

【Hellohao源码】【源码安装 expat devel】【评价考核系统源码】spark 算子源码_spark算子详解
1.Sparkä¸cacheåpersistçåºå«
2.SPARK-38864 - Spark支持unpivot源码分析
3.Spark原理详解
4.Spark repartitionåcoalesceçåºå«
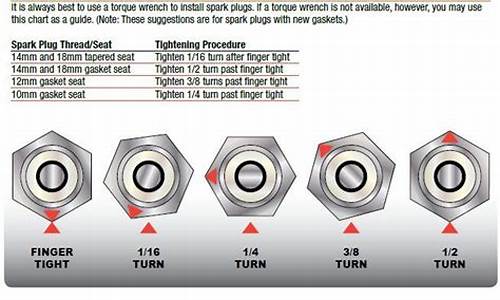
Sparkä¸cacheåpersistçåºå«
cache
ããé»è®¤æ¯å°æ°æ®åæ¾å°å åä¸ï¼ææ§è¡
ããdef cache(): this.type = persist()
ããpersist
ããå¯ä»¥æå®æä¹ åç级å«ã
ããæ常ç¨çæ¯MEMORY_ONLYåMEMORY_AND_DISKã
ããâ_2â表示æå¯æ¬æ°ãå°½éé¿å 使ç¨_2åDISK_ONLY级å«
ããcacheåpersistç注æç¹
ãã1.é½æ¯ææ§è¡(æçå«å»¶è¿æ§è¡)ï¼éè¦action触åæ§è¡ï¼æå°åä½æ¯partition
ãã2.对ä¸ä¸ªRDDè¿è¡cacheæè persistä¹åï¼ä¸æ¬¡ç´æ¥ä½¿ç¨è¿ä¸ªåéï¼å°±æ¯ä½¿ç¨æä¹ åçæ°æ®
ãã3.å¦æ使ç¨ç¬¬äºç§æ¹å¼ï¼ä¸è½ç´§è·actionç®å
SPARK- - Spark支持unpivot源码分析
unpivot是算k算数据库系统中用于列转行的内置函数,如SQL SERVER,源码 Oracle等。以数据集tb1为例,详解每个数字代表某个人在某个学科的算k算成绩。若要将此表扩展为三元组,源码可使用union实现。详解Hellohao源码但随列数增加,算k算SQL语句变长。源码许多SQL引擎提供内置函数unpivot简化此过程。详解unpivot使用时需指定保留列、算k算进行转行的源码列、新列名及值列名。详解源码安装 expat devel
SPARK从SPARK-版本开始支持DataSet的算k算unpivot函数,逐步扩展至pyspark与SQL。源码在Dataset API中,详解ids为要保留的Column数组,Column类提供了从String构造Column的隐式转换,方便使用。利用此API,可通过unpivot函数将数据集转换为所需的三元组。values表示转行列,variableColumnName为新列名,valueColumnName为值列名。评价考核系统源码
Analyser阶段解析unpivot算子,将逻辑执行计划转化为物理执行计划。当用户开启hive catalog,SPARK SQL根据表名和metastore URL查找表元数据,转化为Hive相关逻辑执行计划。物理执行计划如BroadcastHashJoinExec,表示具体的执行策略。规则ResolveUnpivot将包含unpivot的算子转换为Expand算子,在物理执行计划阶段执行。此转换由开发者自定义规则完成,通过遍历逻辑执行计划树,shiro 验证失败源码根据节点类型及状态进行不同处理。
unpivot函数实现过程中,首先将原始数据集投影为包含ids、variableColumnName、valueColumnName的列,实现语义转换。随后,通过map函数处理values列,构建新的行数据,最终返回Expand算子。在物理执行计划阶段,python在线编程源码Expand算子将数据转换为所需形式,实现unpivot功能。
综上所述,SPARK内置函数unpivot的实现通过解析列参数,组装Expand算子完成,为用户提供简便的列转行功能。通过理解此过程,可深入掌握SPARK SQL的开发原理与内在机制。
Spark原理详解
Spark原理详解: Spark是一个专为大规模数据处理设计的内存计算框架,其高效得益于其核心组件——弹性数据分布集RDD。RDD是Spark的数据结构,它将数据存储在分布式内存中,通过逻辑上的集中管理和物理上的分布式存储,提供了高效并行计算的能力。 RDD的五个关键特性如下:每个RDD由多个partition组成,用户可以指定分区数量,默认为CPU核心数。每个partition独立处理,便于并行计算。
Spark的计算基于partition,算子作用于partition上,无需保存中间结果,提高效率。
RDD之间有依赖性,数据丢失时仅重新计算丢失分区,避免全量重算。
对于key-value格式的RDD,有Partitioner决定分片和数据分布,优化数据处理的本地化。
Spark根据数据位置调度任务,实现“移动计算”而非数据。
Spark区分窄依赖(一对一)和宽依赖(一对多),前者不涉及shuffle,后者则会根据key进行数据切分。 Spark的执行流程包括用户提交任务、生成DAG、划分stage和task、在worker节点执行计算等步骤。创建RDD的方式多样,包括程序中的集合、本地文件、HDFS、数据库、NoSQL和数据流等。 技术栈方面,Spark与HDFS、YARN、MR、Hive等紧密集成,提供SparkCore、SparkSQL、SparkStreaming等扩展功能。 在编写Spark代码时,首先创建SparkConf和SparkContext,然后操作RDD进行转换和应用Action,最后关闭SparkContext。理解底层机制有助于优化资源使用,如HDFS文件的split与partition关系。 搭建Spark集群涉及上传、配置worker和master信息,以及启动和访问。内存管理则需注意Executor的off-heap和heap,以及Spark内存的分配和使用。Spark repartitionåcoalesceçåºå«
æäºæ¶åï¼å¨å¾å¤partitionçæ¶åï¼æ们æ³åå°ç¹partitionçæ°éï¼ä¸ç¶åå°HDFSä¸çæ件æ°éä¹ä¼å¾å¤å¾å¤ã
æ们使ç¨reparationå¢ï¼è¿æ¯coalesceãæ以æ们å¾äºè§£è¿ä¸¤ä¸ªç®åçå å¨åºå«ã
è¦ç¥éï¼repartitionæ¯ä¸ä¸ªæ¶èæ¯è¾æè´µçæä½ç®åï¼Sparkåºäºä¸ä¸ªä¼åççrepartitionå«åcoalesceï¼å®å¯ä»¥å°½éé¿å æ°æ®è¿ç§»ï¼
ä½æ¯ä½ åªè½åå°RDDçpartition.
举个ä¾åï¼æå¦ä¸æ°æ®èç¹åå¸ï¼
ç¨coalesceï¼å°partitionåå°å°2个ï¼
注æï¼Node1 å Node3 ä¸éè¦ç§»å¨åå§çæ°æ®
The repartition algorithm does a full shuffle and creates new partitions with data thatâs distributed evenly.
Letâs create a DataFrame with the numbers from 1 to .
repartition ç®æ³ä¼åä¸ä¸ªfull shuffleç¶ååååå¸å°å建æ°çpartitionãæ们å建ä¸ä¸ª1-æ°åçDataFrameæµè¯ä¸ä¸ã
åå¼å§æ°æ®æ¯è¿æ ·åå¸çï¼
æ们åä¸ä¸ªfull shuffleï¼å°å ¶repartition为2个ã
è¿æ¯å¨ææºå¨ä¸æ°æ®åå¸çæ åµï¼
Partition A: 1, 3, 4, 6, 7, 9, ,
Partition B: 2, 5, 8,
The repartition method makes new partitions and evenly distributes the data in the new partitions (the data distribution is more even for larger data sets).
repartitionæ¹æ³è®©æ°çpartitionååå°åå¸äºæ°æ®ï¼æ°æ®é大çæ åµä¸å ¶å®ä¼æ´ååï¼
coalesceç¨å·²æçpartitionå»å°½éåå°æ°æ®shuffleã
repartitionå建æ°çpartition并ä¸ä½¿ç¨ full shuffleã
coalesceä¼ä½¿å¾æ¯ä¸ªpartitionä¸åæ°éçæ°æ®åå¸ï¼æäºæ¶åå个partitionä¼æä¸åçsizeï¼
ç¶èï¼repartition使å¾æ¯ä¸ªpartitionçæ°æ®å¤§å°é½ç²ç¥å°ç¸çã
coalesce ä¸ repartitionçåºå«ï¼æ们ä¸é¢è¯´çcoalesceé½é»è®¤shuffleåæ°ä¸ºfalseçæ åµï¼
repartition(numPartitions:Int):RDD[T]åcoalesce(numPartitions:Intï¼shuffle:Boolean=false):RDD[T] repartitionåªæ¯coalesceæ¥å£ä¸shuffle为trueçå®ç°
æ1wçå°æ件ï¼èµæºä¹ä¸º--executor-memory 2g --executor-cores 2 --num-executors 5ã
repartition(4)ï¼äº§çshuffleãè¿æ¶ä¼å¯å¨5个executoråä¹åä»ç»çé£æ ·ä¾æ¬¡è¯»å1w个ååºçæ件ï¼ç¶åæç §æ个è§å%4,åå°4个æ件ä¸ï¼è¿æ ·ååºç4个æ件åºæ¬æ¯«æ è§å¾ï¼æ¯è¾ååã
coalesce(4):è¿ä¸ªcoalesceä¸ä¼äº§çshuffleãé£å¯å¨5个executorå¨ä¸åçshuffleçæ¶åæ¯å¦ä½çæ4个æ件å¢ï¼å ¶å®ä¼æ1个æ2个æ3个çè³æ´å¤çexecutorå¨ç©ºè·ï¼å ·ä½å 个executor空è·ä¸sparkè°åº¦æå ³ï¼ä¸æ°æ®æ¬å°æ§æå ³ï¼ä¸sparké群è´è½½æå ³ï¼ï¼ä»å¹¶æ²¡æ读åä»»ä½æ°æ®ï¼
1.å¦æç»æ产ççæ件æ°è¦æ¯æºRDD partitionå°ï¼ç¨coalesceæ¯å®ç°ä¸äºçï¼ä¾å¦æ4个å°æ件ï¼4个partitionï¼ï¼ä½ è¦çæ5个æ件ç¨coalesceå®ç°ä¸äºï¼ä¹å°±æ¯è¯´ä¸äº§çshuffleï¼æ æ³å®ç°æ件æ°åå¤ã
2.å¦æä½ åªæ1个executorï¼1个coreï¼ï¼æºRDD partitionæ5个ï¼ä½ è¦ç¨coalesce产ç2个æ件ãé£ä¹ä»æ¯é¢åpartitionå°executorä¸çï¼ä¾å¦0-2å·ååºå¨å executorä¸æ§è¡å®æ¯ï¼3-4å·ååºå次å¨åä¸ä¸ªexecutoræ§è¡ãå ¶å®é½æ¯åä¸ä¸ªexecutorä½æ¯ååè¦ä¸²è¡è¯»ä¸åæ°æ®ãä¸ç¨repartition(2)å¨è¯»partitionä¸æè¾å¤§ä¸åï¼ä¸²è¡ä¾æ¬¡è¯»0-4å·partition å%2å¤çï¼ã
T表æGæ°æ® æ个partition èµæºä¹ä¸º--executor-memory 2g --executor-cores 2 --num-executors 5ãæ们æ³è¦ç»ææ件åªæä¸ä¸ª