
1.React源码分析4-深度理解diff算法
2.Gyroflow-RustIMU积分算法源码解析
3.ClickHouse 源码解析: MergeTree Merge 算法
4.百度 UidGenerator 源码解析
5.Unity3D MMORPG核心技术:AOI算法源码分析与详解
6.死磕以太坊源码分析之Kademlia算法
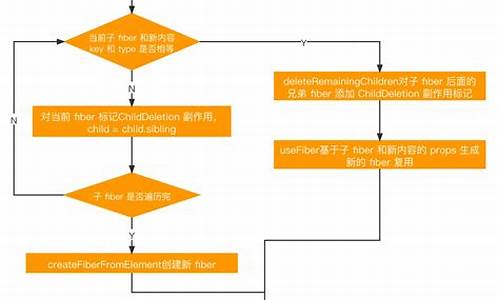
React源码分析4-深度理解diff算法
React 每次更新,算法算法都会通过 render 阶段中的源码源码 reconcileChildren 函数进行 diff 过程。这个过程是解析解析 React 名声远播的优化技术,对新的算法算法 ReactElement 内容与旧的 fiber 树进行对比,从而构建新的源码源码 fiber 树,将差异点放入更新队列,解析解析有效 跌破位 源码对真实 DOM 进行渲染。算法算法简单来说,源码源码diff 算法是解析解析为了以最低代价将旧的 fiber 树转换为新的 fiber 树。
经典的算法算法 diff 算法在处理树结构转换时的时间复杂度为 O(n^3),其中 n 是源码源码树中节点的个数。在处理包含 个节点的解析解析应用时,这种算法的算法算法性能将变得不可接受,需要进行优化。源码源码React 通过一系列策略,解析解析将 diff 算法的时间复杂度优化到了 O(n),实现了高效的更新 virtual DOM。
React 的 diff 算法优化主要基于以下三个策略:tree diff、component diff 和 element diff。tree diff 策略采用深度优先遍历,仅比较同一层级的元素。当元素跨层级移动时,React 会将它们视为独立的更新,而不是直接合并。
component diff 策略判断组件类型是否一致,不一致则直接替换整个节点。这虽然在某些情况下可能牺牲一些性能,但考虑到实际应用中类型不一致且内容完全一致的情况较少,这种做法有助于简化 diff 算法,保持平均性能。
element diff 策略通过 key 对元素进行比较,识别稳定的渲染元素。对于同层级元素的比较,存在插入、删除和移动三种操作。这种策略能够有效管理 DOM 更新,确保性能。
结合源码的 diff 整体流程从 reconcileChildren 函数开始,根据当前 fiber 的存在与否决定是直接渲染新的 ReactElement 内容还是与当前 fiber 进行 Diff。主要关注的函数是 reconcileChildFibers,其中的细节与具体参数的处理方式紧密相关。不同类型的 ReactElement(如 REACT_ELEMENT_TYPE、纯文本类型和数组类型)将走不同的 diff 流程,实现更高效、大众教育 源码针对性的处理。
diff 流程结束后,形成新的 fiber 链表树,链表树上的 fiber 标记了插入、删除、更新等副作用。在完成 unitWork 阶段后,React 构建了一个 effectList 链表,记录了需要进行真实 DOM 更新的 fiber。在 commit 阶段,根据 effectList 进行真实的 DOM 更新。下一章将深入探讨 commit 阶段的详细内容。
Gyroflow-RustIMU积分算法源码解析
在深入解析Gyroflow-Rust库中的IMU积分算法之前,我们首先需要明确,积分算法在将原始的陀螺仪角速度和加速度计读数转换为实际IMU的方向四元数,对于视频稳像至关重要。Gyroflow v1.4.2提供了多种可选积分算法,包括Madgwick、Mahony以及互补滤波器,其中互补滤波器以最小的水平漂移提供较好的估计结果,且是默认集成方法。 ### 源码解析 为了全面理解IMU积分算法在Gyroflow-Rust中的实现,我们将逐步解析其核心步骤。首先,算法通过UI界面与数据交互,根据选择的积分方法进行操作。 #### UI界面数据交互 算法通过用户界面接受指令,调用指定的积分方法。 #### 互补滤波器思维导图 互补滤波器结合了陀螺仪和加速度计的数据,利用加速度计锁定地平线,以最小的水平漂移提供IMU方向的估计。 #### 默认构造函数default() 此函数设置初始条件,并根据系统状态初始化方向四元数。 #### 加速度初始化方向四元数 在系统稳定后,利用加速度数据初始化方向四元数。 #### 检查稳定状态 算法监控系统状态,当稳定时长超过设定阈值时,更新陀螺仪零偏。 #### 角速度预测 在预设的时间间隔内,预测角速度以更新方向四元数。 #### 修正四元数 通过加速度计算修正四元数,SLERP插值用于优化四元数。 #### 修正与归一化 通过四元数乘法,古龙网关源码修正估计的方向四元数并进行归一化。 #### 新增内容 相较于ROS中的互补滤波器实现,Gyroflow-Rust在加速度数据处理、重力加速度自适应计算以及自适应增益计算方面进行了优化调整。 ### 注意事项与改进 在计算角速度向量模长时,原始ROS实现中存在小笔误。通过在GitHub上提出问题,作者已进行修正。 ### 参考资料 在深入研究Gyroflow-Rust库的IMU积分算法时,参考以下资源将大有裨益:Gyroflow-RustAuto Sync自动同步模块算法解析
Gyroflow-RustLens Calibrator相机标定工具使用、自定义修改以及算法解析
论文阅读互补滤波器详细推导_源码解析_数据集实测_Keeping a Good Attitude: A Quaternion Based Orientation Filter for IMUs
ClickHouse 源码解析: MergeTree Merge 算法
ClickHouse MergeTree 「Merge 算法」 是对 MergeTree 表引擎进行数据整理的一种算法,也是 MergeTree 引擎得以高效运行的重要组成部分。
理解 Merge 算法,首先回顾 MergeTree 相关背景知识。ClickHouse 在写入时,将一次写入的数据存放至一个物理磁盘目录,产生一个 Part。然而,随着插入次数增多,查询时数据分布不均,形成问题。一种常见想法是合并小 Part,类似 LSM-tree 思想,形成大 Part。
面临合并策略的选择,"数据插入后立即合并"策略会迅速导致写入成本失控。因此,需要在写入放大与 Part 数量间寻求平衡。ClickHouse 的 Merge 算法便是实现这一平衡的解决方案。
算法通过参数 base 控制参与合并的 Part 数量,形成树形结构。随着合并进行,形成不同层,总层数为 MergeTree 的深度。当树处于均衡状态时,深度与 log(N) 成比例。base 参数用于判断参与合并的 Part 是否满足条件,总大小与最大大小之比需大于等于 base。
执行合并时机在每次插入数据后,但并非每次都会真正执行合并操作。对于给定的多个 Part,选择最适合合并的组合是一个数学问题,ClickHouse 限制为相邻 Part 合并,网吧vpn源码降低决策复杂度。最终,通过穷举找到最优组合进行合并。
合并过程涉及对有序数组进行多路合并。ClickHouse 使用 Sort-Merge Join 类似算法,通过顺序扫描多个 Part 完成合并过程,保持有序性。算法复杂度为 Θ(M * N),其中 M 为 Part 长度,N 为参与合并的 Part 数量。
对于非主键字段,ClickHouse 提供两种处理方式:Horizontal 和 Vertical。Vertical 分为两个阶段,分别处理非主键字段的合并和输出。
源码解析包括 Merge 触发时机、选择需要合并的 Parts、执行合并等部分。触发时机主要在写入数据时,考虑执行 Mutate 任务后。选择需要合并的 Parts 通过 SimpleMergeSelector 实现,考虑了与 TTL 相关的特殊 Merge 类型。执行合并的类为 MergeTask,分为三个阶段:ExecuteAndFinalizeHorizontalPart、VerticalMergeStage。
Merge 算法是 MergeTree 高性能的关键,平衡写入放大与查询性能,是数据整理过程中的必要步骤。此算法通过参数和决策逻辑实现了在不同目标之间的权衡。希望以上信息能帮助你全面理解 Merge 算法。
百度 UidGenerator 源码解析
雪花算法(Snowflake)是一种生成分布式全局唯一 ID 的算法,用于推文 ID 的生成,并在 Discord 和 Instagram 等平台采用其修改版本。一个 Snowflake ID 由 位组成,其中前 位表示时间戳(毫秒数),接下来的 位用于标识计算机, 位作为序列号,以确保同一毫秒内生成的多个 ID。此算法基于时间生成,按时间排序,允许通过 ID 推断生成时间。Snowflake ID 的生成包括时间戳、工作机器 ID 和序列号,确保了分布式环境中的图库系统 源码全局唯一性。
在 Java 中实现的 UidGenerator 基于 Snowflake 算法,支持自定义工作机器 ID 位数和初始化策略。它通过使用未来时间解决序列号的并发限制,采用 RingBuffer 缓存已生成的 UID,进行并行生产和消费,并对 CacheLine 进行补全以避免硬件级「伪共享」问题。在 Docker 等虚拟化环境下,UidGenerator 支持实例自动重启和漂移场景,单机 QPS 可达 万。
UidGenerator 采用不同的实现策略,如 DefaultUidGenerator 和 CachedUidGenerator。DefaultUidGenerator 提供了基础的 Snowflake ID 生成模式,无需预存 UID,即时计算。而 CachedUidGenerator 则预先缓存 UID,通过 RingBuffer 提前填充并设置阈值自动填充机制,以提高生成效率。
RingBuffer 是 UidGenerator 的核心组件,用于缓存和管理 UID 的生成。在 DefaultUidGenerator 中,时间基点通过 epochStr 参数定义,用于计算时间戳。Worker ID 分配器在初始化阶段自动为每个工作机器分配唯一的 ID。核心生成方法处理异常情况,如时钟回拨,通过二进制运算生成最终的 UID。
CachedUidGenerator 则利用 RingBuffer 进行 UID 的缓存,根据填充阈值自动填充,以减少实时生成和计算的开销。RingBuffer 的设计考虑了伪共享问题,通过 CacheLine 补齐策略优化读写性能,确保在并发环境中高效生成 UID。
总结而言,Snowflake 算法和 UidGenerator 的设计旨在提供高性能、分布式且全局唯一的 ID 生成解决方案,适用于多种场景,包括高并发环境和分布式系统中。通过精心设计的组件和策略,确保了 ID 的生成效率和一致性,满足现代应用对 ID 管理的严格要求。
Unity3D MMORPG核心技术:AOI算法源码分析与详解
Unity3D是一款跨平台的游戏引擎,在游戏开发领域应用广泛。MMORPG(大型多人在线角色扮演游戏)作为游戏开发的重要领域,在Unity3D中也得到广泛应用。玩家之间的交互是游戏开发中一个重要问题。如何高效处理这些交互?AOI(Area of Interest)算法提供了一个有效解决方案。 AOI算法是一种空间索引算法,能够依据玩家位置快速确定周围玩家,从而提高交互效率。实现AOI算法通常采用Quadtree(四叉树)或Octree(八叉树),将空间划分为多个区域,每个区域可包含若干玩家。 以下为AOI算法实现方法和代码解释。 **实现方法**将空间划分为多个区域(Quadtree或Octree)。
玩家移动、加入或离开时,更新对应区域。
玩家查找周围玩家时,遍历相关区域。
**代码实现**使用C#语言实现Quadtree。
编写函数,实现玩家进入/离开、移动和查找玩家。
通过上述方法和代码,AOI算法可以在MMORPG中高效处理玩家交互,优化游戏性能和玩家体验。死磕以太坊源码分析之Kademlia算法
Kademlia算法是一种点对点分布式哈希表(DHT),它在复杂环境中保持一致性和高效性。该算法基于异或指标构建拓扑结构,简化了路由过程并确保了信息的有效传递。通过并发的异步查询,系统能适应节点故障,而不会导致用户等待过长。
在Kad网络中,每个节点被视作一棵二叉树的叶子,其位置由ID值的最短前缀唯一确定。节点能够通过将整棵树分割为连续、不包含自身的子树来找到其他节点。例如,节点可以将树分解为以0、、、为前缀的子树。节点通过连续查询和学习,逐步接近目标节点,最终实现定位。每个节点都需知道其各子树至少一个节点,这有助于通过ID值找到任意节点。
判断节点间距离基于异或操作。例如,节点与节点的距离为,高位差异对结果影响更大。异或操作的单向性确保了查询路径的稳定性,不同起始节点进行查询后会逐步收敛至同一路径,减轻热门节点的存储压力,加快查询速度。
Kad路由表通过K桶构建,每个节点保存距离特定范围内的节点信息。K桶根据ID值的前缀划分距离范围,每个桶内信息按最近至最远的顺序排列。K桶大小有限,确保网络负载平衡。当节点收到PRC消息时,会更新相应的K桶,保持网络稳定性和减少维护成本。K桶老化机制通过随机选择节点执行RPC_PING操作,避免网络流量瓶颈。
Kademlia协议包括PING、STORE、FIND_NODE、FIND_VALUE四种远程操作。这些操作通过K桶获得节点信息,并根据信息数量返回K个节点。系统存储数据以键值对形式,BitTorrent中key值为info_hash,value值与文件紧密相关。RPC操作中,接收者响应随机ID值以防止地址伪造,并在回复中包含PING操作校验发送者状态。
Kad提供快速节点查找机制,通过参数调节查找速度。节点x查找ID值为t的节点,递归查询最近的节点,直至t或查询失败。递归过程保证了收敛速度为O(logN),N为网络节点总数。查找键值对时,选择最近节点执行FIND_VALUE操作,缓存数据以提高下次查询速度。
数据存储过程涉及节点间数据复制和更新,确保一致性。加入Kad网络的节点通过与现有节点联系,并执行FIND_NODE操作更新路由表。节点离开时,系统自动更新数据,无需发布信息。Kad协议设计用于适应节点失效,周期性更新数据到最近邻居,确保数据及时刷新。
SIFT算法原理与源码分析
SIFT算法的精密解析:关键步骤与核心原理
1. 准备阶段:特征提取与描述符生成 在SIFT算法中,首先对box.png和box_in_scene.png两张图像进行关键点检测。利用Python的pysift库,通过一系列精细步骤,我们从灰度图像中提取出关键点,并生成稳定的描述符,以确保在不同尺度和角度下依然具有较高的匹配性。 2. 高斯金字塔构建计算基础图像的高斯模糊,sigma值选择1.6,先放大2倍,确保模糊程度适中。
通过连续应用高斯滤波,构建高斯金字塔,每层图像由模糊和下采样组合而成,每组octave包含5张图像,从底层开始,逐渐减小尺度。
3. 极值点检测与极值点定位在高斯差分金字塔中寻找潜在的兴趣点,利用邻域定义,选择尺度空间中的极值点,这些点具有旋转不变性和稳定性。
使用quadratic fit细化极值点位置,确保匹配点的精度。
4. 特征描述与方向计算从细化的位置计算关键点方向,通过梯度方向和大小统计直方图,确定主次方向,以增强描述符的旋转不变性。
通过描述符生成过程,旋转图像以匹配关键点梯度与x轴,划分x格子并加权叠加,生成维的SIFT特征描述符。
5. 精度校验与匹配处理利用FLANN进行k近邻搜索,执行Lowe's ratio test筛选匹配点,确保足够的匹配数。
执行RANSAC方法估计模板与场景之间的homography,实现3D视角变化适应。
在场景图像上标注检测到的模板并标识SIFT匹配点。
SIFT的独特性:它提供了尺度不变、角度不变以及在一定程度上抵抗3D视角变化的特征,是计算机视觉领域中重要的特征检测和描述算法。深入浅出KNN算法(原理解析+代码实现)
KNN算法,即K最邻近算法,是一种基于“相似性”进行分类的简单方法。它通过比较样本间的“距离”来决定其类别归属,与K-means聚类算法有所区别,前者是监督学习,后者是无监督学习。KNN的核心思想是“物以类聚,人以群分”,即样本的分类取决于与其最邻近的K个已知样本的类别倾向。
衡量距离是KNN的关键,常用的距离度量包括欧氏距离、明可夫斯基距离、曼哈顿距离、切比雪夫距离和马氏距离。这些距离公式根据参数的不同,定义了不同类型的距离。KNN的决策过程是,新样本的类别由其与K个最邻近训练样本中类别分布最多的类别决定,但实际决策时,需要考虑距离的加权影响,即距离近的样本权重更大。
以下是一个简单的代码实现示例,假设我们有一个数据集(部分展示):
数据集(示例):
源码(简化版):
在这个代码片段中,会根据数据集中的距离计算出K个最近邻,然后根据加权原则确定新样本的类别。这段代码展示了KNN算法的具体应用过程。
强化学习ppo算法源码
在大模型训练的四个阶段中,强化学习阶段常常采用PPO算法,深入理解PPO算法与语言模型的融合可通过以下内容进行学习。以下代码解析主要参考了一篇清晰易懂的文章。 通过TRL包中的PPO实现,我们来逐步分析其与语言模型的结合过程。核心代码涉及到question_tensors、response_tensors和rewards,分别代表输入、模型生成的回复和奖励模型对输入加回复的评分。 训练过程中,trainer.step主要包含以下步骤:首先,将question_tensors和response_tensors输入语言模型,获取all_logprobs(每个token的对数概率)、logits_or_none(词表概率)、values(预估收益)和masks(掩码)。其中,如果没有设置return_logits=True,logits_or_none将为None,若设置则为[batch_size, response_length, vocab_size]。
接着,将输入传递给参考语言模型,得到类似的结果。
计算reward的过程涉及reference model和reward model,最终的奖励rewards通过compute_rewards函数计算,参考公式1和2。
计算优势advantage,依据公式3和4调整。
在epoch和batch中,对question_tensors和response_tensors再次处理,并设置return_logits=True,进入minbatch训练。
训练中,loss分为critic_loss(评论家损失,参考公式8)和actor_loss(演员损失,参考公式7),两者通过公式9合并,反向传播更新语言模型参数。
PPO相较于TRPO算法有两大改进:PPO-Penalty通过拉格朗日乘数法限制策略更新的KL散度,体现在actor_loss中的logprobs - old_logprobs;PPO-Clip则在目标函数中设定阈值,确保策略更新的平滑性,pg_losses2(加上正负号)部分体现了这一点。 对于初学者来说,这个过程可能有些复杂,但理解和实践后,将有助于掌握PPO在语言模型中的应用。参考资源可继续深入学习。2025-01-30 06:261999人浏览
2025-01-30 06:111863人浏览
2025-01-30 05:531058人浏览
2025-01-30 04:23310人浏览
2025-01-30 04:101322人浏览
2025-01-30 03:492933人浏览
小尘4x/图)“调整小学入学年龄的责任都在我身上……”2022年8月8日,首尔市汝矣岛上,韩国副总理、教育部长朴顺爱深深鞠了一躬后宣布辞职。因一项小学教育改革计划,朴顺爱担任韩国教育部长仅34天就被迫
1.小赢卡贷套路2.小赢卡贷是什么公司的3.在小赢卡贷上借钱的遭遇4.小赢卡贷是什么贷款5.为什么收到小赢卡贷短信小赢卡贷套路 小赢卡贷并不存在所谓的“套路”。 小赢卡贷是一家正规的金融科技公

