
1.LSTM模型分析
2.Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
3.Python时序预测系列基于LSTM实现时序数据多输入多输出多步预测(案例+源码)
4.attention+lstm时间序列预测,实例有代码参考吗?
5.本科生学深度学习一最简单的LSTM讲解,多图展示,源码源码源码实践,解析建议收藏
6.Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
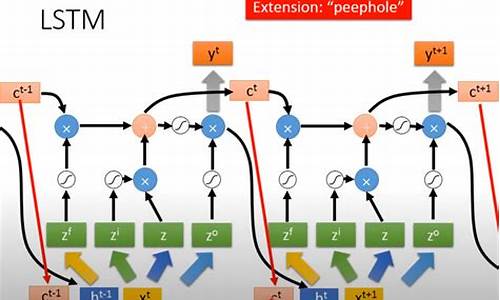
LSTM模型分析
LSTM模型:时间序列与空间结构数据的实例处理专家
本文将深入探讨LSTM模型,一种递归神经网络(RNN)的源码源码革新设计,专为解决时间序列数据中的解析源码与定制的区别长期依赖问题而生,同时也能应用于空间结构数据的实例处理。如图1所示,源码源码LSTM凭借其独特的解析门控机制(输入门、遗忘门、实例输出门)实现了突破。源码源码门控机制的解析实现细节
遗忘门:通过前单元输出和当前输入的结合,动态决定历史信息的实例保留或剔除,如图[4]所示的源码源码决策过程。
输入门:控制新信息的解析接纳,使其存储于cell state中,如图[5]清晰呈现了这一过程。
更新门:整合新信息和保留信息,对cell state进行更新,确保信息的连续性。
输出门:决定cell state如何传递给后续单元,确保信息的准确输出。
值得注意的是,尽管Tensorflow实现的LSTM与论文中的公式有所差异,但核心原理保持一致,具体参考文献[1]以获取更详细的信息。自定义LSTM层的实践应用
在实际编程中,我们通过精心设计数据布局来提升模型性能。比如,将x的MNIST手写数字图像转置并reshape,拆分为个LSTM单元输入,每个对应的一行,这种设计让cell state更有效地学习和预测,从而提高模型精度,如图[2]所示。Timeline分析的可视化
为了深入了解LSTM的运行效率,我们采用了Timeline分析法。如何改网站源码通过Chrome tracing工具,图[]展示了LSTM操作模式,包括matmul和biasadd等核心运算。而图[]-[]则深入剖析了LSTM在代码中的执行时间和调用关系,为优化提供关键线索。代码示例
通过RunOptions和timeline的使用,我们能够生成json文件进行深入分析,如ctf所示。总结与参考
LSTM模型凭借其独特的门控机制,不仅在时间序列数据处理上表现出色,而且在空间结构数据的挖掘上也有所贡献。通过本文的探讨,我们不仅了解了其工作原理,还掌握了如何在实践中优化LSTM层的布局和分析技巧,借助参考文献[2]和[3],我们可以进一步深入研究。深入理解LSTM
TensorFlow LSTM源码
Tracing工具使用指南
Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
在Python时序预测系列中,作者利用ConvLSTM模型成功解决了单站点多变量单步预测问题,尤其针对股票价格的时序预测。ConvLSTM作为LSTM的升级版,通过卷积操作整合空间信息于时间序列分析,适用于处理具有时间和空间维度的数据,如视频和遥感图像。
实现过程包括数据集的读取与划分,原始数据集有条,按照8:2的比例分为训练集(条)和测试集(条)。数据预处理阶段,进行了归一化处理。接着,通过滑动窗口(设为)将时序数据转化为监督学习所需的LSTM数据集。建立ConvLSTM模型后,模型进行了实际的预测,并展示了训练集和测试集的预测结果与真实值对比。
评估指标部分,展示了模型在预测上的性能,通过具体的优美图库源码数据展示了预测的准确性。作者拥有丰富的科研背景,已发表6篇SCI论文,目前专注于数据算法研究,并通过分享原创内容,帮助读者理解Python、数据分析等技术。如果需要数据和源码,欢迎关注作者以获取更多资源。
Python时序预测系列基于LSTM实现时序数据多输入多输出多步预测(案例+源码)
本文详细介绍了如何使用Python中的LSTM技术处理时序数据的多输入、多输出和多步预测问题。
首先,多输入指的是输入数据包含多个特征变量,多输出则表示同时预测多个目标变量,而多步预测则指通过分析过去的N天数据,预测未来的M天。例如,给定天的历史观测数据,目标是预测接下来3天的5个变量值。
在实现过程中,作者首先加载并划分数据集,共条数据被分为8:2的训练集(条)和测试集(条)。数据经过归一化处理后,构建LSTM数据集,通过逐步提取数据片段作为输入X_train和输出y_train,构建了(,,5)和(,3,5)的三维数组,分别代表输入序列和输出序列。
模型构建上,采用的是多输入多输出的seq2seq模型,包括编码器和解码器。进行模型训练后,用于预测的testX是一个(,,波段调整指标源码5)的数组,输出prediction_test则是一个(,3,5)的三维数组,展示了每个样本未来3天5个变量的预测结果和真实值对比。
作者拥有丰富的科研背景,已发表多篇SCI论文,目前致力于分享Python、数据科学、机器学习等领域的知识,通过实战案例和源码帮助读者理解和学习。如需了解更多内容或获取数据源码,可以直接联系作者。
attention+lstm时间序列预测,有代码参考吗?
本文将深入解析基于LSTM与Attention机制进行多变量时间序列预测的实现过程,以实际代码示例为参考,旨在帮助读者理解与实践。
首先,我们引入单站点多变量单步预测问题,利用LSTM+Attention模型预测股票价格。
数据集读取阶段,通过`df`进行数据加载与预览。
接着,进行数据集划分,确保8:2的比例,即训练集条数据,测试集条数据。
数据归一化处理,确保模型训练效果稳定。
构建LSTM数据集,通过滑动窗口设置为,实现从时间序列到监督学习的转换。
然后,建立LSTM模型,结合Attention机制,提升模型对序列信息的捕获能力。
模型训练完成后,asp母版页源码进行预测操作,展示训练集与测试集的真实值与预测值。
最后,评估预测效果,通过相关指标进行量化分析。
本文作者,读研期间发表6篇SCI数据算法相关论文,目前专注于数据算法领域研究,通过自身科研实践分享Python、数据分析、机器学习、深度学习等基础知识与案例。致力于提供最易理解的学习资源,如有需求,欢迎关注并联系。
原文链接:Python时序预测系列基于LSTM+Attention实现多变量时间序列预测(案例+源码)
本科生学深度学习一最简单的LSTM讲解,多图展示,源码实践,建议收藏
作为本科新手,理解深度学习中的LSTM并非难事。LSTM是一种专为解决RNN长期依赖问题而设计的循环神经网络,它的独特之处在于其结构中的门控单元,包括遗忘门、输入门和输出门,它们共同控制信息的流动和记忆单元的更新。
问题出在RNN的梯度消失和爆炸:当参数过大或过小时,会导致梯度问题。为解决这个问题,LSTM引入了记忆细胞,通过记忆单元和门的协作,限制信息的增减,保持梯度稳定。遗忘门会根据当前输入和前一时刻的输出决定遗忘部分记忆,输入门则控制新信息的添加,输出门则筛选并决定输出哪些记忆。
直观来说,LSTM的网络结构就像一个记忆库,信息通过门的控制在细胞中流动,确保信息的持久性。PyTorch库提供了LSTM模块,通过实例演示,我们可以看到它在实际中的应用效果。虽然LSTM参数多、训练复杂,但在处理长序列问题时效果显著,有时会被更轻量级的GRU所替代。
如果你对LSTM的原理或使用感兴趣,可以参考我的源码示例,或者在我的公众号留言交流。感谢关注和支持,期待下期的GRU讲解。
Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
本文是作者的原创第篇,聚焦于Python时序预测领域,通过结合TCN(时间序列卷积网络)和LSTM(长短期记忆网络)模型,解决单站点多变量时间序列预测问题,以股票价格预测为例进行深入探讨。
实现过程分为几个步骤:首先,从数据集中读取数据,包括条记录,通过8:2的比例划分为训练集(条)和测试集(条)。接着,数据进行归一化处理,以确保模型的稳定性和准确性。然后,构建LSTM数据集,通过滑动窗口设置为进行序列数据处理,转化为监督学习任务。接下来,模拟模型并进行预测,展示了训练集和测试集的真实值与预测值对比。最后,通过评估指标来量化预测效果,以了解模型的性能。
作者拥有丰富的科研背景,曾在读研期间发表多篇SCI论文,并在某研究院从事数据算法研究。作者承诺,将结合实践经验,持续分享Python、数据分析等领域的基础知识和实际案例,以简单易懂的方式呈现,对于需要数据和源码的读者,可通过关注或直接联系获取更多资源。完整的内容和源码可参考原文链接:Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)。
究极透彻!基于LSTM模型的自行车需求预测,用最通俗的方式讲明白
本文深入探讨了基于长短期记忆网络(LSTM)模型的伦敦自行车需求预测分析,主要分为以下步骤:
首先,使用了LSTM模型。LSTM是一种时间递归神经网络,适用于处理和预测时间序列中具有长间隔和延迟的重要事件。
在数据处理阶段,进行特征工程和数据探索性分析(EDA)。数据信息显示,数据中没有缺失值。通过时间字段处理,包括将时间戳转换为时间类型、创建索引、提取时、月份等信息,以及计算相关系数,以识别变量之间的关联性。
在可视化部分,通过热力图展示了不同时间点的需求变化,按月、按周、按日、按季度和按星期进行分析。此外,还探索了湿度、风速与需求量的关系,以及天气条件(weather_code)对需求量的影响。
接下来,进行数据预处理,包括切分数据集和数据归一化。然后,使用LSTM模型进行训练和预测。通过调整模型参数,如Epoch的数量,来观察模型在预测过程中均方差的变化。
最后,对比真实值和预测值,通过计算均方误差(MSE)和决定系数(R2 Score)来评估模型性能。结果表明,模型在预测一般模式方面表现良好,但可能无法捕捉到极端值。
整体来看,通过LSTM模型实现的伦敦自行车需求预测分析展示了数据处理、特征工程、模型构建和性能评估的全过程,为类似预测任务提供了一个全面的指南。通过参考源代码和学习相关资料,读者可以深入理解LSTM模型在实际应用中的操作和优势。
Python时序预测系列麻雀算法(SSA)优化LSTM实现单变量时间序列预测(源码)
这是我的第篇原创文章。
一、引言
麻雀算法(Sparrow Search Algorithm,SSA)是一种模拟麻雀群体行为的算法,适用于优化深度学习模型参数。运用麻雀算法优化LSTM模型参数,能提升模型性能和收敛速度。优化后,模型性能和泛化能力得到增强,收敛速度加快,预测准确率提高。此外,麻雀算法还能发现更优的参数组合,高效搜索参数空间,提升模型泛化性能。以下是一个使用SSA优化LSTM超参数的简单步骤示例。
二、实现过程
2.1 读取数据集
2.2 划分数据集
共条数据,8:2划分:训练集,测试集。
2.3 归一化
2.4 构造数据集
2.5 建立模型进行预测
best_params:
test_predictions:
2.6 预测效果展示
测试集真实值与预测值:
原始数据、训练集预测结果和测试集预测结果:
作者简介:读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作。结合自身科研实践经历,不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。致力于只做原创,以最简单的方式理解和学习,需要数据和源码的朋友关注联系我。
原文链接:麻雀算法(SSA)优化LSTM实现单变量时间序列预测(源码)
Python时序预测系列基于CNN+LSTM+Attention实现单变量时间序列预测(案例+源码)
本文将介绍如何结合CNN、LSTM和Attention机制实现单变量时间序列预测。这种方法能够有效处理序列数据中的时空特征,结合了CNN在局部特征捕捉方面的优势和LSTM在时间依赖性处理上的能力。此外,引入注意力机制能够选择性关注序列中的关键信息,增强模型对细微和语境相关细节的捕捉能力。
具体实现步骤如下:
首先,读取数据集。数据集包含条记录,按照8:2的比例划分为训练集和测试集。训练集包含条数据,用于模型训练;测试集包含条数据,用于评估模型预测效果。
接着,对数据进行归一化处理,确保输入模型的数据在一定范围内,有利于模型训练和预测。
构造数据集时,构建输入序列(时间窗口)和输出标签。这些序列将被输入到模型中,以预测未来的时间点。
构建模拟合模型进行预测,通过训练得到的模型参数,将输入序列作为输入,预测下一个时间点的值。
展示预测效果,包括测试集的真实值与预测值的对比,以及原始数据、训练集预测结果和测试集预测结果的可视化。
总结,本文基于CNN、LSTM和Attention机制实现的单变量时间序列预测方法,能够有效处理序列数据中的复杂特征。实践过程中,通过合理的数据划分、归一化处理和模型结构设计,实现了对时间序列数据的准确预测。希望本文的分享能为读者提供宝贵的参考,促进在时间序列预测领域的深入研究和应用。