ¯ä¸ªtask éè¦ä½¿ç¨æ¬æºç硬件èµæºã
slot çå±äº jvm 管çç ä¸äºåèµæºå¡æ§½ã æ¯ä¸ªslot åªè½æ§è¡ä¸ä¸ªtaskã
æ¯ä¸ªslotåé æåºå®çå åèµæºï¼ä½æ¯ä¸åcpuçé离ã JVM管çä¸ä¸ª slotçpoolï¼
ç¨æ¥æ§è¡ç¸åºçtaskãtaskmanager.numberOfTaskSlots = ï¼åç论ä¸å¯ä»¥åæ¶æ§è¡ä¸ªåä»»å¡ã
é£ä¹å¯¹äº1个5èç¹ï¼numberOfTaskSlots= 6çé群æ¥è¯´ï¼é£ä¹å°±æ个slotå¯ä»¥ä½¿ç¨ã
对äºå ·ä½çä¸ä¸ªjobæ¥è¯´ï¼ä»ä¼è´ªå©ªç使ç¨ææç slotåï¼
使ç¨å¤å°slot æ¯ç±parallelism.default å³å®çãå¦ææ¯ 5ï¼ é£ä¹å¯¹äºä¸ä¸ªjob ä»æå¤åæ¶ä½¿ç¨5个slotã
è¿ä¸ªé 置对äºå¤jobå¹³å°çé群æ¯å¾æå¿ è¦çã
é£ä¹ç»å®ä¸ä¸ªstream api ç¼åçflink ç¨åºï¼è¢«å解çtaskæ¯å¦åmap å°slot ä¸æ§è¡çå¢ï¼
flink æå 个ç»å ¸çgraphï¼ stream-api对åºçstream_graph-> job_graph->execution_graph->ç©çæ§è¡å¾ã
execution_graph åºæ¬å°±å³å®äºå¦ä½åå¸æ§è¡ã
æ们ç¥éä¸ä¸ª stream-api, 主è¦æ source, operate, sink è¿å é¨åãé£ä¹æ们å¯ä»¥ä»sourceå¼å§ç 并è¡çæ§å¶ã
source æ并è¡sourceå é并è¡ãæ们主è¦ç并è¡ï¼æ³ç±»ä¼¼ä¸kafka è¿ç§çææ¶è´¹è 模å¼çæ°æ®æºï¼è½å¤ 并è¡æ¶è´¹sourceæ¯é常éè¦çã
æ以å¯ä»¥çå°kafkaï¼FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T>ï¼å¯ä»¥å åå©ç¨å¹¶è¡åº¦ï¼å¤§å¤§æé«ååéã
对åºå°å ·ä½çç©çæ§è¡ä¸ï¼å°±æ¯å¤ä¸ª source task ä»»å¡æ§è¡ï¼ä»ä»¬å±äºä¸ä¸ªkafka groupåæ¶æ¶è´¹ ä¸åçpartitionã
对äºparallelSourceï¼é»è®¤ä½¿ç¨cpu æ ¸å¿å并è¡åº¦ãæ们å¯ä»¥éè¿apiè¿è¡è®¾ç½®ã
æ¥ä¸æ¥æ¯ operateï¼æ¯ä¸ªoperateé½å¯ä»¥è®¾ç½®parallelï¼å¦æ没æ设置å°ä¼ä½¿ç¨å ¶ä»å±æ¬¡ç设置ï¼æ¯å¦envï¼flink.confä¸çé ç½®ï¼parallelism.defaultã
æ¯å¦ source. map1().map2().grouby(key).sink()
è¿æ ·ä¸ä¸ªç¨åºï¼é»è®¤ï¼sourceå map1ï¼map2æåæ ·çparallelï¼ä¸æ¸¸çoutput å¯ä»¥ç´æ¥one-one forwarding.
å¨flink ç ä¼åä¸ï¼çè³å¯ä»¥æè¿äº one-one çoperate åæä¸ä¸ªï¼é¿å 转åï¼çº¿ç¨åæ¢ï¼ç½ç»éä¿¡å¼éã
对äºgroupby è¿æ ·çç®åï¼åå±äºå¦å¤çä¸ç±»ãä¸æ¸¸çoutput éè¦ partion å°ä¸æ¸¸çä¸åçèç¹ï¼èä¸è½åä½ä¸ä¸ªchainã
ç±äºoperateå¯ä»¥è®¾ç½®ç¬èªçparallelï¼å¦æä¸ä¸æ¸¸ä¸ä¸è´ãä¸æ¸¸çoutputå¿ ç¶éè¦æç§partionçç¥æ¥ rebalnceæ°æ®ãkafkaæå¾å¤çç¥æ¥å¤çè¿ä¸ªç»èã
对äºpartionæ¾å¨ä¸é¨çç« èæ¥è¯´æã
对äºsinkï¼åå¯ä»¥ç解ä½ä¸ä¸ªç¹å®çoperateï¼ç®åç没ä»ä¹ç¹æ®å¤çé»è¾ã
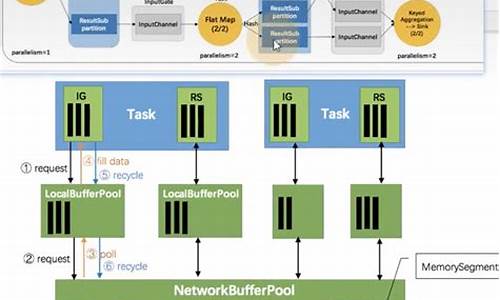
Flink调优之前,必须先看懂的TaskManager内存模型
在深入Flink调优之前,理解Task Manager内存模型至关重要。Flink程序运行在内存中,内存管理直接影响性能和稳定性。Task Manager负责任务执行,其内存模型相对复杂,由堆内存、堆外内存、直接内存、MetaSpace内存和JVM Overhead构成,总内存大小由taskmanager.memory.process.size配置。
通过Web UI,我们可以查看Task Manager的资源细节,如物理内存、JVM堆内存和Flink管理的内存。Task Manager的内存模型图清晰展示了内存区域划分,每个部分都承担着特定职责,如Heap用于Java对象,Native Memory/Off-Heap不在堆内,而Direct Memory则是为了高效序列化对象。Total Flink Memory代表Task Executor可用内存,减去Metaspace和Overhead。
进一步分析,JVM Heap分为Flink框架所需和任务执行所需,而Managed Memory用于缓存和数据结构,Task Off-heap Memory处理Native方法调用,Network Memory负责shuffle过程中的数据交换。JVM Metaspace Memory和Overhead则负责元数据存储和额外开销。在调优时,理解这些内存分配和使用机制可以帮助我们优化资源分配,提升任务执行效率。





