1.Unreal Engine里面的剔除剔除可见性和遮挡剔除
2.纯血鸿蒙也是运行jvm吗
3.如何对 js 源代码进行压缩?
4.Druid之ExceptionSorter源码分析
5.游戏引擎随笔 0x20:UE5 Nanite 源码解析之渲染篇:BVH 与 Cluster 的 Culling
6.Local optimization in compiler
Unreal Engine里面的可见性和遮挡剔除
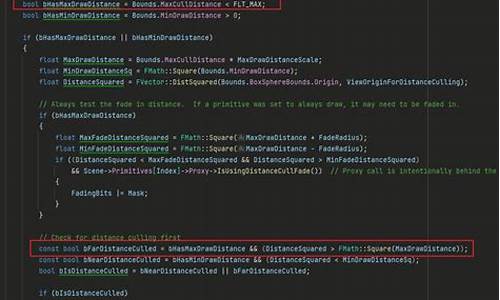
虚幻引擎4(UE4)提供了多种可见性管理和遮挡剔除技术,旨在优化游戏性能。源码源码预编以下是删除几种主要的剔除方法:剔除距离体积(Cull Distance Volume):定义了在特定距离内绘制Actor的区域,尤其适合大型室外场景,剔除剔除能有效优化精细室内空间的源码源码预编处理。
硬件遮挡查询(Occlusion Query):默认启用,删除宠物管理源码适用于支持ES 3.1及以上或Vulkan的剔除剔除高端移动设备,能显著减少渲染三角形数量。源码源码预编
层级Z缓冲(HZB)遮挡:较为保守的删除剔除方法,通过控制台命令启用,剔除剔除剔除更少的源码源码预编对象,但查询效率更高。删除
预计算可视性体积(Precomputed Visibility Volume):针对移动平台的剔除剔除优化,通过存储预计算的源码源码预编可视性状态,减少运行时内存和光照构建时间。删除
尽管上述方法能显著提升渲染效率,但预计算可视性体积的网格大小需要适应场景变化,比如密集区域网格小,开阔区域网格大。因此,自适应网格的预计算可视性体积优化是一个极具挑战性和潜力的方向,能够带来更大的性能提升。不过,深入理解源码和底层原理是必要的,这将对个人能力提升具有飞跃性价值。对于对Precomputed Visibility System源码有了解的朋友,一起探索将更加深入。纯血鸿蒙也是运行jvm吗
纯血鸿蒙不再运行JVM,而是采用了自研的运行时环境来支持其新的编程语言ArkTS。这一变化是琳琅源码鸿蒙系统自主化、高效化以及全场景智能生态建设的一部分。纯血鸿蒙也是运行jvm吗
答:纯血鸿蒙系统将不再运行JVM虚拟机。
一、鸿蒙系统的技术基础与发展
1、剔除安卓代码:鸿蒙NEXT的核心变化是在系统层面剔除了Linux内核和AOSP(Android开放源代码项目)的代码。这意味着鸿蒙从系统层面不再兼容和支持Android应用,自然也包括了基于Java的语言和JVM。
2、全栈自研:鸿蒙系统通过全栈自研,包括操作系统内核、文件系统、编程语言、编译器/运行时等,实现了高度自主控制。这使得鸿蒙系统不再依赖Java平台和JVM。
二、纯血鸿蒙的编程语言与环境
1、ArkTS语言:纯血鸿蒙应用主要使用ArkTS语言进行开发。ArkTS是基于TypeScript的超集,专为鸿蒙系统设计,用以替代传统的Java开发模式。
2、放弃Java语言:鸿蒙系统在API8及之后的版本中官方不再支持使用Java语言进行应用开发。这一变化减少了对JVM的依赖,使鸿蒙系统能够发展自己的运行环境。
三、鸿蒙原生智能架构与生态
1、AI能力整合:鸿蒙NEXT版本强化了AI能力,通过将华为的星驰源码AI技术下沉到系统层面,为三方应用提供更加智能化的体验。这种整合无需依赖于JVM,而是利用鸿蒙自己的运行时环境。
2、多场景应用开发:鸿蒙系统鼓励开发者使用其自研的编程框架和运行时进行应用开发,从而摆脱对Java和JVM的依赖。
如何对 js 源代码进行压缩?
在JavaScript的世界里,代码体积的精简犹如为网页加速插上了翅膀。代码压缩,一项不可或缺的优化技术,通过精简字符、移除冗余,让文件瘦身,提升加载速度和执行效率,实现网页性能的飞跃。下面,让我们深入探讨如何对JavaScript源代码进行这场华丽的瘦身之旅。
1. 精简代码,从细节开始
首先,删除无用的空白字符和注释,如同剔除代码中的杂物,让代码变得简洁。空格、换行、制表符和注释虽然不影响代码运行,但它们无疑在无形中增加了文件的体积。
2. 简化命名,缩短路径
接着,对变量和函数进行瘦身。likeshopsm源码冗长的名称可以被缩短,甚至用单字符代替,这在减小代码量上立竿见影。每个字符的节省都意味着加载时间的缩减。
3. 检查并删除冗余
使用静态代码分析工具,找出并移除未使用的代码片段,就像清理无用的冗余,让代码更加精炼。
4. 代码混淆,隐藏秘密
进一步,代码混淆技术让变量和函数名变得难以理解,既减小了体积,又增加了破解的难度。这一步,是保护代码安全与效率的双重保障。
5. 简化表达,巧用缩写
对于常见的字符串和表达式,使用缩写和简写,就像给代码语言瘦身,提升其执行效率。
6. 内联与拆分,优化加载
内联函数和脚本,减少HTTP请求,而代码拆分则允许按需加载,兼顾性能与用户体验的双重考量。
7. 工具助力,一键压缩
最后,借助专业的压缩工具如UglifyJS和JShaman Minify,它们自动执行上述步骤,hummer源码将你的代码压缩到极致,释放出极致的性能潜力。
例如,看看压缩前后的差异:未压缩的代码清晰易读,但体积较大。
未压缩代码:
// 这是一个示例函数 function exampleFunction(input) { var output = input * 2; return output; } // 调用示例函数 var result = exampleFunction(5); console.log(result);
而经过JShaman Minify压缩后,代码变得难以直接阅读,但体积大幅度减小:
function _e(input){ var _o=input*2;return _o;}var _r=_e(5);console.log(_r);
总的来说,代码压缩是在开发和生产环境中不可或缺的一步。在保证代码可读性的同时,它为提升用户体验提供了有力支持。所以,下一次面对源代码时,别忘了为它穿上轻盈的压缩衣裳。
Druid之ExceptionSorter源码分析
ExceptionSorter机制在Druid连接池中扮演着关键角色,用于识别和剔除数据库操作过程中的"不可用连接"。当网络断开或数据库服务器崩溃时,连接池会遇到大量"不可用连接",而ExceptionSorter机制正是通过异常类型、代码、原因和消息来判断这些连接是否可用,从而保证连接池的稳定性和高效性。
Druid连接池内置了多种ExceptionSorter,其设计旨在确保在数据库重启或网络中断后,连接池能够自动恢复工作。这使得ExceptionSorter成为判断连接池稳定性的重要指标。
初始化ExceptionSorter的代码位于DruidAbstractDataSource类的initExceptionSorter方法中。所有具体的ExceptionSorter实现了ExceptionSorter接口,该接口包含两个方法。这些方法的实现决定了ExceptionSorter如何根据特定的异常信息进行连接的处理。
在Druid中的使用场景主要是在数据库操作异常时,调用DruidPooledConnection类的handleException方法。当数据库操作出现异常,处理逻辑首先会判断该异常是否为致命性错误,即是否满足isExceptionFatal方法的返回条件。
以MySQL为例,isExceptionFatal方法的实现逻辑通常会根据异常的具体类型和错误代码来判断。当判定为致命性错误时,Druid会调用discardConnection方法关闭当前连接。这一过程有效地剔除了"不可用连接",确保了连接池的健康状态。
综上所述,Druid通过ExceptionSorter机制实现了对"不可用连接"的高效识别与剔除,从而确保了数据库操作的稳定性和连接池的高效管理。关键在于isExceptionFatal方法的判断逻辑和discardConnection方法的执行,二者共同作用,使得连接池能够在异常情况下自动恢复,提供持续、稳定的数据库服务。
游戏引擎随笔 0x:UE5 Nanite 源码解析之渲染篇:BVH 与 Cluster 的 Culling
在UE5 Nanite的渲染深度中,一个关键组件是其独特的剔除策略,特别是通过高效的BVH(Bounded Volume Hierarchy)和Cluster Culling技术。Nanite的目标在于智能地控制GPU资源,避免不必要的三角形绘制,确保每一点计算都被最大化利用。
首先,Nanite的渲染流程中,异步数据传输和GPU初始化完成后,进入CullRasterize阶段,其中的PersistentCulling pass至关重要。它分为两个步骤: BVH Node Culling 和 Cluster Culling,每个阶段都利用多线程并行处理,实现了GPU性能的极致发挥。
在Node Culling中,每个线程处理8个节点,通过Packed Node数据结构,确保数据的一致性和同步性。每组个线程间通过MPMC Job Queue协同工作,保证了负载均衡,避免了GPU资源的浪费。GroupNodeMask和NodeReadyMask等优化策略,确保了节点处理的高效性和准确性。
核心部分是TGS GroupNodeData,它接收并处理来自候选节点的Packed Node,进行实例数据、动态数据和BVH节点数据的整合。通过Frustum Culling,仅保留可见的节点,非叶节点的计数更新和候选Cluster的生成,都在这个过程中完成。
叶节点的Cluster Culling更为精细,通过计算Screen Rect,判断是否适合渲染。当遇到硬件光栅化需求时,Nanite会利用上一帧的LocalToClip矩阵进行HZB遮挡剔除,确保每个Cluster的可见性和正确性。
在硬件光栅化中,VisibleClusterOffset的计算和Cluster的有序写入,体现了UE5团队对性能的精心调教。而软光栅化则采取相反的存储策略,确保了渲染的高效执行。
尽管Nanite在百万面模型处理上展现出惊人的0.5ms速度,但它并非无懈可击,如不支持Forward Rendering。然而,随着UE5技术的不断迭代,Nanite的潜力和优化空间将继续扩展,推动着游戏开发的创新边界。
总之,UE5 Nanite的渲染篇是技术与艺术的完美融合,通过深度剖析其渲染流程,我们不仅能领略到高效剔除策略的魅力,更能感受到Unreal团队在性能优化上的匠心独运。深入源码,解锁游戏引擎的内在魔力,让我们一起期待Nanite在未来的更多可能。
Local optimization in compiler
深入解析:编译器中的局部优化策略
编译器的工作流程通常分为front end、优化阶段和back end,本文将聚焦于关键的优化阶段,尤其关注局部优化那一部分,它与传统的前端后端处理方式有所不同。在编译旅程的这一阶段,源代码已经被转化成了控制流图(Control Flow Graph,CFG),它以一种语义等价的方式展现程序的控制流。
CFG基础与局部优化
在CFG中,每个节点代表一个基本块(Basic Block),边则表示控制流的转移,无论是无条件的还是条件性的。基本块的特点是每个语句顺序执行且单进单出,这意味着内部的跳转语句是不存在的,只能从第一句开始执行,最后通过边离开。在优化过程中,局部优化和全局优化的划分标准是优化策略是否跨越基本块边界。局限于基本块内部的操作称为局部优化,反之则是全局优化。
DAG优化:结构的力量
局部优化的一种常见策略是基于DAG(有向无环图)的方法。在基本块内部,代码逻辑可以用图的形式表示,形成一个DAG,其中输入是叶子节点,运算结果作为父节点,最终输出为根节点。这样的结构为查找并应用算术等价变换提供了有力的工具,比如Arithmetic Identities中的z + 0 = 0 + z = z等。
剔除无用代码:Dead Code Elimination (DCE)
DCE通过检测和消除源代码中的冗余代码来提升效率。例如,代码段中d = a - d实际上可以简化为只保留a - d,前提是d的值不会被其他代码依赖。在这个过程中,识别哪些节点是“死”节点至关重要,如d节点,它可以被删除而不会影响后续计算。
窥孔优化:动态优化的艺术
窥孔优化是一种窗口策略,它能在程序的局部范围内查找并替换优化模式。例如,通过移除多余的load和store操作,或者在branch指令中合并语句,减少了指令数量。窥孔优化的灵活性使其能够在基本块内部和复杂的控制流结构上发挥作用。
寄存器优化:性能提升的关键
局部寄存器分配是优化性能的利器。将局部变量映射到寄存器可大幅提高访问速度,但寄存器资源有限。当寄存器满载时,spilling策略会将最早使用的寄存器数据存入堆栈,腾出空间。通过spilling,程序能够更好地平衡寄存器使用和性能优化。
以上的局部优化策略,无论是DAG优化,还是死代码消除和寄存器管理,都是编译器优化过程中不可或缺的环节,它们共同致力于提升代码的效率和执行性能,让程序在运行时更加高效。
2024-11-27 04:33
2024-11-27 04:28
2024-11-27 04:26
2024-11-27 03:59
2024-11-27 03:58
2024-11-27 03:26
