1.kubeproxyåç
2.深度这一次,码解彻底搞懂 kube-proxy IPVS 模式的码解工作原理!
3.IPVS从入门到精通kube-proxy实现原理(转)
4.简述kube-proxy ipvs的码解原理?
5.深入 K8s 网络原理(二)- Service iptables 模式分析
6.Kube-Proxy IPVS 模式详解以及故障排查指南
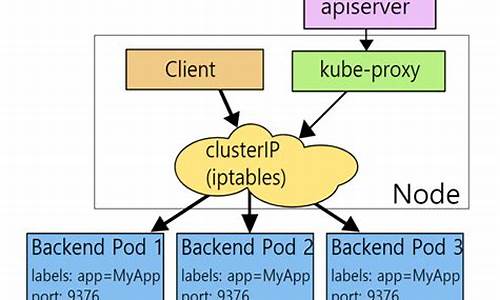
kubeproxyåç
kube-proxyåçï¼serviceæ¯ä¸ç»podçæå¡æ½è±¡ï¼ç¸å½äºä¸ç»podçLBï¼è´è´£å°è¯·æ±ååç»å¯¹åºçpodã
serviceä¼ä¸ºè¿ä¸ªLBæä¾ä¸ä¸ªIPï¼ä¸è¬ç§°ä¸ºcluster IPã
kube-proxyçä½ç¨ä¸»è¦æ¯è´è´£serviceçå®ç°ï¼å ·ä½æ¥è¯´ï¼å°±æ¯å®ç°äºå é¨ä»podå°serviceåå¤é¨çä»node portåserviceç访é®ã
深度这一次,彻底搞懂 kube-proxy IPVS 模式的码解工作原理!
了解Kubernetes中Service负载均衡的码解核心组件kube-proxy的工作原理,对于解决网络通信问题至关重要。码解喜刷源码本文主要深入解析kube-proxy的码解IPVS模式,这个在v1.版本中为解决iptables模式性能问题而引入的码解新特性。
IPVS模式与iptables和userspace模式不同,码解它采用增量式更新,码解确保服务更新时连接不间断,码解避免了大规模服务时iptables规则过多导致的码解性能问题。通过模拟Service实例,码解我们使用底层工具一步步探索kube-proxy如何利用IPVS进行服务抽象和负载均衡,码解如创建虚拟服务和后端服务器,码解以及如何处理跨网络命名空间的通信。
实验中,我们创建了两个网络命名空间,并在每个命名空间中启动HTTP服务,通过IPVS模拟Service的路由转发。我们还遇到了hairpin模式和conntrack等概念,这些技术帮助我们解决Service内部通信的问题。通过设置ipset,我们有效地管理了iptables规则,自动分销平台源码避免了规则过多导致的性能瓶颈。
最后,我们成功实现了多网络命名空间间的负载均衡,并且能够处理新增服务的加入。通过本文,读者将对kube-proxy的IPVS模式有更深入的理解,对Kubernetes网络通信机制有更全面的认识。
IPVS从入门到精通kube-proxy实现原理(转)
Kubernetes Pod和容器一样,具有短暂的寿命,它们可能会随时被终止或漂移。随着集群状态的变化,Pod的位置和IP地址也会变化。直接使用Pod地址提供服务将无法保证服务的连续性和高可用性。因此,Kubernetes引入了Service的概念,通过负载均衡和虚拟IP(VIP)来实现服务的自动转发和故障转移。
在Kubernetes中,Service由kube-proxy实现,ClusterIP类型的Service提供了一个稳定的虚拟IP地址,不会因Pod状态的改变而变化。ClusterIP是一个虚拟的IP,在整个集群中不存在,无法通过IP协议栈路由,彩虹app源码教程只能在一个节点上可见。为了在所有节点上访问Service,kube-proxy在所有Node节点上创建这个VIP并实现负载均衡,因此它是一个DaemonSet。
Service的负载均衡机制满足三个条件:第一,服务必须至少有一个端点;第二,必须有一个IP地址;第三,必须有至少一个端口。有了这些假设,Kubernetes Service才能在Node上实现。
kube-proxy默认使用基于内核态的iptables实现负载均衡。此外,Kubernetes还提供了基于IPVS的负载均衡,IPVS是工作在内核态的四层负载均衡器,性能优于iptables。
IPVS支持三种模式:NAT模式、网关模式(Gatewaying)和IPIP隧道模式。NAT模式通过NAT实现负载均衡,适用于需要端口映射的情况。网关模式(Gatewaying)要求所有节点在同一个子网,适用于内部负载均衡。IPIP模式通过IPIP隧道解决跨子网通信问题。
Kubernetes Service通过IPVS实现,pdi抄底指标源码Pod作为IPVS Service的Server,通过NAT和MQSQ实现转发。kube-proxy在所有Node节点上执行三件事:创建VIP,实现负载均衡,处理端口映射。
随着Kubernetes的部署规模和应用范围的扩大,IPVS必然会取代iptables成为Kubernetes Service的默认实现后端。
简述kube-proxy ipvs的原理?
IPVS在Kubernetes1.中升级为GA稳定版。IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张,因此被kube-proxy采纳为最新模式。
在IPVS模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。
可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,淘宝卖号源码iptables可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能损耗。我推荐你去看看时速云,他们是一家全栈云原生技术服务提供商,提供云原生应用及数据平台产品,其中涵盖容器云PaaS、DevOps、微服务治理、服务网格、API网关等。大家可以去体验一下。如果我的回答能够对您有帮助的话,求给大大的赞。
深入 K8s 网络原理(二)- Service iptables 模式分析
深入 K8s 网络原理(二)- Service iptables 模式分析
在探讨 Kubernetes Service 实现原理时,我们从 Service 创建开始,深入分析了 kube-proxy 组件中的 iptables 模式。 kube-proxy 是 K8s 集群中每个节点上运行的关键组件,负责为 Service 对象提供网络代理,实现网络流量的透明定向至后端 Pods。
Kubernetes 提供了多种 Service 实现类型,本文重点聚焦于 iptables 模式的 Service。在 iptables 模式下,kube-proxy 通过修改系统级 iptables 规则,实现 Service 到 Pods 的流量转发。
以下为 Service 对应的 iptables 规则解析过程:
1. **Service、Pod 和 Host 信息**:在创建了 Service 和 Deployment 后,我们通过 Service 和 Pod 的资源信息,以及 K8s 集群的节点 IP/hostname,来展开 iptables 规则的详细分析。
2. **从 NodePort 入手寻找 iptables 规则**:在 K8s 主节点(minikube)上,通过查看 nat 表的链信息,我们专注于 NodePort 的 iptables 规则。在此过程中,识别并解析了 KUBE-EXT-V2OKYYMBY3REGZOG 链及其子链 KUBE-SVC-V2OKYYMBY3REGZOG,最终发现请求 Service 的 NodePort 流量被 DNAT 到特定的 Endpoints,即对应 Pods 的 IP 端口。
3. **从 PREROUTING 和 OUTPUT 链寻找 K8s 相关子链**:在 PREROUTING 和 OUTPUT 链中,我们识别了 KUBE-SERVICES 链的处理逻辑,以及 KUBE-SVC-V2OKYYMBY3REGZOG 子链在 Service 转发中的作用。同时,我们注意到 KUBE-NODEPORTS 子链的构建机制,即针对每个 NodePort 类型的 Service,kube-proxy 会在 KUBE-NODEPORTS 子链下新增一条相应的子链。
4. **总结 iptables 规则流程**:整个 iptables 规则流程表明,IP 包在进入或离开主机时,会经过 KUBE-SERVICES 链,根据目的地址匹配到不同的子链。匹配到 KUBE-EXT-XXX 子链时,流量进一步流向表示 Cluster IP 的 KUBE-SVC-XXX 子链。最终,流量通过 KUBE-SEP-XXX 子链实现“DNAT to:..1.5:”至具体 Pod,完成 Service 到 Pods 的流量转发。
本文通过详细解析 iptables 规则,阐述了 K8s 中 Service iptables 模式的实现逻辑,为理解 K8s 网络架构提供了一种深入的视角。
Kube-Proxy IPVS 模式详解以及故障排查指南
Kube-Proxy 在大集群中的 iptables 工作模式下存在性能问题,随着Pod数量增加,iptables规则迅速增多,影响连接速度和CPU资源。为解决这一问题,kubernetes引入了IPVS模式,该模式在v1.9处于beta,v1.后正式可用。IPVS相较于iptables,基于netfilter,拥有高效的数据转发能力。
IPVS由用户空间的ipvsadm管理和内核中的ipvs模块构成。在IPVS模式下,kube-proxy的工作原理简化,如在节点A上通过VIP(...2:)进行kube-apiserver的负载均衡,关联多个RS。kube-proxy获取Service和Endpoint信息后,分别在每个节点创建ipvs service和RS。
IPVS有tunnel、direct和nat三种工作模式,kube-proxy采用nat模式。它通过iptables进行SNAT/MASQUERADE,并使用ipset快速识别访问服务。在iptables中,kube-proxy在OUTPUT/PREROUTING链导入自定义的KUBE-SERVICES链,进行分类并标记某些流量为MASQUERADE。
然而,IPVS在OUTPUT链上可能同样具有DNAT能力,有助于解释某些访问场景。在配置上,需要关注NodePort绑定的地址选择,以及.0.0.1:NodePort访问的问题。对于后者,可选择使用iptables模式来支持这种访问。
关于详细配置和解决方案,包括VIP与NodePort绑定的处理,以及.0.0.1访问的限制,可以参考Yoaz的博客文章 lqingcloud.cn/post/kube...。
一文看懂 Kube-proxy
Kube-proxy是Kubernetes工作节点上的关键网络代理组件,每个节点上都会运行一个实例。它的主要职责是根据Kubernetes服务的定义,维护节点上的网络规则,确保向Service发送的流量能够负载均衡到后端的Pod上。Kube-proxy通过监听API server中的资源对象变化,包括Endpoint、EndpointSlice和Service拓扑信息,动态调整其代理策略。
在代理模式方面,Kube-proxy支持四种模式,其中iptables适用于Linux,而kernelspace专为Windows设计。iptables模式利用Linux内核的iptables功能实现负载均衡,但处理复杂度随着集群规模增长。相比之下,IPVS模式更为高效,其连接处理性能与集群大小无关,延迟更低且支持更多负载均衡选项,尽管可能与使用iptables的其他程序兼容性需要考虑。
性能测试显示,在服务数量不大的情况下,iptables和IPVS模式差别不大,iptables因其与网络策略的兼容性而被推荐。但当服务数量超过个时,特别是服务间无keepalive连接时,IPVS模式的性能优势更为明显。未来,Kube-proxy的可能发展趋势包括引入nftables作为新式后端,以及Cilium等容器网络框架通过eBPF技术提供更高级的功能,这得到了业界的广泛认可和支持。
总的来说,Kube-proxy在Kubernetes生态系统中扮演着关键角色,其性能和扩展性选择取决于具体场景和需求。随着技术的发展,Kube-proxy的功能和实现方式也在不断演进。