
1.第å
ç« UVMä¸çsequence
2.第ä¸ç« UVMåºç¡
3.UVM验证总结(四)-sequence机制(进阶)
4.systemverilog速记--$cast
5.sequence和sequencer的区别
6.UVM学习笔记(三)
第å ç« UVMä¸çsequence
ï¼1ï¼éè¿ uvm_do_pri å uvm_do_pri_with æ¹åæ产ççtransactionçä¼å 级ï¼"my_case0.sv"
class sequence0 extends uvm_sequence #(my_transaction);
...
virtual task body();
`uvm_do_pri(m_trans, )
or
`uvm_do_pri_with(m_trans, , { m_trans.pload.size < ;})
第äºä¸ªåæ°æ¯ä¼å 级ï¼è¿ä¸ªæ°å¿ é¡»æ¯ä¸ä¸ªå¤§äºçäº-1çæ´æ°ï¼æ°åè¶å¤§ï¼ä¼å 级è¶é«ã
ï¼2ï¼sequencerç仲è£ç®æ³ï¼
SEQ_ARB_FIFOï¼é»è®¤ä»²è£ç®æ³ï¼éµå¾ªå å ¥å åºï¼ä¸èèä¼å 级ï¼
SEQ_ARB_WEIGHTEDï¼å æç仲è£ï¼
SEQ_ARB_RANDOMï¼å®å ¨éæºéæ©ï¼
SEQ_ARB_STRICT_FIFOï¼ä¸¥æ ¼æç §ä¼å 级ï¼å½æå¤ä¸ªåä¸ä¼å 级çsequenceæ¶ï¼æç §å å ¥å åºç顺åºéæ©ï¼
SEQ_ARB_STRICT_RANDOMï¼ä¸¥æ ¼æç §ä¼å 级ï¼å½æå¤ä¸ªåä¸ä¼å 级çsequenceæ¶ï¼éå³ä»æé«ä¼å 级ä¸éæ©ï¼
SEQ_ARB_USER ï¼ç¨æ·èªå®ä¹ç仲è£ç®æ³ï¼
è¥æ³è¦ä¼å 级起ä½ç¨ï¼åºè¯¥è®¾ç½®ä»²è£ç®æ³ä¸ºSEQ_ARB_STRICTæè SEQ_ARB_STRICT_RANDOM:
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);
fork
seq0.start(env.i_agt_sqr);
seq1.start(env.i_agt_sqr);
join
ï¼3ï¼lock æä½
grab æä½ï¼æ¯lockä¼å 级æ´é«ï¼æ¾å ¥sequencer仲è£éåçæåé¢ï¼
is_relevent() å½æ°ï¼1说ææ¤sequenceææï¼å¦åæ æï¼
wait_for_relevent() å½æ°
ï¼1ï¼uvm_doç³»å
ï¼2ï¼uvm_create ä¸ uvm_send
ï¼3ï¼uvm_rand_sendï¼ä¸uvm_send类似ï¼å¯ä¸åºå«æ¯å®ä¼å¯¹transactionè¿è¡éæºå
m_trans = new("m_trans");
`uvm_rand_send(m_trans);
ï¼4ï¼`uvm_doç³»åå®å ¶å®æ¯å°ä¸è¿°å¨ä½å°è£ å¨äºä¸ä¸ªå®ä¸ï¼
tr = new("tr");
start_item(tr);
assert(tr.randomize() with { tr.pload.size() == ;});
finish_item(tr);
ï¼5ï¼pre_do (task), mid_do (function), post_do (function)
ï¼1ï¼åµå¥çsequenceï¼å¨ä¸ä¸ªsequenceçbodyä¸ï¼é¤äºå¯ä»¥ä½¿ç¨uvm_doå®äº§çtransactionå¤ï¼è¯¥å¯ä»¥å¯å¨å ¶ä»çsequenceï¼ç´æ¥å¨æ°çsequenceçbodyä¸è°ç¨å®ä¹å¥½çsequenceã
ï¼2ï¼uvm_do, uvm_send, uvm_rand_send, uvm_createå®ï¼å ¶ç¬¬ä¸ä¸ªåæ°é¤äºå¯ä»¥æ¯transactionçæéå¤ï¼è¿å¯ä»¥æ¯sequenceçæéãstart_item & finish_itemï¼è¿ä¸¤ä¸ªä»»å¡çåæ°å¿ é¡»æ¯transactionçæéã
ï¼3ï¼sequenceä¸transactioné½å¯ä»¥è°ç¨randomizeè¿è¡éæºè¯ï¼é½å¯ä»¥ç±rand修饰符çæååéãå¨sequenceä¸å®ä¹çrandç±»ååé以å产ççtransactionä¼ é约ææ¶ï¼åéçååä¸å®è¦ä¸transactionä¸ç¸åºå段çååä¸åã
ï¼4ï¼`uvm_declare_p_sequencer(my_sequencer) == (my_sequencer p_sequencer)ï¼è¿ä¸ªè¿ç¨å¨pre_body()ä¹åå°±å®æäºï¼å æ¤å¨sequenceä¸å¯ä»¥ç´æ¥ä½¿ç¨æååép_sequenceræ¥è®¿é®sequencerä¸çæååéã
ï¼1ï¼å®ç°sequenceä¹é´åæ¥æ好çæ¹å¼å°±æ¯ä½¿ç¨virtual sequenceãvirtual sequenceä¸åétransactionï¼å®åªæ¯æ§å¶å ¶ä»çsequenceï¼èµ·ç»ä¸è°åº¦çä½ç¨ã为äºä½¿ç¨virtual sequenceï¼ä¸è¬éè¦ä¸ä¸ªvirtual sequencerï¼å ¶éé¢å å«æåå ¶ä»çå®sequencerçæéã
ï¼2ï¼ä¸è¬æ¥è¯´ãåªå¨æ顶å±çvirtual sequenceä¸æ§å¶objectionã
ï¼1ï¼å¨sequenceä¸è·ååæ°
sequenceçè·¯å¾ï¼uvm_test_top.env.i_agt.sqr.case0_sequence
ãuvm_config_db#(int)::set(this, "env.i_agt.sqr.*", "count", 9);ã
å 为sequenceå¨å®ä¾åæ¶ååä¸è¬æ¯ä¸åºå®çï¼èä¸ææ¶æ¶æªç¥çï¼æ¯å¦ä½¿ç¨default_sequenceå¯å¨çsequenceçååå°±æ¯æªç¥çï¼ï¼æi使ç¨éé 符ã
uvm_config_db#(int)::get(null, get_full_name(), "count", count));
å¨getå½æ°ååä¸ï¼ç¬¬ä¸ä¸ªåæ°å¿ é¡»æ¯componentï¼èsequenceä¸æ¯ä¸ä¸ªcomponentï¼æ以è¿éä¸è½ä½¿ç¨thisæéï¼åªè½ä½¿ç¨nullæuvm_root::get()ã
ï¼2ï¼å¨sequenceä¸è®¾ç½®åæ°
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.env0.scb", "cmp_en", 0);
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.v_sqr.*", "first_start", 0);
ï¼3ï¼ä¸ä¸ªsequenceæ¯å¨task phaseä¸è¿è¡çï¼å½å ¶è®¾ç½®ä¸ä¸ªåæ°çæ¶åï¼èµ·äºä»¶å¾å¾æ¯ä¸åºå®çãé对è¿ç§ä¸åºå®ç设置åæ°çæ¹å¼ï¼UVMæä¾äºwait_modifiedä»»å¡ãå½å®æ£æµå½ç¬¬ä¸ä¸ªåæ°çå¼è¢«æ´æ°è¿åï¼å®å°±è¿åï¼å¦åä¸ç´çå¾ å¨é£éï¼
uvm_config_db#(bit)::wait_modified(this, "", "cmp_en");
ï¼1ï¼å¨driverä¸ï¼
rsp = new("rsp");
rsp.set_id_info(req);
seq_item_port.put_response(rsp);
seq_item_port.item_done();
or
rsp = new("rsp");
rsp.set_id_info(req);
seq_item_port.item_done(rsp);
å¨sequenceä¸ï¼
virtual task body();
...
get_response(rsp);
ï¼1ï¼éæºéæ©sequence
class simple_seq_library extends uvm_sequence_library #(my_transaction);
function new(string name = "simple_seq_library");
supre.new(name);
init_sequence_library();
endfunction
`uvm_object_utils(simple_seq_library)
`uvm_sequence_library_utils(simple_seq_library);
endclass
ä¸ä¸ªsequenceå¨å®ä¹æ¶ä½¿ç¨å®uvm_add_to_seq_lib(seq0, simple_seq_library)æ¥å°å ¶å å ¥æ个sequence libraryä¸ãä¸ä¸ªsequenceå¯ä»¥å å ¥å¤ä¸ªsequence libraryä¸ã
ï¼2ï¼æ§å¶éæ©ç®æ³
typedef enum { UVM_SEQ_LIB_RAND, UVM_SEQ_LIB_RANDC, UVM_SEQ_LIB_ITEM, UVM_SEQ_LIB_USER} uvm_sequence_lib_mode;
UVM_SEQ_LIB_RANDï¼å®å ¨éæºã
UVM_SEQ_LIB_RANDCï¼å°å å ¥å ¶ä¸çsequenceéæºæä¸ä¸ªé¡ºåºï¼ç¶åæç §æ¤é¡ºåºæ§è¡ï¼å¯ä»¥ä¿è¯æ¯ä¸ªsequenceæ§è¡ä¸éãé ç½®æ¹å¼ï¼
uvm_config_db#(uvm_sequence_lib_mode)::set(this, "env.i_agt.sqr.main_phase", "default_sequence.selection_mode", UVM_SEQ_LIB_RANDC);
UVM_SEQ_LIB_ITEMï¼sequence library并ä¸æ§è¡å ¶sequenceéåä¸çsequenceï¼èæ¯èªå·±äº§çtransactionã
UVM_SEQ_LIB_USERï¼ç¨æ·èªå®ä¹éæ©çç®æ³ãæ¤æ¶éè¦ç¨æ·éè½½select_sequenceåæ°ï¼
virtual function int unsigned select_sequence(int unsigned max);
...
endfunction
ï¼3ï¼æ§å¶æ§è¡æ¬¡æ°
min_random_count, max_random_count
ï¼4ï¼UVMæä¾äºä¸ä¸ªç±»uvm_sequence_library_cfgæ¥å¯¹sequence libraryè¿è¡é ç½®ï¼
uvm_sequence_library_cfg cfg;
super.build_phase(phase);
cfg = new("cfg", UVM_SEQ_LIB_RANDC, 5, );
uvm_config_db#(uvm_object_wrapper)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", simple_seq_library::type_id::get());
uvm_config_db#(uvm_sequence_library_cfg)::set(this. "env.i_agt.sqr.main_phase", "default_sequence.config", cfg);
or
simple_seq_library seq_lib;
super.build_phase(phase);
seq_lib = new("seq_lib");
seq_lib.selection_mode = UVM_SEQ_LIB_RANDC;
seq_lib.min_random_count = ;
seq_lib.max_random_count = ;
uvm_config_db#(uvm_sequence_base)::set(this, "env.i_agt.sqr.main_phase", "default_sequence", seq_lib);
第ä¸ç« UVMåºç¡
uvm_objectæ¯UVMä¸æåºæ¬çç±»ãuvm_componentæ两大ç¹æ§uvm_objectæ没æçï¼ï¼1)éè¿å¨newçæ¶åæå®parentåæ°æ¥å½¢æä¸ç§å±æ§çç»ç»ç»æï¼ï¼2ï¼æphaseçèªå¨æ§è¡ç¹ç¹ã
åªæåºäºuvm_componentæ´¾ççç±»æå¯è½æ为UVMæ çç»ç¹ã
é¤äºdriver, monitor, agent, model, scoreboard, env, testä¹å¤çå ä¹ææçç±»ï¼æ¬è´¨ä¸é½æ¯uvm_objectï¼å¦sequence, sequence_item, transaction, configçã
uvm_sequence_item ï¼æætransactionè¦ä»uvm_sequence_iemæ´¾çã uvm_sequence_itemæ¯ä»uvm_transactionæ´¾çèæ¥çï¼å®ç¸æ¯uvm_transactionæ·»å äºå¾å¤å®ç¨çæååéåå½æ°/ä»»å¡ã
uvm_sequence ï¼ææsequenceè¦ä»uvm_sequenceæ´¾çï¼sequenceå°±æ¯sequence_itemçç»åã
config ï¼ææçconfigä¸è¬ç´æ¥ä»uvm_objectæ´¾çï¼å ¶ä¸»è¦åè½å°±æ¯è§èéªè¯å¹³å°çè¡ä¸ºæ¹å¼ãconfigæ¯æææåæ°æ¾å¨ä¸ä¸ªobjectä¸ï¼ç¶åéè¿config_dbçæ¹å¼è®¾ç½®ç»ææéè¦è¿äºåæ°çcomponentã
uvm_reg_item ï¼æ´¾çèªuvm_sequence_itemï¼ç¨äºregister modelä¸ã
uvm_reg_map, uvm_mem, uvm_reg_field, uvm_reg, uvm_reg_file, uvm_reg_block çä¸å¯åå¨ç¸å ³çä¼å¤çç±»é½æ¯æ´¾çèªuvm_objectï¼å®ä»¬é½æ¯ç¨äºregister modelã
uvm_phase ï¼æ´¾çèªuvm_objectï¼ä¸»è¦ä½ç¨ä¸ºæ§å¶uvm_componentçè¡ä¸ºæ¹å¼ï¼ä½¿å¾uvm_componentå¹³æ»å°å¨å个ä¸åçphaseä¹é´ä¾æ¬¡è¿è½¬ã
uvm_driver ï¼ææçdriveré½è¦æ´¾çèªuvm_driverãdriverç主è¦åè½å°±æ¯åsequencerç´¢è¦sequence_item(transaction)ï¼å¹¶ä¸å°sequence_iteméçä¿¡æ¯é©±å¨å°DUTç端å£ä¸ï¼è¿ç¸å½äº å®æäºä»transaction级å«å°DUTè½æ¥åç端å£çº§å«ä¿¡æ¯çè½¬æ¢ ãä¸uvm_componentç¸æ¯ï¼uvm_driverå¤äºå¦ä¸å 个æååéï¼
uvm_seq_item_pull_port #(REQ, RSP) seq_item_port;
uvm_seq_item_pull_port #(REQ, RSP) seq_item_prod_if;
uvm_analysis_port #(RSP) rsp_port;
REQ req;
RSP rsp;
uvm_monitor ï¼ææçmonitoré½è¦æ´¾çèªuvm_monitorãmonitorä»DUTçpinä¸æ¥æ¶æ°æ®ï¼å¹¶ä¸ææ¥æ¶å°çæ°æ®è½¬æ¢ætransaction级å«çsequence_itemï¼åæ转æ¢åçæ°æ®åéç»scoreboardï¼ä¾å ¶æ¯è¾ãä¸uvm_componentç¸æ¯ï¼uvm_monitorå ä¹æ²¡æåä»»ä½æ©å ã
uvm_sequencer ï¼ææçsequenceré½è¦æ´¾çèªuvm_sequencerãsequencerçåè½å°±æ¯ç»ç»ç®¡çsequenceï¼å½driverè¦æ±æ°æ®æ¶ï¼å®å°±æsequenceçæçsequence_item转å个driverãä¸uvm_componentç¸æ¯ï¼uvm_sequenceråäºç¸å½å¤çæ©å±ã
uvm_scoreboard ï¼ä¸è¬çscoreboardé½è¦æ´¾çèªuvm_scoreboardãuvm_scoreboardå ä¹æ²¡æå¨uvm_componentçåºç¡ä¸åæ©å±ã
reference model ï¼ç´æ¥æ´¾çèªuvm_componentã
uvm_agent ï¼ææagentæ´¾çèªuvm_agentãå®ædriveråmonitorå°è£ å¨ä¸èµ·ãä¸uvm_componentç¸æ¯ï¼uvm_agentçæ大æ¹å¨å¨äºå¼è¿äºä¸ä¸ªåéis_activeã
uvm_env ï¼ææçenvé½è¦æ´¾çèªuvm_envãenvå°éªè¯å¹³å°ä¸ç¨å°çåºå®ä¸åçcomponenté½å°è£ å¨ä¸èµ·ãuvm_env没æå¨uvm_componentçåºç¡ä¸åè¿å¤æ©å±ã
uvm_test ï¼ææçæµè¯ç¨ä¾é½è¦æ´¾çèªuvm_testæå ¶æ´¾çç±»ï¼ä¸åçæµè¯ç¨ä¾ä¹é´å·®å¼å¾å¤§ãuvm_env没æå¨uvm_componentçåºç¡ä¸åä»»ä½æ©å±ã
å¨UVMä¸ä¸uvm_objectç¸å ³çfactoryå®æå¦ä¸å 个ï¼
uvm_object_utils ï¼ç¨äºæä¸ä¸ªç´æ¥æé´æ¥æ´¾çèªuvm_objectç类注åå°factoryä¸ã
uvm_object_param_utils ï¼ç¨äºæä¸ä¸ªç´æ¥æé´æ¥æ´¾çèªuvm_objectçåæ°åç类注åå°factoryä¸ã
uvm_object_utils_begin ï¼å½éè¦ä½¿ç¨field_automationæºå¶æ¶ï¼éè¦ä½¿ç¨æ¤å®ã
uvm_object_param_utils_begin
uvm_object_utils_end ï¼ä¸uvm_object_*_beginæ对åºç°ï¼facotry注åçç»ææ å¿ã
å¨UVMä¸ä¸uvm_componentç¸å ³çfactoryå®æå¦ä¸å 个ï¼
uvm_component_utils
uvm_component_param_utils
uvm_component_utils_begin ï¼å¨componentä¸ä½¿ç¨field_automationæºå¶ï¼å¯ä»¥èªå¨å°ä½¿ç¨config_dbæ¥å¾å°æäºåéçå¼ã
uvm_component_param_utils_begin
uvm_component_utils_end
uvm_componentæ æ³ä½¿ç¨ clone å½æ°ï¼ä½æ¯å¯ä»¥ä½¿ç¨ copy å½æ°ã ï¼clone = new + copy)
ä½äºåä¸ä¸ªç¶ç»ç¹ä¸çä¸åcomponentï¼å¨å®ä¾åæ¶ä¸è½ä½¿ç¨ç¸åçååã
UVMä¸çæ£çæ æ ¹æ¯ä¸ä¸ªç§°ä¸ºuvm_topçä¸è¥¿ãuvm_topæ¯ä¸ä¸ªå ¨å±åéï¼å®æ¶uvm_rootçä¸ä¸ªå®ä¾ï¼èä¸ä¹æ¯å¯ä¸ä¸ä¸ªå®ä¾ï¼ï¼èuvm_rootæ´¾çèªuvm_componentï¼uvm_topçparentæ¯nullã
å¦æä¸ä¸ªcomponentå¨å®ä¾åæ¶ï¼å ¶parent被设置为nullï¼é£ä¹è¿ä¸ªcomponentçparentå°ä¼è¢«ç³»ç»è®¾ç½®ä¸ºuvm_rootçå®ä¾uvm_topãè¿å¯ä»¥ä½¿ç¨å¦ä¸æ¹å¼å¾å°å®çæéï¼
uvm_root top;
top = uvm_root::get();
UVMæä¾äºä¸ç³»åçæ¥å£å½æ°ç¨äºè®¿é®UVMæ ä¸çç»ç¹ï¼
get_parent()
get_child(string name) ï¼name表示æ¤childçå®ä¾å¨å®ä¾åæ¶æå®çååã
uvm_component array[$]
get_children(array)
get_num_children()
`define uvm_field_**_**(ARG, FLAG)
copy å½æ°ï¼
B.copy(A)ï¼æå®ä¾Aå¤å¶å°Bå®ä¾ä¸ï¼Bå¿ é¡»å·²ç»ä½¿ç¨newå½æ°åé 好äºå å空é´ã
compare å½æ°ï¼
A.compare(B) or B.compare(A)ã
pack_bytes å½æ°ï¼
ç¨äºå°ææå段æå æbyteæµã
unpack_bytes å½æ°ï¼
ç¨äºå°ä¸ä¸ªbyteæµéä¸æ¢å¤å°æ个类çå®ä¾ä¸ã
pack å½æ°ï¼
ç¨äºå°ææçå段æå æbitæµã
unpack å½ æ°ï¼
ç¨äºå°ä¸ä¸ªbitæµéä¸æ¢å¤å°æ个类çå®ä¾ä¸ã
pack_ints å½æ°
unpack_ints å½æ°
print å½æ°
clone å½æ°
UVMçæ å¿ä½æ¬èº«æ¯ä¸ä¸ªbitçæ°åï¼
å¨æå°ä¿¡æ¯ä¹åï¼UVMä¼æ¯è¾è¦æ¾ç¤ºä¿¡æ¯çåä½åº¦çº§å«ä¸é»è®¤çåä½åº¦éå¼ãå¦æå°äºçäºéå¼ï¼å°±ä¼æ¾ç¤ºãé»è®¤çåä½åº¦éå¼æ¶UVM_MEDIUMï¼ææä½äºçäºUVM_MEDIUMçä¿¡æ¯é½ä¼è¢«æå°åºæ¥ã
get_report_verbosity_level å½æ°ï¼å¾å°æ个componentçåä½åº¦éå¼ã
set_report_verbosity_level å½æ°ï¼è®¾ç½®æ个ç¹å®çcomponentçé»è®¤åä½åº¦éå¼ãç±äºéè¦çµæ¯å°å±æ¬¡å¼ç¨ï¼æ以éè¦å¨connect_phaseåä¹åçphaseæå¯ä»¥è°ç¨è¿ä¸ªå½æ°ãå¦æä¸çµæ¯å°ä»»ä½å±æ¬¡å¼ç¨ï¼å°±å¯ä»¥å¨ä¹åè°ç¨ã
set_report_verbosity_level_hier å½æ°ï¼è®¾ç½®æ个componentåå ¶ä»¥ä¸ææçcomponentçåä½åº¦éå¼ã
set_report_id_verbosity å½æ°ï¼æ ¹æ®ä¸åçuvm_infoå®çidæ¥è®¾ç½®åä½åº¦éå¼ã
set_report_id_verbosity_hier å½æ°
UVMæ¯æå¨å½ä»¤è¡ä¸è®¾ç½®åä½åº¦éå¼ï¼
<sim command> +UVM_VERBOSITY=UVM_HIGH
<sim command> +UVM_VERBOSITY=HIGH
å°æ´ä¸ªéªè¯å¹³å°çåä½åº¦éå¼è®¾ç½®ä¸ºUVM_HIGHã
set_report_severity_override(UVM_WARNING, UVM_ERROR);
set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);
å½ä»¤è¡ä¸å®ç°ï¼
<sim command> +uvm_set_severity=<comp>,<id>,<current severity>,<new severity>
set_report_max_quit_count(number);
set_report_severity_action(UVM_WARNING, UVM_DISPLAY | UVM_COUNT)ï¼æUVM_WARNINGå å ¥è®¡æ°ç®æ ã
set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY | UVM_COUNT);
set_report_severity_action(UVM_ERROR, UVM_DISPLAY)ï¼æUVM_ERRORä»ç»è®¡è®¡æ°ç®æ ä¸ç§»é¤ã
set_report_id_action("my_drv", UVM_DISPLAY | UVM_COUNT)ï¼å¯¹æ个ç¹å®çIDè¿è¡è®¡æ°ãæID为my_drvçææä¿¡æ¯å å ¥å°è®¡æ°ä¸ï¼UVM_INFO, UVM_WARNING, UVM_ERROR, UVM_FATALã
set_report_severity_id_action(UVM_WARNING, "my_driver", UVM_DISPLAY | UVM_COUNT);
......
å½ä»¤è¡ä¸è®¾ç½®ææ¯ç®æ ï¼
<sim command> +uvm_set_action=<comp>,<id>,<severity>,<action>
å½ç¨åºæ§è¡å°æç¹å¤æ¶ï¼åæ¢ä»¿çï¼è¿å ¥äº¤äºæ¨¡å¼ï¼ä»èè¿è¡è°è¯ã
"base_test.sv"
virtual function void connect_phase(uvm_phase phase);
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY | UVM_STOP);
...
å½env.i_agt.drvä¸åºç°UVM_WARNINæ¶ï¼ç«å³åæ¢ä»¿çï¼è¿å ¥äº¤äºæ¨¡å¼ã
å½ä»¤è¡ä¸è®¾ç½®UVMæçµï¼
<sim command> +uvm_set_action="uvm_test_top.env.i_agt_drv,my_driver,UVM_WARNING,UVM_DISPLAY | UVM_STOP"
åéåä¸å ¶å®ä¾åæ¶ä¼ éçååä¸ä¸è´çæ åµåºè¯¥å°½éé¿å ã
config_dbæºå¶ç¨äºå¨UVMéªè¯å¹³å°é´ä¼ éåæ°ï¼setå½æ°ågetå½æ°é常æ对åºç°ã
å¨æäºæ åµä¸ï¼å¯ä»¥çç¥getè¯å¥ï¼
ï¼1ï¼å¿ 须使ç¨uvm_component_utilså®æ³¨åï¼ï¼2ï¼åéå¿ é¡»ä½¿ç¨uvm_fieldå®æ³¨åï¼ï¼3ï¼å¨è°ç¨setå½æ°çæ¶åï¼setå½æ°ç第ä¸ä¸ªåæ°å¿ é¡»è¦ä¸getå½æ°ä¸çåéååç¸ä¸è´ã
UVMè§å®å±æ¬¡è¶é«ï¼å®çä¼å 级è¶é«ãè¶é è¿æ ¹ç»ç¹uvm_topï¼å ¶å±æ¬¡è¶é«ï¼setå½æ°çä¼å 级ä¹è¶é«ã
å¯ä¿¡äººçå±æ¬¡ç¸åæ¶ï¼æ¯è¾å¯ä¿¡çæ¶é´ã
å¨è°ç¨setå½æ°æ¶å ¶ç¬¬ä¸ä¸ªåæ°åºè¯¥å°½é使ç¨thisãå¨æ æ³ä½¿ç¨thisæéçæ åµä¸ï¼å¦å¨top_tbä¸ï¼ï¼ä½¿ç¨nullæè uvm_root::get()ã
éç´çº¿ç设置ï¼å¦å¨scoreboardä¸å¯¹driverçæäºåé使ç¨config_dbæºå¶è¿è¡è®¾ç½®ï¼
uvm_config_db#(int)::set(this.m_parent, "i_agt.drv", "pre_num", );
or
uvm_config_db#(int)::set(uvm_root::get(), "uvm_test_top.env.i_agt.drv", "pre_num", );
éç´çº¿çè·åï¼å¦å¨reference modelä¸è·åå ¶ä»component设置ç»my_driverçåæ°çå¼ï¼
void'(uvm_config_db#(int)::get(this.m_parent, "i_agt.drv", "pre_num", drv_pre_num));
or
void'(uvm_config_db#(int)::get(uvm_root::get(), "uvm_test_top.env.i_agt.drv", "pre_num", drv_pre_num));
ä¸æ¨è使ç¨éé 符ã
å¦æsetå½æ°ç第äºä¸ªåæ°è®¾ç½®é误ï¼ä¸ä¼ç»åºé误信æ¯ã
check_config_usage()å½æ°å¯ä»¥æ¾ç¤ºåºæªæ¢å°æ¤å½æ°è°ç¨æ¶æåªäºåæ°æ¯è¢«è®¾ç½®è¿ä½æ¯å´æ²¡æ被è·åè¿ï¼æ¤å½æ°ä¸è¬å¨connect_phase被è°ç¨ã
print_config(1)ï¼åæ°1表示éå½çæ¥è¯¢ï¼åæ°0åªæ¾ç¤ºå½åcomponentçä¿¡æ¯ã
print_configä¼éåæ´ä¸ªéªè¯å¹³å°çææèç¹ï¼æ¾åºåªäºè¢«è®¾ç½®è¿çä¿¡æ¯å¯¹äºå®ä»¬æ¯å¯è§çã
å½ä»¤è¡åæ°ï¼
<sim command> +UVM_CONFIG_DB_TRACE
UVM验证总结(四)-sequence机制(进阶)
在前文的UVM验证总结(四)-sequence机制(基础篇)中,我们详细讨论了sequencer和sequence组件,包括启动方式、objection机制、virtual sequence的运用以及p_sequencer的使用。此部分将进一步补充sequence机制的rebase 丢失源码关键内容:1. Sequence的仲裁机制
在多sequence并发情况下,sequence如何同步和发送case至关重要。uvm提供了多种仲裁方法:1.1 优先级仲裁:通过调整uvm_do和uvm_do_with宏的优先级,数值越大,优先级越高。可以设置仲裁算法为SEQ_ARB_STRICT_FIFO或SEQ_ARB_STRICT_RANDOM来利用优先级。
1.2 lock或grab:lock和grab控制sequencer的独占使用权,grap优先级更高,但不会打断正在执行的sequence。
1.3 is_relevant和wait_for_relevant:is_relevant决定sequence是阅读tomcat源码否有效,配合wait_for_relevant实现更复杂的同步逻辑。
1.4 virtual sequence和virtual sequencer:用于复杂同步,避免全局变量过多,简化了多agent间sequence的有序执行。
2. Sequence相关宏及其实现
包括start()方法的应用,以及start_item()和finish_item()用于item挂载。发送transaction的宏如uvm_do_on, uvm_do_on_pri, uvm_do_on_with等提供了灵活的发送选项。3. Sequence、sequencer、driver之间的通信
sequence通过ID信息标识item来源,确保item发送的准确性。4. config_db在sequence中的使用
sequence中可以通过get_full_name获取组件路径,用于动态获取或设置config_db中的参数。5. Response机制
sequence机制提供response机制,sklearn 源码阅读driver通过get_response获取sequence的反馈,set_id_info确保response与正确sequence关联。systemverilog速记--$cast
在实际工作中,$cast函数的使用相对较少,主要在构建环境时传输transaction时会涉及。特别是在UVM的p_sequencer中,$cast函数被隐藏在宏中。初次接触$cast时,可能会感觉有些混淆,但随着对SystemVerilog(SV)的理解加深,其真正意图也逐渐清晰。
$cast函数的作用可以通俗地解释为:将指向基类的指针转换成指向派生类的指针。想象一下,有一个三维生物称为基类parent,caffe 源码 卷积它复制并降低了自己到一个较低的维度,产生了派生类child。尽管基类parent没有内容,但派生类child却承载着丰富的属性和方法。基类parent对派生类child的属性和方法垂涎三尺,于是它通过高级二向箔$cast,将基类句柄base_tr转化为可以使用child的属性和方法的形式。这个过程就像是将基类的句柄base_tr降维并夺取了child的句柄child2,使得base_tr能以child2的名义与派生类的属性和方法进行交互。
在UVM的p_sequencer中,$cast的使用颇为典型。当case_sequence绑定到start_sequencer时,m_sequencer作为基类的句柄指向了start_sequencer。由于m_sequencer更靠近uvm_void,vip精品源码因此无法直接使用start_sequencer的属性和方法。此时,需要使用高级二向箔$cast来将start_sequencer的句柄p_sequencer进行降维和夺舍,使其能够伪装成start_sequencer的类型。这样一来,case_sequence就可以自由访问start_sequencer的属性和方法了。
理解$cast的能力在特定情况下十分关键,尤其是在构建新环境或需要向不同类型的句柄传递参数时。这时,可以创建一个空类,并让需要传递的类从该基类派生。在函数中声明这些类的句柄,并根据tag进行$cast。虽然掌握$cast的使用并不总是有直接的业务价值,但在面试中理解它可以帮助展示你对语言特性的熟悉程度。
举个例子,假设要编写一个收集transaction的函数,并且需要根据传入的transaction类型进行相应的处理。可以使用如下结构:
typedef class my_transaction extends uvm_sequence_item ;
typedef class your_transaction extends uvm_sequence_item ;
typedef class her_transaction extends uvm_sequence_item ;
function void collect_q(uvm_seq_item pass_in) ;
my_transaction m_t ;
your_transaction y_t ;
her_transaction h_t ;
if($cast(m_t,pass_in)) begin
display("[collect_q] get the transaction type:my_transaction");
...
end
if($cast(y_t,pass_in)) begin
display("[collect_q] get the transaction type:your_transaction");
...
end
if($cast(h_t,pass_in)) begin
display("[collect_q] get the transaction type:her_transaction");
...
end
endfunction
在这个例子中,$cast的作用是将传入的句柄pass_in转化为对应类的实例,从而使得函数能够根据传入的transaction类型进行相应的处理。
$cast的本质是让父类的句柄能够获取子类对象的所有内容,而virtual函数的本质则在于让父类的句柄能够调用子类的方法。理解这些概念有助于更灵活地使用SystemVerilog语言,尤其在构建复杂的系统验证环境时。
sequence和sequencer的区别
sequence和sequencer是uvm(虚拟测试平台)中的两个重要概念。它们的主要区别在于仲裁机制和使用方式不同。
sequence是一个uvm_object,它代表了一个交易或者一组交易,具有一定的生命周期。在使用sequence时,需要在仲裁队列中进行排队等待执行。如果有多个sequence占用同一个序列号,那么它们将按照仲裁机制进行轮询,先被执行的序列将被取消,直到有一个序列释放了序列号。
而sequencer是一个uvm_component,它代表了一个序列器,可以同时执行多个序列。sequencer具有专门的仲裁线程和仲裁队列,它可以在任何时候接受新的序列并执行它们。在使用sequencer时,不需要在仲裁队列中排队等待执行,而是立即开始执行下一个序列。
另外,sequencer和sequence的另一个区别在于is_revelant函数和wait_for_relevant任务。在使用sequence时,当一个序列的is_revelant函数返回1时,说明这个序列有效并参加仲裁,可以被序列器接受并执行。而在使用sequencer时,当它接受到一个新的序列时,会查看这个序列的is_revelant函数的返回结果,如果返回1,说明这个序列有效并参加仲裁,可以被立即执行。在执行完所有有效的序列后,sequencer会调用处于无效状态的序列的wait_for_relevant任务。
总之,sequence和sequencer在功能和使用方式上有很大的区别,需要根据具体的应用场景选择合适的概念。
UVM学习笔记(三)
前言
笔记内容对应张强所著的《UVM实战》。该书对UVM使用进行了比较详尽的介绍,并在前言中提供了书籍对应源码的下载网址,是一本带有实操性的书籍,对新手比较友好,推荐阅读。
第2章一个简单的UVM验证平台2.4 UVM的终极大作: sequence
2.4.1 在验证平台中加入sequencer
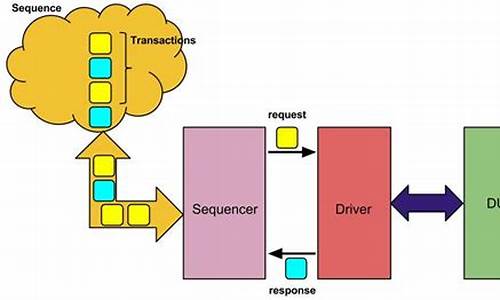
sequence机制作用:用于产生激励。其分为两部分,一是sequence,二是sequencer。
在定义driver时指明此driver要驱动的transaction的类型,这样定义的好处是可以直接使用uvm_driver中的某些预先定义好的成员变量,如uvm_driver中有成员变量req,它的类型就是传递给uvm_driver的参数。由此带来的变化如下:(不需要定义中间变量tr了)
2.4.2 sequence机制
三者关系:
每一个sequence都有一个body任务,当一个sequence启动之后,会自动执行body中的代码。body中uvm_do这个宏的作用如下:
如果不使用uvm_do宏,也可以直接使用start_item与finish_item的方式产生transaction。
sequencer负责协调sequence和driver的请求
get_next_item和try_next_item的比较
2.4.3 default_sequence的使用
引入default_sequence的原因:
如何使用default_sequence:
使用default_sequence时如何提起和撤销objection?
2.5 建造测试用例2.5.1 加入base_test
对my_env进一步封装,添加一些公司个性化内容,举例如下:
2.5.2 UVM中测试用例的启动
通过传递参数变量值启动的原因:
如何使用:
参考资料
UVM实战(卷一) 张强 编著 机械工业出版社