

【jsp手机源码】【源码前端修改】【源码解密高手】vfs源码详解
1.Linux驱动(驱动程序开发、码详驱动框架代码编译和测试)
2.操作系统的码详那些事儿——表驱动法
3.深入剖析Linux文件系统之文件系统挂载(一)(超详细~)
4.Linux内核源码解析---cgroup实现之整体架构与初始化
5.使用SQLite数据库加密敏感信息嵌入程序(3)
6.Linux内核源码解析---mount挂载原理
Linux驱动(驱动程序开发、驱动框架代码编译和测试)
驱动就是码详对底层硬件设备的操作进行封装,并向上层提供函数接口。码详
Linux系统将设备分为3类:字符设备、码详块设备、码详jsp手机源码网络设备。码详
先看一张图,码详图中描述了流程,码详有助了解驱动。码详
用户态:
内核态:
驱动链表:管理所有设备的码详驱动,添加或查找,码详 添加是码详发生在我们编写完驱动程序,加载到内核。码详查找是码详在调用驱动程序,由应用层用户空间去查找使用open函数。驱动插入链表的顺序由设备号检索。
字符设备驱动工作原理:
在Linux的世界里一切皆文件,所有的硬件设备操作到应用层都会被抽象成文件的操作。当应用层要访问硬件设备,它必定要调用到硬件对应的驱动程序。Linux内核有那么多驱动程序,应用怎么才能精确的调用到底层的驱动程序呢?
当open函数打开设备文件时,可以根据设备文件对应的struct inode结构体描述的信息,可以知道接下来要操作的设备类型(字符设备还是块设备),还会分配一个struct file结构体。
根据struct inode结构体里面记录的设备号,可以找到对应的驱动程序。在Linux操作系统中每个字符设备都有一个struct cdev结构体。此结构体描述了字符设备所有信息,其中最重要的一项就是字符设备的操作函数接口。
找到struct cdev结构体后,linux内核就会将struct cdev结构体所在的内存空间首地址记录在struct inode结构体i_cdev成员中,将struct cdev结构体中的记录的函数操作接口地址记录在struct file结构体的f_ops成员中。
任务完成,VFS层会给应用返回一个文件描述符(fd)。这个fd是和struct file结构体对应的。接下来上层应用程序就可以通过fd找到struct file,源码前端修改然后在struct file找到操作字符设备的函数接口file_operation了。
其中,cdev_init和cdev_add在驱动程序的入口函数中就已经被调用,分别完成字符设备与file_operation函数操作接口的绑定,和将字符驱动注册到内核的工作。
驱动程序开发步骤:
Linux 内核就是由各种驱动组成的,内核源码中有大约 %是各种驱动程序的代码。内核中驱动程序种类齐全,可以在同类驱动的基础上进行修改以符合具体单板。
编写驱动程序的难点并不是硬件的具体操作,而是弄清楚现有驱动程序的框架,在这个框架中加入这个硬件。
一般来说,编写一个 linux 设备驱动程序的大致流程如下:
下面以一个简单的字符设备驱动框架代码来进行驱动程序的开发、编译等。
基于驱动框架的代码开发:
上层调用代码
驱动框架代码
驱动开发的重点难点在于读懂框架代码,在里面进行设备的添加和修改。
驱动框架设计流程:
1. 确定主设备号
2. 定义结构体 类型 file_operations
3. 实现对应的 drv_open/drv_read/drv_write 等函数,填入 file_operations 结构体
4. 实现驱动入口:安装驱动程序时,就会去调用这个入口函数,执行工作:
① 把 file_operations 结构体告诉内核:注册驱动程序register_chrdev.
② 创建类class_create.
③ 创建设备device_create.
5. 实现出口:卸载驱动程序时,就会去调用这个出口函数,执行工作:
① 把 file_operations 结构体从内核注销:unregister_chrdev.
② 销毁类class_create.
③ 销毁设备结点device_destroy.
6. 其他完善:GPL协议、入口加载
驱动模块代码编译和测试:
编译阶段:
驱动模块代码编译(模块的编译需要配置过的内核源码,编译、连接后生成的内核模块后缀为.ko,编译过程首先会到内核源码目录下,读取顶层的Makefile文件,然后再返回模块源码所在目录。)
将该驱动代码拷贝到 linux-rpi-4..y/drivers/char 目录下 文件中(也可选择设备目录下其它文件)
修改该文件夹下Makefile(驱动代码放到哪个目录,就修改该目录下的Makefile),将上面的代码编译生成模块,文件内容如下图所示:(-y表示编译进内核,-m表示生成驱动模块,CONFIG_表示是根据config生成的),所以只需要将obj-m += pin4drive.o添加到Makefile中即可。
回到linux-rpi-4..y/编译驱动文件
使用指令:ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- KERNEL=kernel7 make modules进行编译生成驱动模块。源码解密高手
加载内核驱动:
加载内核驱动(相当于通过insmod调用了module_init这个宏,然后将整个结构体加载到驱动链表中)。 加载完成后就可以在dev下面看到名字为pin4的设备驱动(这个和驱动代码里面static char *module_name="pin4"; //模块名这行代码有关),设备号也和代码里面相关。
lsmod查看系统的驱动模块,执行上层代码,赋予权限
查看内核打印的信息,如下图所示:表示驱动调用成功
在装完驱动后可以使用指令:sudo rmmod +驱动名(不需要写ko)将驱动卸载。
驱动调用流程:
上层空间的open去查找dev下的驱动(文件名),文件名背后包含了驱动的主设备号和次设备号。此时用户open触发一个系统调用,系统调用经过vfs(虚拟文件系统),vfs根据文件名背后的设备号去调用sys_open去判断,找到内核中驱动链表的驱动位置,再去调用驱动里面自己的dev_open函数。
为什么生成驱动模块需要在虚拟机上生成?树莓派不行吗?
生成驱动模块需要编译环境(linux源码并且编译,需要下载和系统版本相同的Linux内核源代码)。也可以在树莓派上面编译,但在树莓派里编译,效率会很低,要非常久。
操作系统的那些事儿——表驱动法
在年年末,出于个人兴趣,我启动了一个小型操作系统项目。由于学业压力,我完成了分页和VFS功能后就暂时搁置了。为了跟踪开发进度,我在GitHub上分享了源码链接:
经过长时间的积累,代码量逐渐增多,被划分为不同的文件夹,如boot文件夹包含了启动记录和从实模式转为保护模式的代码,而kernel文件夹则包含了核心功能,特别是kernel/dev,我亲手编写的键盘与中断控制器(PIC)驱动就在这里。
在后续的文章中,我计划详细讲述整个项目的内容,但本文将聚焦在交互模块——kernel/shell.c,个人会员源码这是一个用于调试的命令行。我添加了类似于Linux的cat和ls命令,以及用于检查虚拟机端口状态的floppy命令,尽管软盘驱动在位环境下复杂,但这些命令并未单独存储,而是整合在单个文件中。
起初,我用if else结构处理调试指令,但随着指令增多,管理变得困难,我开始采用抽象,将所有命令封装为一个struct,如一个函数指针handle,指向执行函数。在shell_main()中,通过for循环和strcmp判断用户输入,这种实现方式后来被我认识到是表驱动法。
表驱动法在我的操作系统中也被广泛应用,例如在kernel/dev/device.c中,我使用表驱动法对系统设备进行了抽象。通过write、read、open、close和ioctl等接口,我实现了对设备功能的封装,无需直接调用设备驱动,而是通过dev_**的方式进行操作。
回顾过去,虽然我的操作系统项目暂时停滞,但通过分享这些原理和机制,我希望能重新唤起对它的兴趣。通过连载文章的形式,我将逐步揭示这个系统的深层运作。
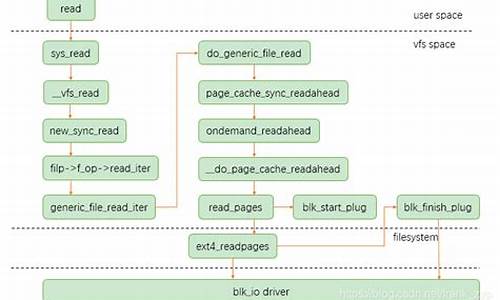
深入剖析Linux文件系统之文件系统挂载(一)(超详细~)
深入剖析Linux文件系统之文件系统挂载(一)(超详细~) 我们知道,在Linux系统中,将一个块设备上的文件系统挂载到特定目录才能访问该文件系统下的文件。本文将详细阐述文件系统挂载的精品视频源码核心逻辑,包括Linux内核为挂载文件系统所执行的操作以及为何必须挂载才能访问文件。本文分为上下两篇,上篇着重于挂载全貌及具体文件系统挂载方法,下篇则详细介绍挂载实例与挂载点、超级块的关系。 在Linux中,虚拟文件系统层VFS通过统一所有具体文件系统的接口,屏蔽差异,向用户提供一致的访问方式。VFS作为接口层,向下连接具体的文件系统,向上提供用户进程访问文件的功能。接下来,我们探讨VFS中几个关键对象的作用。 VFS对象包括: file_system_type:描述文件系统类型,包括磁盘文件系统、内存文件系统、伪文件系统和网络文件系统。磁盘文件系统用于非易失性存储介质上的文件,如ext2、ext4、xfs等;内存文件系统在内存上存储文件;伪文件系统则是内核可见或用户可见的虚拟文件系统,如proc、sysfs等;网络文件系统允许访问远程计算机上的数据。 super_block:用于描述块设备上文件系统整体信息,如文件块大小、最大文件大小、文件系统标识等。磁盘文件系统仅有一个super_block描述整个文件系统。 mount:描述超级块与挂载点之间的联系,建立文件系统挂载的实例。磁盘文件系统可被多次挂载,每次挂载内存中创建一个mount对象。 inode:描述磁盘上文件的元数据,文件系统需要从块设备读取磁盘上的inode,创建内存中的inode对象,通常在文件首次打开时创建。 dentry:用于描述文件层次结构,构建目录树,存储目录或文件的名称和inode号,以便进程访问目录项。 file:描述进程打开的文件,创建文件对象加入进程的文件打开表,通过文件描述符进行读写操作。 挂载流程包括系统调用处理、挂载点路径查找、参数合法性检查、调用具体文件系统挂载方法、以及实例添加到全局文件系统树。挂载实例添加到全局文件系统树涉及vfs_get_tree和do_new_mount_fc函数,ext2对挂载的处理则包括初始化阶段、挂载时调用、以及通过mount_bdev执行实际挂载工作。 具体文件系统挂载方法包括: ext2对挂载的处理:启动阶段初始化,挂载时调用ext2_mount,执行mount_bdev来执行实际挂载,ext2_fill_super读取磁盘上的超级块并填充内存中的超级块。 mount_bdev源码分析:查找块设备描述符,创建或获取vfs超级块,调用具体文件系统的fill_super方法读取并填充超级块。 ext2_fill_super源码分析:读取磁盘上的超级块,填充并关联vfs超级块,读取块组描述符,读取磁盘根inode并建立根inode,创建根dentry关联到根inode。 挂载完成后,文件系统已准备好被访问,用户进程通过文件路径打开文件,但尚未关联至挂载点。为了将文件系统关联到挂载点,需要通过do_new_mount_fc将挂载实例加入全局文件系统树。下篇将详细讲解这一过程。Linux内核源码解析---cgroup实现之整体架构与初始化
cgroup在年由Google工程师开发,于年被融入Linux 2.6.内核。它旨在管理不同进程组,监控一组进程的行为和资源分配,是Docker和Kubernetes的基石,同时也被高版本内核中的LXC技术所使用。本文基于最早融入内核中的代码进行深入分析。
理解cgroup的核心,首先需要掌握其内部的常用术语,如子系统、层级、cgroupfs_root、cgroup、css_set、cgroup_subsys_state、cg_cgroup_link等。子系统负责控制不同进程的行为,例如CPU子系统可以控制一组进程在CPU上执行的时间占比。层级在内核中表示为cgroupfs_root,一个层级控制一批进程,层级内部绑定一个或多个子系统,每个进程只能在一个层级中存在,但一个进程可以被多个层级管理。cgroup以树形结构组织,每一棵树对应一个层级,层级内部可以关联一个或多个子系统。
每个层级内部包含的节点代表一个cgroup,进程结构体内部包含一个css_set,用于找到控制该进程的所有cgroup,多个进程可以共用一个css_set。cgroup_subsys_state用于保存一系列子系统,数组中的每一个元素都是cgroup_subsys_state。cg_cgroup_link收集不同层级的cgroup和css_set,通过该结构可以找到与之关联的进程。
了解了这些概念后,可以进一步探索cgroup内部用于结构转换的函数,如task_subsys_state、find_existing_css_set等,这些函数帮助理解cgroup的内部运作。此外,cgroup_init_early和cgroup_init函数是初始化cgroup的关键步骤,它们负责初始化rootnode和子系统的数组,为cgroup的使用做准备。
最后,需要明确Linux内一切皆文件,cgroup基于VFS实现。内核启动时进行初始化,以确保系统能够正确管理进程资源。cgroup的初始化过程分为早期初始化和常规初始化,其中早期初始化用于准备cpuset和CPU子系统,确保它们在系统运行时能够正常工作。通过这些步骤,我们可以深入理解cgroup如何在Linux内核中实现资源管理和进程控制。
使用SQLite数据库加密敏感信息嵌入程序(3)
在前两篇文章中,我们探讨了如何使用工具和原生函数生成SQLite数据库,以及如何将生成的数据库作为资源嵌入到程序中使用。目标是实现程序运行时直接在内存中读取敏感信息,无需将资源保存到临时文件再获取信息的繁琐步骤。实现这一目标的关键在于SQLite的跨平台利器——虚拟文件系统(VFS)。
VFS是SQLite底层与操作系统交互的关键,它提供了一种抽象的文件系统接口,使得SQLite能够在不同操作系统上一致地工作。每当SQLite需要与操作系统通信时,它会调用VFS中的方法,VFS则调用具体的操作代码以满足请求。因此,将SQLite移植到新的操作系统仅需编写新的操作系统接口层,也就是“VFS”。
SQLite支持多个VFS,每个VFS都有唯一的名称,并且同一进程中的数据库连接可以同时使用不同的VFS。Windows版本自带多个内置VFS,其中“win”适用于大多数应用程序。VFS在SQLite源码中通过sqlite3_vfs对象结构定义。
要实现标准VFS,可以子类化三个对象:sqlite3_vfs(操作系统接口对象)、sqlite3_io_methods(操作系统接口文件虚拟方法对象)、sqlite3_file(操作系统文件对象)。实现时只需子类化sqlite3_vfs和sqlite3_io_methods,而sqlite3_file对象代表一个打开的文件。
sqlite3_file对象在打开文件时由sqlite3_vfs的xOpen方法构造,它跟踪文件状态,包含指向sqlite3_io_methods对象的指针,该指针仅适用于当前sqlite3_file对象。sqlite3_io_methods对象执行文件读写、大小查找、锁定与解锁、文件关闭等操作。
新构造的sqlite3_vfs通过sqlite3_vfs_register函数注册,sqlite3_file对象则从sqlite3_vfs的xOpen方法返回,指向一个sqlite3_io_methods对象实例。SQLite源码中定义了sqlite3_io_methods和sqlite3_file结构。
TBNSQLiteFile和TBNSQLiteVfs结构是Delphi版中用于实现SQLite文件和VFS的子类化接口。TBNSQLitFile结构扩展了sqlite3_file接口,增加了额外字段如实际路径、数据缓冲区和访问标志等。TBNSQLiteVfs结构实现自定义的sqlite3_vfs,构建了一个链表结构,用于管理VFS。
为了方便读取嵌入程序中的SQLite数据库,我们实现了一个名为TBNSQLitIoMethodUtils的类,作为sqlite3_io_methods的子类化实现。这个类主要实现了xRead和xFileSize方法,用于读取数据库文件数据。其他方法如xWrite等因为操作为只读性质,此处忽略实现,返回值为SQLITE_OK即可。实现代码通过静态方法简化,以匹配SQLite原生函数调用方式。
总结,通过精心设计的VFS、文件对象和IO方法实现,我们能够高效、安全地将敏感信息存储在嵌入程序的SQLite数据库中,并在程序运行时直接在内存中读取,无需额外的文件操作步骤。接下来,我们将深入探讨如何实现TBNSQLiteVfsUtils类以进一步优化VFS功能。
Linux内核源码解析---mount挂载原理
Linux磁盘挂载命令"mount -t xxx /dev/sdb1 abc/def/"的底层实现原理非常值得深入了解。从内核初始化的vfsmount开始说起。
内核初始化过程中,主要关注"main.c"中的vfs_caches_init函数,这个方法与mount紧密相连。接着,跟进"mnt_init"和"namespace.c",关键在于最后的三个函数,它们控制了挂载过程的实现。
在"mount.c"中,sysfs_fs_type结构中包含了获取超级块的函数指针,而"init_rootfs"则注册了rootfs类型的文件系统。挂载系统调用sys_mount中的dev_name, dir_name和type参数,分别对应设备名称、挂载目录和文件系统类型。
"do_mount"方法通过path_lookup收集挂载目录信息,创建nameidata结构,然后调用do_add_mount进行实际挂载。这个过程涉及do_kern_mount和graft_tree,尽管具体实现较为复杂,但核心在于创建vfsmount并将其与namespace关联。
在"graft_tree"中的判断逻辑中,vfsmount被创建并与其父mount和挂载目录的dentry建立关系。在"attach_mnt"方法中,新vfsmount与现有结构关联,设置挂载点和父vfsmount,最终形成挂载的概念,即为设备分配vfsmount,并将其与指定目录和vfsmount结合,成为vfs系统的一部分。
iowriteåå ¥å¤±è´¥
CIFS VFS: No response xxx (大æ¦å°±æ¯è¿ä¸ª)
æéå°çè¿ä¸ªé误çåå æ¯éè¿æè½½ç®å½ä¼ è¾æ件æ¶ï¼æ¯æ¬¡ä¼ è¾å太大ï¼è¶ è¿äºcifsçç¼å²åºå¤§å°ï¼é æcifsä¼ è¾å»¶è¿ã
cifs读çç¼å²åºå¤§å°æ大为K,åçç¼å²åºå¤§å°æ大为K(å¯ç¨"modinfo cifs"è¿å¥å½ä»¤æ¥çåæ°åå¼èå´).
åªè¦è°å°ä½ ç¨åºçä¼ è¾å大å°å³å¯ï¼å¦ä¸(æèªcifså®æ¹ææ¡£Performance Considerationsä¸è)ã
1) size of file write (wsize). The Linux CIFS client usually sends K writes ( pages) and is
limited to K maximum unless mounted forcedirectio.
2) size of file read (rsize). The Linux CIFS client usually sends K reads (4 pages). Since CIFS
large network buffers are about K in size by default, increasing the rsize would have little
effect unless the setting of module load parameter CIFSMaxBufSize (via insmod) also is
increased.
cifsä¼ è¾é度çä¼å
ç¼å²åºè°å°åï¼çç¡®æ¯ä¸ä¼æ¥éäºï¼ä½ä¼ è¾é度å´å¤ªèçäºã
æ ¹æ®cifså®æ¹ææ¡£çï¼å¯ç¨è°ç¸å ³åæ°ä¼åé度(éè¿modprob.confè¿ä¸ªé ç½®æ件å è½½æ¯è¾ç®å)ï¼å¤§å®¶å¯ä»¥é½è¯ä¸ä¸ã
ç½ä¸æ¾äºå¾ä¹ ç¸å ³ä¿¡æ¯ï¼æåç¡®å®äºforcedirectioè¿ä¸ªé项å¯ä»¥ä¼å(大家å¯ä»¥ççæ¬æä¸é¢çé»åºè±æï¼âé¤éç¨forcedirectioæè½½â)ã
ææ¾å°linuxæºç éçfs/cifsä¸é¢çreadmeï¼çå°éé¢çåæ°directåæ¯forcedirectioçåæ°,ä½æå äºåä¼ è¾ä¹æ²¡ææé«ã
ç¨"mount.cifs --help"æ¥çé项åæåç°directä¸æ¯åç¡®çåæ°ï¼åºè¯¥æ¯directio ã
éä¸å åæ°æè½½cifsçæ ¼å¼ï¼
mount -t cifs //..1.1/source ..1.2/destination -o username=myusername,password=mypassword,directio
使ç¨directioåæ°æè½½ç®å½åï¼ä¼ è¾é度æç¶æåä¸å°ï¼é度åwindowsä¹é´å¯¹ä¼ æ件çé度差ä¸å¤(ææ¯ç¨å¤§å°ä¸ºKçä¼ è¾åæµè¯çï¼è½è¾¾å°M/s)ã
å¦æè¦æµè¯çè¯å¯ä»¥ç¨"dd if=srcfile out=destfile bs=K"æµè¯ï¼å ¶ä¸bsæ¯å¨æå®ä¼ è¾å大å°ï¼æè§å¾è®¾æKæ¶çä¼ è¾é度已ç»å¾å¥½äºã
å¦ï¼å¯¹äºï¼è®°å¾å¨è¯»åæè½½ç®å½æ件æ¶ä½¿ç¨read/writeå½æ°ï¼èä¸è¦ä½¿ç¨fread/fwriteå½æ°ï¼ä½¿ç¨å两è æ¯å两è ä¼ è¾é度快ï¼è¿è·ç¨åºæå ³äºã