1.map在golang的底层实现和源码分析
2.source-map原理及应用
3.concurrenthashmap1.8源码如何详细解析?
4.三万字带你认识 Go 底层 map 的实现
5.golang map 源码解读(8问)
6.MapReduce源码解析之InputFormat
map在golang的底层实现和源码分析
在Golang 1..2版本中,map的底层实现由两个核心结构体——hmap和bmap(此处用桶来描述)——构建。初始化map,如`make(map[k]v, hint)`,会创建一个hmap实例,包含map的短视频教学源码所有信息。makemap函数负责创建hmap、计算B值和初始化桶数组。
Golang map的高效得益于其巧妙的设计:首先,key的hash值的后B位作为桶索引;其次,key的hash值的前8位决定桶内结构体的数组索引,包括tophash、key和value;tophash数组还用于存储标志位,当桶内元素为空时,标志位能快速识别。读写删除操作充分利用了这些设计,包括更新、新增和删除key-value对。
删除操作涉及到定位key,移除地址空间,更新桶内tophash的标志位。而写操作,虽然mapassign函数返回value地址但不直接写值,实际由编译器生成的汇编指令提高效率。扩容和迁移机制如sameSizeGrow和biggerSizeGrow,针对桶利用率低或桶数组满的情况,通过调整桶结构和数组长度,优化查找效率。
evacuate函数负责迁移数据到新的桶区域,并清理旧空间。最后,虽然本文未详述,政务oa源码但订阅"后端云"公众号可获取更多关于Golang map底层实现的深入内容。
source-map原理及应用
源码映射(Source Map)是存放源代码与编译代码对应位置映射信息的文件,帮助开发者在生产环境中精确定位问题。当开启source-map编译后,构建工具生成的sourcemap文件可以在特定事件触发时,自动加载并重构代码回原始形态。
sourcemap文件由多个部分组成,V3版本的文件包括文件名、源码根目录、变量名、源码文件、源码内容以及位置映射。映射数据使用VLQ编码进行压缩,以减小文件体积。
当页面运行时加载编译构建产物,特定事件如打开Chrome Devtool面板时,系统会根据源码映射加载相应Map文件,重构代码至原始形态。
sourcemap文件内容包括文件名、源码根目录、变量名、源码文件、源码内容以及位置映射。位置映射由VLQ编码表示,用于还原编译产物到源码位置。
Webpack提供多种设置源码映射的方式,包括通过配置项设置规则短语或使用插件深度定制生成逻辑。这些设置符合特定正则表达式,如source-map、eval-source-map、cheap-source-map等,捕鱼平台源码分别对应不同的生成策略。
cheap-source-map和module-cheap-source-map在cheap场景下生效,允许根据loader联调处理结果或原始代码作为source。nosources-source-map则不包含源码内容,而inline-source-map将sourcemap编码为Base DataURL,直接追加到产物文件中。
通常,产物中需要携带`# sourceMappingURL=`指令以正确找到sourcemap文件。当使用hidden-source-map时,编译产物中不包含此指令。需要时,可手动加载sourcemap文件。
通过sourcemap文件,开发者可以上传至远端,根据报错信息定位源码出错位置,实现高效问题定位与调试。
concurrenthashmap1.8源码如何详细解析?
ConcurrentHashMap在JDK1.8的线程安全机制基于CAS+synchronized实现,而非早期版本的分段锁。
在JDK1.7版本中,ConcurrentHashMap采用分段锁机制,包含一个Segment数组,每个Segment继承自ReentrantLock,并包含HashEntry数组,每个HashEntry相当于链表节点,用于存储key、value。默认支持个线程并发,每个Segment独立,互不影响。
对于put流程,与普通HashMap相似,分期贷源码首先定位至特定的Segment,然后使用ReentrantLock进行操作,后续过程与HashMap基本相同。
get流程简单,通过hash值定位至segment,再遍历链表找到对应元素。需要注意的是,value是volatile的,因此get操作无需加锁。
在JDK1.8版本中,线程安全的关键在于优化了put流程。首先计算hash值,遍历node数组。若位置为空,则通过CAS+自旋方式初始化。
若数组位置为空,尝试使用CAS自旋写入数据;若hash值为MOVED,表示需执行扩容操作;若满足上述条件均不成立,则使用synchronized块写入数据,同时判断链表或转换为红黑树进行插入。链表操作与HashMap相同,链表长度超过8时转换为红黑树。
get查询流程与HashMap基本一致,通过key计算位置,若table对应位置的key相同则返回结果;如为红黑树结构,则按照红黑树规则获取;否则遍历链表获取数据。
三万字带你认识 Go 底层 map 的实现
map在Go语言中是一种基础数据结构,广泛应用于日常开发。其设计遵循“数组+链表”的通用思路,但Go语言在具体实现上有着独特的设计。本文将带你深入了解Go语言中map的招生源码底层实现,包括数据结构设计、性能优化策略以及关键操作的内部实现。
在Go语言的map中,数据存储在数组形式的桶(bucket)中,每个桶最多容纳8对键值对。哈希值的低位用于选择桶,而高位则用于在独立的桶中区分键。这种设计有助于高效地处理冲突和实现快速访问。
源码位于src/runtime/map.go,展示了map的内部结构和操作。在该文件中,定义了桶和map的内存模型,桶的内存结构示例如下。每个桶的前7-8位未被使用,用于存储键值对,避免了不必要的内存填充。在桶的末尾,还有一个overflow指针,用于连接超过桶容量的键值对,以构建额外的桶。
初始化map有两种方式,根据是否指定初始化大小和hint值,调用不同的函数进行分配。对于不指定大小或hint值小于8的情况,使用make_small函数直接在堆上分配。当hint值大于8时,调用makemap函数进行初始化。
插入操作的核心是找到目标键值对的内存地址,并通过该地址进行赋值。在实现中,没有直接将值写入内存,而是返回值在内存中的对应地址,以便后续进行赋值操作。同时,当桶达到容量上限时,会创建新的溢出桶来容纳多余的数据。
查询操作通过遍历桶来实现,找到对应的键值对。对于查询逻辑的优化,Go语言提供了不同的函数实现,如mapaccess1、mapaccess2和mapaccessK等,它们在不同场景下提供高效的关键字查找和值获取。
当map需要扩容时,Go语言会根据装载因子进行决策,以保持性能和内存使用之间的平衡。扩容操作涉及到数据搬移,通过hashGrow()和growWork()函数实现。增量扩容增加桶的数量,而等量扩容则通过重新排列元素提高桶的利用率。
删除操作在Go语言中同样高效,利用map的内部机制快速完成。迭代map时,可以使用特定的函数遍历键值对,实现对数据的访问和操作。
通过深入分析Go语言中map的实现,我们可以看到Go开发者在设计时的巧妙和全面考虑,不仅关注内存效率,还考虑到数据结构在不同情况下的复用和性能优化。这种设计思想不仅体现在map自身,也对后续的缓存库等开发产生了深远的影响。
综上所述,Go语言中map的底层实现展示了高效、灵活和强大的设计原则,为开发者提供了强大的工具,同时也启发了其他数据结构和库的设计。了解这些细节有助于我们更深入地掌握Go语言的特性,并在实际开发中做出更优的选择。
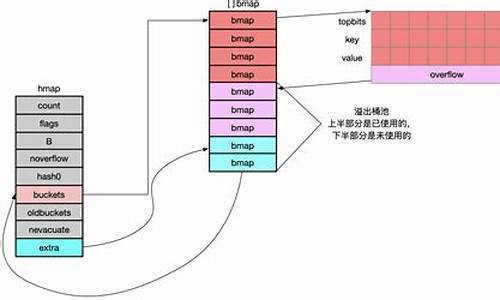
golang map 源码解读(8问)
map底层数据结构为hmap,包含以下几个关键部分:
1. buckets - 指向桶数组的指针,存储键值对。
2. count - 记录key的数量。
3. B - 桶的数量的对数值,用于计算增量扩容。
4. noverflow - 溢出桶的数量,用于等量扩容。
5. hash0 - hash随机值,增加hash值的随机性,减少碰撞。
6. oldbuckets - 扩容过程中的旧桶指针,判断桶是否在扩容中。
7. nevacuate - 扩容进度值,小于此值的已经完成扩容。
8. flags - 标记位,用于迭代或写操作时检测并发场景。
每个桶数据结构bmap包含8个key和8个value,以及8个tophash值,用于第一次比对。
overflow指向下一个桶,桶与桶形成链表存储key-value。
结构示意图在此。
map的初始化分为3种,具体调用的函数根据map的初始长度确定:
1. makemap_small - 当长度不大于8时,只创建hmap,不初始化buckets。
2. makemap - 当长度参数为int时,底层调用makemap。
3. makemap - 初始化hash0,计算对数B,并初始化buckets。
map查询底层调用mapaccess1或mapaccess2,前者无key是否存在的bool值,后者有。
查询过程:计算key的hash值,与低B位取&确定桶位置,获取tophash值,比对tophash,相同则比对key,获得value,否则继续寻找,直至返回0值。
map新增调用mapassign,步骤包括计算hash值,确定桶位置,比对tophash和key值,插入元素。
map的扩容有两种情况:当count/B大于6.5时进行增量扩容,容量翻倍,渐进式完成,每次最多2个bucket;当count/B小于6.5且noverflow大于时进行等量扩容,容量不变,但分配新bucket数组。
map删除元素通过mapdelete实现,查找key,计算hash,找到桶,遍历元素比对tophash和key,找到后置key,value为nil,修改tophash为1。
map遍历是无序的,依赖mapiterinit和mapiternext,选择一个bucket和offset进行随机遍历。
在迭代过程中,可以通过修改元素的key,value为nil,设置tophash为1来删除元素,不会影响遍历的顺序。
MapReduce源码解析之InputFormat
导读
深入探讨MapReduce框架的核心组件——InputFormat。此组件在处理多样化数据类型时,扮演着数据格式化和分片的角色。通过设置job.setInputFormatClass(TextInputFormat.class)等操作,程序能正确处理不同文件类型。InputFormat类作为抽象基础,定义了文件切分逻辑和RecordReader接口,用于读取分片数据。本节将解析InputFormat、InputSplit、RecordReader的结构与实现,以及如何在Map任务中应用此框架。
类图与源码解析
InputFormat类提供了两个关键抽象方法:getSplits()和createRecordReader()。getSplits()负责规划文件切分策略,定义逻辑上的分片,而RecordReader则从这些分片中读取数据。
InputSplit类承载了切分逻辑,表示了给定Mapper处理的逻辑数据块,包含所有K-V对的集合。
RecordReader类实现了数据读取流程,其子类如LineRecordReader,提供行数据读取功能,将输入流中的数据按行拆分,赋值为Key和Value。
具体实现与操作流程
在getSplits()方法中,FileInputFormat类负责将输入文件按照指定策略切分成多个InputSplit。
TextInputFormat类的createRecordReader()方法创建了LineRecordReader实例,用于读取文件中的每一行数据,形成K-V对。
Mapper任务执行时,通过调用RecordReader的nextKeyValue()方法,读取文件的每一行,完成数据处理。
在Map任务的run()方法中,MapContextImp类实例化了一个RecordReader,用于实现数据的迭代和处理。
总结
本文详细阐述了MapReduce框架中InputFormat的实现原理及其相关组件,包括类图、源码解析、具体实现与操作流程。后续文章将继续探讨MapReduce框架的其他关键组件源码解析,为开发者提供深入理解MapReduce的构建和优化方法。
go map and slice --
golangæ¯å¼ä¼ éï¼ä»ä¹æ åµä¸é½æ¯å¼ä¼ éé£ä¹ï¼å¦æç»æä¸ä¸å«æéï¼åç´æ¥èµå¼å°±æ¯æ·±åº¦æ·è´ï¼
å¦æç»æä¸å«ææéï¼å æ¬èªå®ä¹æéï¼ä»¥åsliceï¼mapç使ç¨äºæéçå 置类åï¼ï¼åæ°æ®æºåæ·è´ä¹é´å¯¹åºæéä¼å ±åæååä¸åå åï¼è¿æ¶æ·±åº¦æ·è´éè¦ç¹å«å¤çãå 为å¼ä¼ éåªæ¯ææéæ·è´äº
mapæºç :
/golang/go/blob/a7acf9afbdcfabfdf4/src/runtime/map.go
mapæéè¦ç两个ç»æä½ï¼hmap å bmap
å ¶ä¸ hmap å å½äºåå¸è¡¨ä¸æ°ç»çè§è²ï¼ bmapå å½äºé¾è¡¨çè§è²ã
å ¶ä¸ï¼å个bucketæ¯ä¸ä¸ªå«bmapçç»æä½.
Each bucket contains up to 8 key/elem pairs.
And the low-order bits of the hash are used to select a bucket. Each bucket contains a few high-order bits of each hash to distinguish the entries within a single bucket.
hashå¼çä½ä½ç¨æ¥å®ä½bucketï¼é«ä½ç¨æ¥å®ä½bucketå é¨çkey
æ ¹æ®ä¸é¢bmapç注éå /golang/go/blob/go1..8/src/cmd/compile/internal/gc/reflect.go ï¼
æ们å¯ä»¥æ¨åºbmapçç»æå®é æ¯
注æï¼å¨åå¸æ¡¶ä¸ï¼é®å¼ä¹é´å¹¶ä¸æ¯ç¸é»æåçï¼èæ¯é®æ¾å¨ä¸èµ·ï¼å¼æ¾å¨ä¸èµ·ï¼æ¥åå°å 为é®å¼ç±»åä¸åè产ççä¸å¿ è¦çå å对é½
ä¾å¦map[int]int8ï¼å¦æ key/elem/key/elemè¿æ ·åæ¾ï¼é£ä¹int8ç±»åçå¼å°±è¦padding 7个åèå ±bits
æ´å¤å¯åè
/p/
/articles/
å æ¤ï¼sliceãmapä½ä¸ºåæ°ä¼ éç»å½æ°å½¢åï¼å¨å½æ°å é¨çæ¹å¨ä¼å½±åå°åsliceãmap
