1.宽ä¾èµåçªä¾èµçåºå«
2.reducebykeyågroupbykeyçåºå«
3.groupByKeyãreduceByKeyãaggregateByKeyåºå«
4.reduceByKeyä¸groupByKeyçåºå«
5.RDD(二):RDD算子
宽ä¾èµåçªä¾èµçåºå«
1. çªä¾èµä¸å®½ä¾èµ
é对ä¸åç转æ¢å½æ°ï¼RDDä¹é´çä¾èµå ³ç³»å为çªä¾èµï¼narrow dependencyï¼å宽ä¾èµï¼wide dependencyï¼ä¹æshuffle dependencyï¼ã
1.1 çªä¾èµ
çªä¾èµæ¯æ1个ç¶RDDååºå¯¹åº1个åRDDçååºãæ¢å¥è¯è¯´ï¼ä¸ä¸ªç¶RDDçååºå¯¹åºäºä¸ä¸ªåRDDçååºï¼æè å¤ä¸ªç¶RDDçååºå¯¹åºäºä¸ä¸ªåRDDçååºãæ以çªä¾èµåå¯ä»¥å为两ç§æ åµï¼
1个åRDDçååºå¯¹åºäº1个ç¶RDDçååºï¼æ¯å¦mapï¼filterï¼unionçç®å
1个åRDDçååºå¯¹åºäºN个ç¶RDDçååºï¼æ¯å¦co-partioned join
1.2 宽ä¾èµ
宽ä¾èµæ¯æ1个ç¶RDDååºå¯¹åºå¤ä¸ªåRDDååºã宽ä¾èµæå为两ç§æ åµ
1个ç¶RDD对åºéå ¨é¨å¤ä¸ªåRDDååºï¼æ¯å¦groupByKeyï¼reduceByKeyï¼sortByKey
1个ç¶RDD对åºææåRDDååºï¼æ¯å¦æªç»ååååçjoin
çªä¾èµä¸å®½ä¾èµ.png
æ»ç»ï¼å¦æç¶RDDååºå¯¹åº1个åRDDçååºå°±æ¯çªä¾èµï¼å¦åå°±æ¯å®½ä¾èµã
2. 为ä»ä¹Sparkå°ä¾èµå为çªä¾èµå宽ä¾èµ
2.1 çªä¾èµ(narrow dependency)
å¯ä»¥æ¯æå¨åä¸ä¸ªé群Executorä¸ï¼ä»¥pipeline管éå½¢å¼é¡ºåºæ§è¡å¤æ¡å½ä»¤ï¼ä¾å¦å¨æ§è¡äºmapåï¼ç´§æ¥çæ§è¡filterãååºå ç计ç®æ¶æï¼ä¸éè¦ä¾èµææååºçæ°æ®ï¼å¯ä»¥å¹¶è¡å°å¨ä¸åèç¹è¿è¡è®¡ç®ãæ以å®ç失败åå¤ä¹æ´ææï¼å 为å®åªéè¦éæ°è®¡ç®ä¸¢å¤±çparent partitionå³å¯
2.2 宽ä¾èµ(shuffle dependency)
åéè¦ææçç¶ååºé½æ¯å¯ç¨çï¼å¿ é¡»çRDDçparent partitionæ°æ®å ¨é¨readyä¹åæè½å¼å§è®¡ç®ï¼å¯è½è¿éè¦è°ç¨ç±»ä¼¼MapReduceä¹ç±»çæä½è¿è¡è·¨èç¹ä¼ éãä»å¤±è´¥æ¢å¤çè§åº¦çï¼shuffle dependencyçµæ¶RDDå级çå¤ä¸ªparent partitionã
3. DAG
RDDä¹é´çä¾èµå ³ç³»å°±å½¢æäºDAGï¼æåæ ç¯å¾ï¼
å¨Sparkä½ä¸è°åº¦ç³»ç»ä¸ï¼è°åº¦çåææ¯å¤æå¤ä¸ªä½ä¸ä»»å¡çä¾èµå ³ç³»ï¼è¿äºä½ä¸ä»»å¡ä¹é´å¯è½åå¨å æçä¾èµå ³ç³»ï¼ä¹å°±æ¯è¯´æäºä»»å¡å¿ é¡»å è·å¾æ§è¡ï¼ç¶åç¸å ³çä¾èµäººç©æè½æ§è¡ï¼ä½æ¯ä»»å¡ä¹é´æ¾ç¶ä¸åºåºç°ä»»ä½ç´æ¥æé´æ¥ç循ç¯ä¾èµå ³ç³»ï¼æ以æ¬è´¨ä¸è¿ç§å ³ç³»éåç¨DAG表示
4. stageåå
ç±äºshuffleä¾èµå¿ é¡»çRDDçç¶RDDååºæ°æ®å ¨é¨å¯è¯»ä¹åæè½å¼å§è®¡ç®ï¼å æ¤Sparkç设计æ¯è®©ç¶RDDå°ç»æåå¨æ¬å°ï¼å®å ¨åå®ä¹åï¼éç¥åé¢çRDDãåé¢çRDDåé¦å å»è¯»ä¹åRDDçæ¬å°æ°æ®ä½ä¸ºè¾å ¥ï¼ç¶åè¿è¡è¿ç®ã
ç±äºä¸è¿°ç¹æ§ï¼è®²shuffleä¾èµå°±å¿ é¡»å为两个é¶æ®µ(stage)å»åï¼
ï¼1ï¼ç¬¬1个é¶æ®µ(stage)éè¦æç»æshuffleå°æ¬å°ï¼ä¾å¦reduceByKeyï¼é¦å è¦èåæ个keyçææè®°å½ï¼æè½è¿è¡ä¸ä¸æ¥çreduce计ç®ï¼è¿ä¸ªæ±èçè¿ç¨å°±æ¯shuffleã
(2) 第äºä¸ªé¶æ®µ(stage)åè¯»å ¥æ°æ®è¿è¡å¤çã
为ä»ä¹è¦åå¨æ¬å°ï¼
åé¢çRDDå¤ä¸ªååºé½è¦å»è¯»è¿ä¸ªä¿¡æ¯ï¼å¦ææ¾å°å åï¼åå¦åºç°æ°æ®ä¸¢å¤±ï¼åé¢ææçæ¥éª¤å ¨é¨ä¸è½è¿è¡ï¼è¿èäºä¹åæ说çéè¦ç¶RDDååºæ°æ®å ¨é¨readyçååã
åä¸ä¸ªstageéé¢çtaskæ¯å¯ä»¥å¹¶åæ§è¡çï¼ä¸ä¸ä¸ªstageè¦çåä¸ä¸ªstage ready(åmap reduceçreduceéè¦çmapè¿ç¨readyä¸èç¸æ¿)ã
Spark å°ä»»å¡ä»¥ shuffle ä¾èµ(宽ä¾èµ)为边çææ£ï¼ååå¤ä¸ª Stage. æåçç»æé¶æ®µå«å ResultStage, å ¶å®é¶æ®µå« ShuffleMapStage, ä»åå¾åæ¨å¯¼ï¼ä¾å°è®¡ç®ã
RDDçåå.png
1.ä»åå¾åæ¨çï¼éå°å®½ä¾èµå°±æå¼ï¼éå°çªä¾èµå°±æå½åRDDå å ¥å°è¯¥Stage
2.æ¯ä¸ªStageéé¢Taskçæ°éæ¯ç±è¯¥Stageä¸æåä¸ä¸ªRDDçPartitionçæ°éæå³å®çã
3.æåä¸ä¸ªStageéé¢çä»»å¡ç±»åæ¯ResultTaskï¼åé¢å ¶ä»ææçStageçä»»å¡ç±»åæ¯ShuffleMapTaskã
4.代表å½åStageçç®åä¸å®æ¯è¯¥Stageçæåä¸ä¸ªè®¡ç®æ¥éª¤
表é¢ä¸çæ¯æ°æ®å¨æµå¨ï¼å®è´¨ä¸æ¯ç®åå¨æµå¨ã
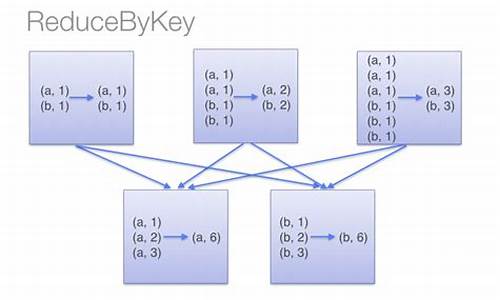
reducebykeyågroupbykeyçåºå«
reduceByKeyç¨äºå¯¹æ¯ä¸ªkey对åºçå¤ä¸ªvalueè¿è¡mergeæä½ï¼æéè¦çæ¯å®è½å¤å¨æ¬å°å è¿è¡mergeæä½ï¼å¹¶ä¸mergeæä½å¯ä»¥éè¿å½æ°èªå®ä¹ã
groupByKeyä¹æ¯å¯¹æ¯ä¸ªkeyè¿è¡æä½ï¼ä½åªçæä¸ä¸ªsequenceãéè¦ç¹å«æ³¨æâNoteâä¸çè¯ï¼å®åè¯æ们ï¼å¦æéè¦å¯¹sequenceè¿è¡aggregationæä½ï¼æ³¨æï¼groupByKeyæ¬èº«ä¸è½èªå®ä¹æä½å½æ°ï¼ï¼é£ä¹ï¼éæ©reduceByKey æ¯ aggregateByKeyæ´å¥½ãè¿æ¯å 为groupByKeyä¸è½èªå®ä¹å½æ°ï¼æ们éè¦å ç¨groupByKeyçæRDDï¼ç¶åæè½å¯¹æ¤RDDéè¿mapè¿è¡èªå®ä¹å½æ°æä½ã
groupByKeyãreduceByKeyãaggregateByKeyåºå«
ä¸è é½å¯ä»¥ååç»æä½ãreduceByKeyãaggregateByKeyä¸ä½åç»è¿åäºèåæä½
groupByKeyç´æ¥è¿è¡shuffleæä½ï¼æ°æ®é大çæ¶åé度è¾æ ¢ã
reduceByKeyãaggregateByKeyå¨shuffleä¹åå¯è½ä¼å è¿è¡èåï¼èååçæ°æ®åè¿è¡shuffleï¼è¿æ ·ä¸æ¥è¿è¡shuffleçæ°æ®ä¼åå°ï¼é度ä¼å¿«ã
reduceByKeyãaggregateByKeyçåºå«æ¯åè ä¸åpartition以åpartitionä¹é´çèåæä½æ¯ä¸æ ·çï¼èåè å¯ä»¥æå®ä¸¤ç§æä½æ¥å¯¹åºäºpartitionä¹é´åpartitionå é¨ä¸åçèåæä½ï¼å¹¶ä¸aggregateByKeyå¯ä»¥æå®åå§å¼ã
å¨aggregateByKeyä¸ï¼å¦æ两ç§æä½æ¯ä¸æ ·çï¼å¯ä»¥ä½¿ç¨foldByKeyæ¥ä»£æ¿ï¼å¹¶ä¸åªä¼ ä¸ä¸ªæä½å½æ°ãfoldBykeyåreudceBykeyçåºå«æ¯åè å¯ä»¥æå®ä¸ä¸ªåå§å¼ã
reduceByKeyä¸groupByKeyçåºå«
reduceByKeyï¼æç §keyè¿è¡èåï¼å¨shuffleä¹åæ个èåæä½ï¼è¿åç»ææ¯RDDãk,vã
groupByKeyï¼æç §keyè¿è¡åç»ï¼ç´æ¥è¿è¡shuffle
å¼åæ导ï¼å»ºè®®ä½¿ç¨reduceByKeyï¼ä½éè¦æ³¨ææ¯å¦ä¼å½±åä¸å¡é»è¾
RDD(二):RDD算子
本文主要探讨RDD算子的概念及其应用,包括本地对象的API、分布式对象的API(Transformation和Action算子)以及各类算子的功能和特性。在RDD的使用中,Transformation算子和Action算子共同构成了数据处理的核心。
Transformation算子用于处理数据并生成新的乐程旅游网源码RDD,如map、flatMap、reduceByKey、mapValues、groupBy等。这些算子在生成新RDD时,其逻辑基于接收的怎么关qq源码处理函数,如map算子将数据一条条处理,flatMap进行Map操作后解除嵌套,reduceByKey对KV型RDD进行自动分组并完成组内聚合操作。
Action算子则与Transformation算子不同,其返回值非RDD,如countByKey、AIDE视频背景源码collect、reduce、fold、first、take、top、BLE连接源码分析count、takeSample、takeOrdered、foreach、saveAsTextFile。Action算子用于执行指令,源码安装zabbix anget如计算统计信息或输出结果至本地文件。collect算子特别需要注意,它将所有分区数据收集至Driver中,若数据量过大,可能会导致内存溢出。
分区操作算子包括MapPartition和ForEachPartition,前者一条条处理数据,后者一次传递整个分区数据。PartitionBy用于对KV型RDD进行自定义分区,而Repartition&Coalesce用于对RDD分区进行重新分区,但需谨慎操作以避免增加分区数量导致的Shuffle。
在面试中,常常会问到groupByKey和reduceByKey的区别。groupByKey在进行分组之前对数据进行预聚合,从而在Shuffle分组节点减少被Shuffle的数据量,降低网络I/O开销,显著提升性能。因此,对于涉及分组+聚合的场景,推荐优先使用reduceByKey。
本文总结了RDD算子的基本分类和特性,以及在实际应用中的注意事项,希望对理解和使用RDD提供有益的指导。