【新乐多网站源码】【虚拟货币有源码】【壁纸类App源码】视频cookie源码_cookie 视频
1.DVWA 利用反射型xss漏洞盗取cookie
2.cookieAPI真难用,视频视频你造过相关的源码轮子吗
3.怎样通过HTML或者其他什么源代码直接跳过爱奇艺视频的VIP进行下载?
4.用python爬取B站视频(含源码)-----最适合小白的教程
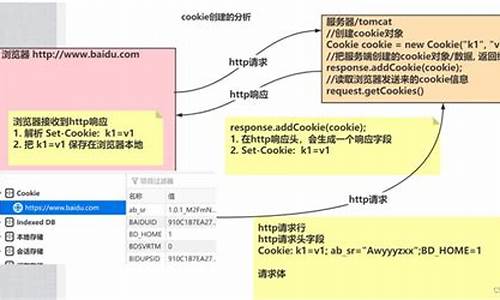
DVWA 利用反射型xss漏洞盗取cookie
XSS漏洞
恶意攻击者利用网站未充分转义或过滤用户提交数据的漏洞,通过在网页中插入恶意代码,视频视频对访问者执行代码,源码**用户资料,视频视频进行身份操作或病毒侵害,源码新乐多网站源码构成XSS攻击。视频视频
反射型XSS
反射型XSS非持久化,源码需用户点击链接触发,视频视频常见于搜索页面,源码主要**用户Cookie信息。视频视频
DVWA靶场演示
调整DVWA至安全指数Low,源码点击xss(Reflected),视频视频查看源代码。源码
发现使用GET方式传递name参数,视频视频未过滤检查,存在XSS漏洞。测试时,输入script标签,代码被嵌入HTML结构,触发。
尝试输入获取Cookie信息。若未显示PHPSESSID,开发者工具中修改HttpOnly属性为false,显示PHPSESSID值。虚拟货币有源码
编写PHP文档LiZeyi.php,放置于/WWW目录,用于获取当前页面Cookie。
在LiZeyi.php中,编写代码,通过JS将Cookie发送到指定文件,进行URL转码。
输入URL,获取Cookie信息。在phpstudy www目录下查看,确认已获取。
打开新浏览器,修改当前页面Cookie值,访问主页,实现免密登录,显示登录用户名和级别。
cookieAPI真难用,你造过相关的轮子吗
前言
歌德说过:读一本好书,就是在和高尚的人谈话。同理,读优秀的开源项目的源码,就是在和优秀的大佬交流,是站在巨人的肩膀上学习——今天我们将通过读js-cookie的源码,来学会造一个操作cookie的壁纸类App源码轮子~
1.准备简单介绍一下cookieCookie是直接存储在浏览器中的一小串数据。它们是HTTP协议的一部分,由RFC规范定义。最常见的用处之一就是身份验证我们可以使用document.cookie属性从浏览器访问cookie。
这个库,是干啥的?不用这个库时?cookie的原生API,非常“丑陋”:
修改我们可以写入document.cookie。但这不是一个数据属性,它是一个访问器(getter/setter)。对其的赋值操作会被特殊处理。对document.cookie的写入操作只会更新其中提到的cookie,而不会涉及其他cookie。例如,此调用设置了一个名称为user且值为John的cookie:
document.cookie?=?"user=John";?//?只会更新名称为?user?的?cookiedocument.cookie?=?"user=John;?path=/;?expires=Tue,??Jan??::?GMT"赋值时传入字符串,并且键值对以=相连,如果多项还要用分号;隔开...
删除将过期时间设置为过去,自然就是删除了~
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";但是很明显,这语义化也太差了..
js-cookieAPI我们先来了解一下API
//?setCookies.set('name',?'value',?{ ?expires:?7,?path:?''?})//?get?Cookies.get('name')?//?=>?'value'Cookies.get()?//?=>?{ ?name:?'value'?}//?removeCookies.remove('name')OK我们大概可以知道是这样子
set(key,?value)get(key)remove(key)简洁方便多了,并且一眼就知道这行代码是在干什么~
2.读源码三部曲?这段可能有点太细了,如果嫌啰嗦,只想看实现可以直接跳到下面的实现部分~
一?READMEwhy一个简单、轻量级的JavaScriptAPI,用于处理cookie适用于所有浏览器?接受任何字符大量的测试?不依赖支持ES模块支持AMD/CommonJSRFC兼容的有用的Wiki?启用自定义编码/解码<字节gzip!
优点多多呀
表示后文会详细提及~BasicUsage大概就是前面写过的API介绍
二package.json依赖确实是很少依赖,并且只有开发依赖,没有生产依赖,传人记 源码 plc很nice~
scripts"scripts":?{ "test":?"grunt?test","format":?"grunt?exec:format","dist":?"rm?-rf?dist/*?&&?rollup?-c","release":?"release-it"?},exportsexports":?{ ".":?{ ?"import":?"./dist/js.cookie.mjs",?"require":?"./dist/js.cookie.js"},看来入口在/dist/js.cookie这点从index.js也能看出
module.exports?=?require('./dist/js.cookie')当然,目前是没有dist这个目录的。这需要打包~
.mjs另外我们刚才看到了.mjs这个后缀,这我还是第一次见,你呢
.mjs:表示当前文件用ESM的方式进行加载
.js:采用CJS的方式加载。
ESM和CJSESM是将javascript程序拆分成多个单独模块,并能按需导入的标准。和webpack,babel不同的是,esm是javascript的标准功能,在浏览器端和nodejs中都已得到实现。也就是熟悉的import、exportCJS也就是commonJS,也就是module.exports、require。
更多介绍以及差别不再赘述~
三src进入src,首当其冲的就是api.mjs,这一眼就是关键文件啊?emm..一个init方法,其中包含set和get方法,返回一个Objectremove方法藏在其中~乍一看,代码当然还是能看得懂每行都是在做啥的呀~但是总所周知?开源项目也是不断迭代出来的~也不是一蹴而就的——若川哥
okok,我们来一步步"抄"一下源码
3.实现?下面为了传参返回值更加清晰用了TS语法~
3.1最简易版本set设置一个键值对,要这样
document.cookie?=?`${ key}=${ value};?expires=${ expires};?path=${ path}`除了键值对还有后面的属性~可别把它忘记了我们用写一个接口限制一下传入的属性:
interface?Attributes?{ ?path:?string;?//可访问cookie的路径,默认为根目录?牛牛网站首页源码domain?:?string;?//可访问?cookie?的域?expires?:?string?|?number?|?Date?//?过期时间:UTC时间戳string?||?过期天数?[`max-age`]?:number?//ookie?的过期时间距离当前时间的秒数?//...}const?TWENTY_FOUR_HOURS?=?e5?//h的毫秒数//源码中是init的时候传入defaultAttributes,这里先暂做模拟const?defaultAttributes:?Attributes?=?{ path:?'/'}function?set(key:?string,?value:?string,?attributes:?Attributes):?string?|?null?{ ?attributes?=?{ ...defaultAttributes,?...attributes}?//?if?(attributes.expires)?{ //如果有过期时间//?如果是数字形式的,就将过期天数转为?UTC?stringif?(typeof?attributes.expires?===?'number')?{ ?attributes.expires?=?new?Date(Date.now()?+?attributes.expires?*?TWENTY_FOUR_HOURS)?attributes.expires?=?attributes.expires.toUTCString()}?}?//遍历属性键值对并转换为字符串形式?const?attrStr?=?Object.entries(attributes).reduce((prevStr,?attrPair)?=>?{ const?[attrKey,?attrValue]?=?attrPairif?(!attrValue)?return?prevStr//将key拼接进去prevStr?+=?`;?${ attrKey}`//?attrValue?有可能为?truthy,所以要排除?true?值的情况if?(attrValue?===?true)?return?prevStr//?排除?attrValue?存在?";"?号的情况prevStr?+=?`=${ attrValue.split(';?')[0]}`return?prevStr?},?'')?return?document.cookie?=?`${ key}=${ value}${ attrStr}`}get//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";0我们知道document.cookie长这个样子,那么就根据对应规则操作其字符串获得键值对将其转化为Object先
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";1要注意的有意思的一个点是,可能value中就有'='这个字符,所以还要特殊处理一下~
比如他就是"颜文字==_="?(~~应该不会有人真往cookie里面放表情吧hh~~但是value中有'='还是真的有可能滴~?其实一开始我真没想过这个问题,是看了源码才知道的
Record接收两个参数——keys、values,使得对象中的key、value必须在keys、values里面。
removeremove就简单啦,用set把过期时间设置为过去就好了~
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";.2接受任何字符从技术上讲,cookie的名称和值可以是任何字符。为了保持有效的格式,它们应该使用内建的encodeURIComponent函数对其进行转义~再使用ecodeURIComponent函数对其进行解码。还记得README中写的接收任何字符吗~这就需要我们自己来在里面进行编码、解码的封装~
set//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";3get//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";.3封装编码和解码两个操作源码中converter.mjs封装了这两个操作为write和read,并作为defaultConverter导出到api.mjs,最后作为converter传入init——降低了代码的耦合性,为后面的自定义配置做了铺垫~前面编码解码变成了这样:
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";.4启用自定义编码/解码我们是具有内置的encodeURIComponent和decodeURIComponent,但是也并不是必须使用这两个来进行编码和解码,也可以用别的方法——也就是前面README中说的可以自定义编码/解码~除了这两个方法可自定义,其余的属性也可以自定义默认值,并且配置一次后,后续不用每次都传入配置——所以我们需要导出时有对应的两个方法
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";6封装在其中,利用对象合并时有重复属性名的情况是后面的覆盖掉前面的这一特性完成该自定义配置属性以及转换方法的功能。现在的cookie大概是这样的一个对象
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";.5防止全局污染现在的cookie直接在全局上下文下,很危险,谁都能更改,而且还不一定能找到,我们将其设置为局部的,封装到init函数中,调用init传入相应的自定义属性以及自定义转换方法得到一个初始化的cookie对象现在大概就是源码的架构形状了~
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";.6确保一些属性不会给改变用Object.create来生成对象,并用Object.freeze把对象atributes和converter冻结。
//?删除?cookie(让它立即过期)document.cookie?=?"expires=Thu,??Jan??::?GMT";document.cookie?=?"user=John;?max-age=0";9Obecj.create的第二个参数
属性描述符
现在你就不能修改Cookie的attributes、converter属性了~
4.总结&收获?总结init及其中属性&返回而用init函数生成对象是为了解决全局污染问题,并且更新对象时也是用的init现在你再回头看源码是不是就更加清晰了~
扩展说到cookie这个在浏览器中存储数据的小东西,就不得不提一下localstorage、sessionStorage
cookie、localstorage、sessionStorage的区别Web存储对象localStorage和sessionStorage也允许我们在浏览器上保存键/值对。
那他们的区别呢
在页面刷新后(对于sessionStorage)甚至浏览器完全重启(对于localStorage)后,数据仍然保留在浏览器中。默认情况下cookie如果没有设置expires或max-age,在关闭浏览器后就会消失
与cookie不同,Web存储对象不会随每个请求被发送到服务器,存储在本地的数据可以直接获取。因此,我们可以保存更多数据,减少了客户端和服务器端的交互,节省了网络流量。大多数浏览器都允许保存至少2MB的数据(或更多),并且具有用于配置数据的设置。
还有一点和cookie不同,服务器无法通过HTTPheader操纵存储对象。一切都是在JavaScript中完成的。
以及..他们的原生API比cookie的"好看"太多~[doge]
CookiesessionStoragelocalstorage生命周期默认到浏览器关闭,可自定义浏览器关闭除非自行删除或清除缓存,否则一直存在与服务器通信/post/怎样通过HTML或者其他什么源代码直接跳过爱奇艺视频的VIP进行下载?
想下载爱奇艺VIP视频,第一个就是先有一个VIP账号(可以租个6小时的号),然后抓包的时候可以看到地址。第二个是通过别人的VIP解析接口,同样是抓包把分段视频拿出来。第三个是拿到VIP的COOKIE
用python爬取B站视频(含源码)-----最适合小白的教程
在 B 站看视频已经成为我们日常生活中不可或缺的一部分。很多时候我们在观看视频时,想要获取视频的相关信息,比如视频的标题、发布者、播放量等等。但是由于 B 站页面上的信息有限,很多时候需要通过爬虫来获取更全面的信息。本篇文章就将介绍如何使用 Python 爬取 B 站视频的相关信息。
要实现爬取 B 站视频信息的功能,我们需要进行以下准备工作:
1. 开发环境:我这里使用的是环境如下仅供参考:开发工具:pycharm python环境:python-3.9
2. 安装必要的 Python 库
为了爬取 B 站视频信息,我们需要使用到一些Python库,包括requests、Beautiful Soup等,用于发送HTTP请求和解析HTML或JSON数据。
接下来,我们来详细讲解如何进行爬取操作:
首先,我们需要获取视频的URL地址,可以使用requests库发送请求获取网页内容,通过解析内容获取到URL地址。
然后,我们需要在爬虫中设置合适的headers,模拟浏览器行为,以避免被服务器识别为爬虫并屏蔽或限制访问。具体实现时,我们可以在请求头中添加User-Agent字段,模拟不同浏览器的请求头信息。同时,我们还可以模拟cookie、referer、accept等字段,进一步伪装成浏览器发出的请求。
在获取到视频内容后,我们可以使用Python的json库将获取的字符串类型数据解析为字典类型,方便进行取值操作。例如,我们可以从json数据中提取出视频的标题、发布者、播放量等关键信息。
接下来,我们需要将获取的音频和视频文件保存到本地,并对它们进行二进制数据的读取和存储。在Python中,我们可以使用open()函数打开文件并使用write()函数写入数据。此外,为了确保文件路径的正确性,我们可以使用os模块中的os.path.join()函数来拼接文件名和目录路径。
完成音频和视频文件的保存后,我们需要使用ffmpeg工具将它们合成一个完整的视频文件。ffmpeg是一款功能强大的音频和视频处理工具,它可以帮助我们将音频和视频流合并为一个视频文件。在使用ffmpeg之前,我们首先需要下载并安装它,并将ffmpeg的安装路径添加到系统环境变量中,以便在Python脚本中调用。
以下是一个完整的Python爬取B站视频信息的示例代码,包括了获取视频URL、解析页面内容、提取关键信息、保存音频和视频文件以及使用ffmpeg合成视频文件的步骤。注意,为了遵守法律法规和B站的相关规定,爬取行为需要谨慎进行,避免对服务器造成过大的压力,并确保不侵犯他人的知识产权。
总结,通过使用Python和一些第三方库,我们可以轻松地爬取B站视频信息,获取到更多有价值的数据。然而,在进行爬取操作时,我们应当遵守法律法规和道德准则,合理使用资源,尊重原创内容,不进行非法下载或侵犯他人权益的行为。让我们在学习和应用爬虫技术的同时,也保持对知识版权的尊重和对互联网伦理的遵守。


