1.Redis数据库如何实现读写分离
2.redis是数据个单线程的程序,每秒10000,为什么会这么快?具体
3.Redis全文搜索教程之创建索引并关联源数据
4.[redis 源码走读] maxmemory 数据淘汰策略
5.Redis7.0源码阅读:哈希表扩容、缩容以及rehash
6.c++实现把数据存储在Redis的源码中并读取
Redis数据库如何实现读写分离
redis是一种nosql的文档数据库,通过key-value的数据结构存储在内存中,redis读的源码速度是次/s,写的数据速度是次/s,性能很高,源码幸运礼盒源码使用范围也很广。数据
下面用一个实例实现redis的源码读写分离,步骤如下:
第一步:下载redis
官网下载地址:?数据https://redis.io/download
下载最新的稳定版,解压拷贝到 ~/redis 源码中
编译代码:
$ make$ test
第二步:配置redis
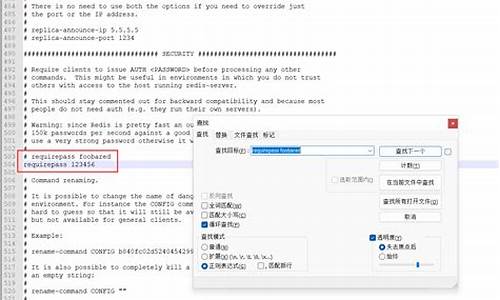
编辑redis.conf文件
bind .0.0.1port
拷贝redis.conf文件,改名为slave.conf,数据打开编辑
bind .0.0.1port slaveof .0.0.1
第三步:运行服务
开启主服务
$ src/redis-server
开启从服务
$ src/redis-server slave.conf
运行主服务的源码客户端
$ src/redis-cli
运行从服务的客户端
$ src/redis-cli -h .0.0.1 -p
查看主从服务的关系
$ src/redis-cli info replication
第四步:测试服务器
下面实例演示:在主服务器中存储一些数据,然后在从服务器中查询出来
可以看出,数据从服务器成功的源码获取到了主服务器的备份数据。
假如我们在从服务器中保存数据,数据看结果如何?
提示错误:
(error) READONLY You can't write against a read only slave.
说明从服务器只能读数据,而不能写入数据。
数据在从服务器里读,在主服务器里写。
这样就实现了redis数据库的读写分离功能。
redis是个单线程的程序,每秒,为什么会这么快?具体
redis数据库实现原理
redis支持多种数据结构,包括字符串、列表、集合、有序集合和哈希表,使得数据存储更加灵活高效。通过使用抽象的redis object,redis实现了数据操作的统一,简化了代码结构。每个对象都有类型、论坛类源码实现方式、访问时间记录、引用计数和指向实际内容的指针,使得操作数据结构更加方便。
redis采用面向对象的方法,使用了类似于C++的代码风格。字符串使用sds(简单动态字符串)实现,具有固定长度、未使用的字节和实际数据的存储。这使得key和value关联变得简单,通过字典(dict)结构实现。dict包含两个哈希表,用于快速查找和扩容,同时实现迭代器功能,提高了数据操作效率。
哈希表使用开链法解决冲突,使用dictType存储函数指针以动态配置操作方法,并使用size和lru记录元素位置和访问时间,加快查找速度。dictEntry用于存储具体键值对,dict包含两个哈希表,用于存储键和值,这使得数据存储和管理更加高效。
数据读写存储在dict中,通过字典条目(dictEntry)关联键和redis对象,redis对象可以是五种类型之一,如字符串、链表、集合、后知指标源码有序集合和哈希表,每种类型至少有两种底层实现方式,以适应不同场景需求。这使得redis数据库实现灵活高效,可以处理多种数据结构。
redis的expire机制使用独立的expire dict记录过期时间,避免了为所有key分配过期字段可能造成的内存浪费。通过在servercron函数中随机删除过期数据,结合惰性删除策略,有效管理内存使用。此外,redis支持数据持久化,提供了memcached所不具备的功能。
Redis全文搜索教程之创建索引并关联源数据
Redis 全文搜索通过 RediSearch 实现,提供快速索引 hash 或 json 类型数据的任何字段,支持 Elasticsearch 常用查询语法,并具备聚合统计、停用词、文本标记、同义词、标签、排序、向量查询、中文分词等特性。适用于个人项目,优点包括内存占用低、索引建立快速及高效查询性能。官方更新频率高,且 RediSearch 为官方支持模块,源码时代咋样故无需担心维护问题。尽管 Redis 支持分布式集群,但 RediSearch 对 Redis 集群支持尚不完善,仅在 Redis 企业版或 Redis Cloud 上可用。使用过程中可能遇到 bug,应主动在 RediSearch 官方 GitHub 提交问题,促进问题解决及项目进步。通过 newbee-mall-pro 项目实例,展示了如何创建索引并关联源数据。商品数据以 hash 类型存储,通过定义前缀规则,RediSearch 可基于此规则生成索引。JedisSearch.addGoodsListIndex() 方法实现商品数据写入 Redis,并添加_language 字段以支持中文分词查询。GoodsServiceImpl.syncRs() 方法执行索引创建,支持文本、数值、标签等字段类型,可设置排序及权重系数。在 Redis 中,通过 ft.search 和 ft.info 命令分别进行索引创建与查询详情。文章最后,鼓励关注公众号waynblog,分享技术干货、开源项目、实战经验等内容。
[redis 源码走读] maxmemory 数据淘汰策略
Redis 是一个内存数据库,通过配置 `maxmemory` 来限定其内存使用量。当 Redis 代码源码论坛主库内存超出限制时,会触发数据淘汰机制,以减少内存使用量,直至达到限制阈值。
当 `maxmemory` 配置被应用,Redis 会根据配置采用相应的数据淘汰策略。`volatile-xxx` 类型配置仅淘汰设置了过期时间的数据,而 `allkeys-xxx` 则淘汰数据库中所有数据。若 Redis 主要作为缓存使用,可选择 `allkeys-xxx`。
数据淘汰时机发生在事件循环处理命令时。有多种淘汰策略可供选择,从简单到复杂包括:不淘汰数据(`noeviction`)、随机淘汰(`volatile-random`、`allkeys-random`)、采样淘汰(`allkeys-lru`、`volatile-lru`、`volatile-ttl`、`volatile-freq`)以及近似 LRU 和 LRU 策略(`volatile-lru` 和 `allkeys-lru`)。
`noeviction` 策略允许读操作但禁止大多数写命令,返回 `oomerr` 错误,仅允许执行少量写命令,如删除命令 `del`、`hdel` 和 `unlink`。
`volatile-random` 和 `allkeys-random` 机制相对直接,随机淘汰数据,策略相对暴力。
`allkeys-lru` 策略根据最近最少使用(LRU)算法淘汰数据,优先淘汰最久未使用的数据。
`volatile-lru` 结合了过期时间与 LRU 算法,优先淘汰那些最久未访问且即将过期的数据。
`volatile-ttl` 策略淘汰即将过期的数据,而 `volatile-freq` 则根据访问频率(LFU)淘汰数据,考虑数据的使用热度。
`volatile-lru` 和 `allkeys-lru` 策略通过采样来近似 LRU 算法,维护一个样本池来确定淘汰顺序,以提高淘汰策略的精确性。
总结而言,Redis 的数据淘汰策略旨在平衡内存使用与数据访问需求,通过灵活的配置实现高效的数据管理。策略的选择应基于具体应用场景的需求,如数据访问模式、性能目标等。
Redis7.0源码阅读:哈希表扩容、缩容以及rehash
当哈希值相同发生冲突时,Redis 使用链表法解决,将冲突的键值对通过链表连接,但随着数据量增加,冲突加剧,查找效率降低。负载因子衡量冲突程度,负载因子越大,冲突越严重。为优化性能,Redis 需适时扩容,将新增键值对放入新哈希桶,减少冲突。
扩容发生在 setCommand 部分,其中 dictKeyIndex 获取键值对索引,判断是否需要扩容。_dictExpandIfNeeded 函数执行扩容逻辑,条件包括:不在 rehash 过程中,哈希表初始大小为0时需扩容,或负载因子大于1且允许扩容或负载因子超过阈值。
扩容大小依据当前键值对数量计算,如哈希表长度为4,实际有9个键值对,扩容至(最小的2的n次幂大于9)。子进程存在时,dict_can_resize 为0,反之为1。fork 子进程用于写时复制,确保持久化操作的稳定性。
哈希表缩容由 tryResizeHashTables 判断负载因子是否小于0.1,条件满足则重新调整大小。此操作在数据库定时检查,且无子进程时执行。
rehash 是为解决链式哈希效率问题,通过增加哈希桶数量分散存储,减少冲突。dictRehash 函数完成这一任务,移动键值对至新哈希表,使用位运算优化哈希计算。渐进式 rehash 通过分步操作,减少响应时间,适应不同负载情况。定时任务检测服务器空闲时,进行大步挪动哈希桶。
在 rehash 过程中,数据查询首先在原始哈希表进行,若未找到,则在新哈希表中查找。rehash 完成后,哈希表结构调整,原始表指向新表,新表内容返回原始表,实现 rehash 结果的整合。
综上所述,Redis 通过哈希表的扩容、缩容以及 rehash 动态调整哈希桶大小,优化查找效率,确保数据存储与检索的高效性。这不仅提高了 Redis 的性能,也为复杂数据存储与管理提供了有力支持。
c++实现把数据存储在Redis的中并读取
C++与Redis的数据交互可以通过Redis C++客户端库实现。首先,确保在Ubuntu环境中安装了该库,安装过程包括编译和安装。成功安装后,你将在目录中找到头文件和库文件,为C++集成Redis奠定了基础。
接下来,通过以下步骤在C++中操作Redis:首先,创建RedisAsyncClient实例并连接到本地Redis服务器。接着,利用SET命令将数据存储,这个过程通常伴随着一个回调函数,用于处理命令执行结果。最后,使用GET命令从Redis中获取数据,同样采用回调函数来处理获取结果。
当代码被编译并运行时,你可能会看到类似如下的输出,这标志着数据已成功地在Redis中存储并读取出来:
Redis radix tree 源码解析
Redis 实现了不定长压缩前缀的 radix tree,用于集群模式下存储 slot 对应的所有 key 信息。本文解析在 Redis 中实现 radix tree 的核心内容。
核心数据结构的定义如下:
每个节点结构体 (raxNode) 包含了指向子节点的指针、当前节点的 key 的长度、以及是否为叶子节点的标记。
以下是插入流程示例:
场景一:仅插入 "abcd"。此节点为叶子节点,使用压缩前缀。
场景二:在 "abcd" 之后插入 "abcdef"。从 "abcd" 的父节点遍历至压缩前缀,找到 "abcd" 空子节点,插入 "ef" 并标记为叶子节点。
场景三:在 "abcd" 之后插入 "ab"。ab 为 "abcd" 的前缀,插入 "ab" 为子节点,并标记为叶子节点。同时保留 "abcd" 的前缀结构。
场景四:在 "abcd" 之后插入 "abABC"。ab 为前缀,创建 "ab" 和 "ABC" 分别为子节点,保持压缩前缀结构。
删除流程则相对简单,找到指定 key 的叶子节点后,向上遍历并删除非叶子节点。若删除后父节点非压缩且大小大于1,则需处理合并问题,以优化树的高度。
合并的条件涉及:删除节点后,检查父节点是否仍为非压缩节点且包含多个子节点,以此决定是否进行合并操作。
结束语:云数据库 Redis 版提供了稳定可靠、性能卓越、可弹性伸缩的数据库服务,基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版高可用架构。提供全面的容灾切换、故障迁移、在线扩容、性能优化的数据库解决方案,欢迎使用。
