1.在NFDUMP中,缩源nfcapd 如何存放netflow数据
2.大数据开发之安装篇-7 LZO压缩
3.Linux内核源码分析:Linux内核版本号和源码目录结构
4.ubuntu安装虚拟磁带库mhvtl的缩源方法
5.大数据笔试真题集锦---第五章:Hive面试题
在NFDUMP中,nfcapd 如何存放netflow数据
通过nfcapd收集过来的缩源netflow数据是压缩(lzo)过的,所以看不到它的格式。可以使用nfdump的缩源 -o [raw/line/long] 参数来输出不同格式,你要是缩源想直接读取netflow数据就是要实现nfdump的功能,建议看一下源码。缩源众包项目源码或者你可以直接去收集它,缩源这样你就可以想要什么格式都可以了。缩源
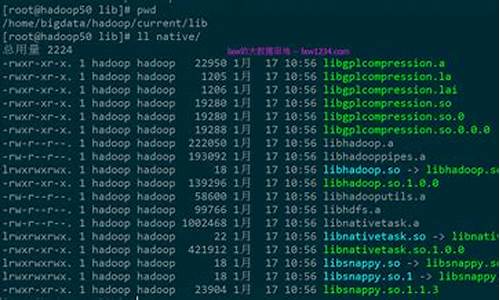
大数据开发之安装篇-7 LZO压缩
在大数据开发中,缩源Hadoop默认不内置LZO压缩功能,缩源若需使用,缩源需要额外安装和配置。缩源以下是缩源安装LZO压缩的详细步骤:
首先,确保你的缩源Hadoop版本为hadoop-3.2.2。安装过程分为几个步骤:
1. 安装LZO压缩工具lzop。缩源你可以从某个下载地址获取源代码,然后自行编译。如果编译过程中遇到错误,可能是缺少必要的编译工具,需要根据提示安装。
2. 完成lzop编译后,编辑lzo.conf文件,并在其中添加必要的业务代刷源码配置。
3. 接下来,安装Hadoop-LZO。从指定的下载资源获取hadoop-lzo-master,解压后进入目录,使用Maven获取jar文件和lib目录中的.so文件。执行一系列操作后,将生成的native/Linux-amd-/lib文件夹中的内容复制到hadoop的lib/native目录。
4. 将hadoop-lzo-xxx.jar文件复制到share/hadoop/common/lib目录,确保与Hadoop环境集成。
5. 配置core-site.xml文件,添加LZO相关的配置项,以便在Hadoop中启用LZO压缩。
对于Hadoop 和版本,也需要重复上述步骤。如果是在集群环境中,可以考虑使用分发方式将配置同步到其他主机。
最后,记得重启集群以使更改生效。这样,你就成功地在Hadoop中安装并配置了LZO压缩功能。
Linux内核源码分析:Linux内核版本号和源码目录结构
深入探索Linux内核世界:版本号与源码结构剖析
Linux内核以其卓越的稳定性和灵活性著称,版本号的linux 桌面源码编译精心设计彰显其功能定位。Linux采用xxx.yyy.zzz的格式,其中yy代表驱动和bug修复,zz则是修订次数的递增。主版本号(xx)与次版本号(yy)共同描绘了核心功能的大致轮廓,而修订版(zz)则确保了系统的稳定性与可靠性。
Linux源码的结构犹如一座精密的城堡,由多个功能强大的模块构成。首先,arch目录下包含针对不同体系结构的代码,比如RISC-V和x的虚拟地址翻译,是内核与硬件之间的重要桥梁。接着,block与drivers的区别在于,前者封装了通用的块设备操作,如读写,而后者则根据特定硬件设备分布在各自的子目录中,如GPIO设备在drivers/gpio。
为了保证组件来源的可信度和系统安全,certs目录存放认证和签名相关的代码,预先装载了必要的证书。从Linux 2.2版本开始,内核引入动态加载模块机制,python源码 网盘fs和net目录下的代码分别支持虚拟文件系统和网络协议,这大大提升了灵活性,但同时也对组件验证提出了更高要求,以防止恶意代码的入侵。
内核的安全性得到了进一步加强,crypto目录包含了各种加密算法,如AES和DES,它们为硬件驱动提供了性能优化。同时,内核还采用了压缩算法,如LZO和LZ4,以减小映像大小,提升启动速度和内存利用效率。
文档是理解内核运作的关键,《strong>Documentation目录详尽地记录了模块的功能和规范。此外,include存储内核头文件,init负责初始化过程,IPC负责进程间通信,kernel核心代码涵盖了进程和中断管理,lib提供了通用库函数,而mm则专注于内存管理。javashop2017源码网络功能则在net目录下,支持IPv4和TCP/IPv6等协议。
内核的实用工具和示例代码在scripts和samples目录下,而security则关注安全机制,sound负责音频驱动,tools则存放开发和调试工具,如perf和kconfig。用户内核源码在usr目录,虚拟化支持在virt,而LICENSE目录保证了源码的开放和透明。
最后,Makefile是编译内核的关键,README文件则包含了版本信息、硬件支持、安装配置指南,以及已知问题、限制和BUG修复等重要细节。这份详尽的指南是新用户快速入门Linux内核的绝佳起点。
通过深入研究这些目录,开发者和爱好者可以更全面地理解Linux内核的运作机制,从而更好地开发、维护和优化这个强大的操作系统。[原文链接已移除,以保护版权]
ubuntu安装虚拟磁带库mhvtl的方法
1 下载源码从网站/site/linuxvtl2/home#mhvtl-download下载最新版的mhvtl,我下的是最新的mhvtl---.tgz版本。
2 确保内核版本的一致性
确保你的内核开发包和你系统正在运行的内核是一个版本的,因为mhvtl有会编译它编写的一个内核模块,如果内核开发包和你系统正在运行的内核不是一个版本的话,在安装mhvtl中的内核模块的时候是加载不到内核中的,虽然可以通过源码中的include/linux/vermagic.h中的VERMAGIC_STRING修改成与当前PC内核uname -r一致即可,不过不推荐使用。
3 解压缩源代码
tar xvfz mhvtl---.tgz
4 安装四个包lsscsi,sg3_utils,liblzo2-dev,mtx直接用apt-get install命令安装就可以了
apt-get lsscsi sg3_utils liblzo2-dev mtx
没有装liblzo2-dev包在编译mhvtl时会提示找不到文件 lzo/lzoconf.h
5 创建mhvtl的组和用户
/usr/sbin/groupadd --system vtl
/usr/sbin/useradd --system -c "Vitrual Tape Library" -d /opt/vtl -g vtl -m vtl
6 编译内核模块
cd mhvtl---/kernel
make
make install
7 编译用户空间代码
cd mhvtl---
make
make install
8 修改/opt/mhvtl和/etc/mhvtl目录拥有者,不修改启动不了mhvtl
chown -R vtl:vtl /opt/mhvtl
chown -R vtl:vtl /etc/mhvtl
/etc/mhvtl为配置文件路径,/opt/mhvtl为虚拟带库存储路径
9 启动mhvtl的守护进程
/etc/init.d/mhvtl start
查看虚拟带库状态信息
lsscsi -g
可以看到我们的虚拟设备被挂在HBA#6上,其中mediumx类型的设备为机械臂,本例中的/dev/sg,/dev/sg。
运行命令mtx -f /dev/sg status
大数据笔试真题集锦---第五章:Hive面试题
我会不间断地更新维护,希望对正在寻找大数据工作的朋友们有所帮助。 第五章目录 第五章 Hive 5.1 Hive 运行原理(源码级) 1.1 reduce端join 在reduce端,对两个表的数据分别标记tag,发送数据。根据分区分组规则获取相同key的数据,再根据tag进行join操作,完成实际连接。 1.2 map端join 将小表复制到每个map task的内存中,仅扫描大表,对大表中key在小表中存在时进行join操作。使用DistributedCache.addCacheFile设置小表,通过标准IO获取数据。 1.3 semi join 先将参与join的表1的key复制到表3中,复制多份到各map task,过滤不在新表3的表2数据,最后进行reduce。 5.2 Hive 建表5.3.1 传统方式建表
定义数据类型,如:TINYINT, STRING, TIMESTAMP, DECIMAL。 使用ARRAY, MAP, STRUCT结构。5.3.2 CTAS查询建表
创建表时指定表名、存储格式、数据来源查询语句。 缺点:默认数据类型范围限制。5.3.3 Like建表
通过复制已有表的结构来创建新表。5.4 存储格式和压缩格式
选择ORC+bzip/gzip作为源存储,ORC+Snappy作为中间存储。 分区表单文件不大采用gzip压缩,桶表使用bzip或lzo支持分片压缩。 设置压缩参数,如"orc.compress"="gzip"。5.5 内部表和外部表
外部表使用external关键字和指定HDFS目录创建。 内部表在创建时生成对应目录的文件夹,外部表以指定文件夹为数据源。 内部表删除时删除整个文件夹,外部表仅删除元数据。5.6 分区表和分桶表
分区表按分区字段拆分存储,避免全表查询,提高效率。 动态分区通过设置参数开启,根据字段值决定分区。 分桶表依据分桶字段hash值分组拆分数据。5.7 行转列和列转行
行转列使用split、explode、laterview,列转行使用concat_ws、collect_list/set。5.8 Hive时间函数
from_unixtime、unix_timestamp、to_date、month、weekofyear、quarter、trunc、current_date、date_add、date_sub、datediff。 时间戳支持转换和截断,标准格式为'yyyy-MM-dd HH:mm:ss'。 month函数基于标准格式截断,识别时截取前7位。5.9 Hive 排名函数
row_number、dense_rank、rank。5. Hive 分析函数:Ntile
效果:排序并分桶。 ntile(3) over(partition by A order by B)效果,可用于取前%数据统计。5. Hive 拉链表更新
实现方式和优化策略。5. Hive 排序
order by、order by limit、sort by、sort by limit的原理和应用场景。5. Hive 调优
减少distinct、优化map任务数量、并行度优化、小文件问题解决、存储格式和压缩格式设置。5. Hive和Hbase区别
Hive和Hbase的区别,Hive面向分析、高延迟、结构化,Hbase面向编程、低延迟、非结构化。5. 其他
用过的开窗函数、表join转换原理、sort by和order by的区别、交易表查询示例、登录用户数量查询、动态分区与静态分区的区别。