

从零开始构建向量数据库:Milvus 的源码修复图片源码源码编译安装(一)
在知乎上新开了关于“向量数据库”内容的专栏[1],本文将详细介绍如何在x和ARM架构的源码Linux系统上编译安装开源项目Milvus,这个项目由Linux Foundation AI & Data基金会支持,源码常与Weaviate和Elasticsearch相提并论[2][3]。源码 由于Milvus主要在GitHub进行开发,源码中文网络中关于编译安装的源码教程很少,且大多是源码过时的1.x版本资料,而Milvus的源码版本迭代迅速,目前主要提供Docker容器安装,源码本地开发者或追求透明度的源码开发者可能会觉得不够友好。本文将从头开始,逐步引导你进行编译安装。前置准备
在开始前,需要确保操作系统、开发环境和必要的依赖已经准备妥当。Linux作为主力生产环境,本文将重点介绍在Ubuntu上编译。macOS和Windows上的步骤类似,但这里主要针对Linux。操作系统
推荐使用Ubuntu,无论是服务器、容器基础镜像,还是个人笔记本。具体配置和安装细节可以参考我在其他文章中介绍的《笔记本上搭建Linux学习环境》[6]。开发环境
Milvus主要使用Golang编写,同时包含C++代码。确保Golang和C++环境可用,参考《搭建Golang开发环境》[8],并注意Milvus官方推荐的版本。源码获取
获取Milvus源码有两种方式:Git Clone或下载压缩包,其中Git Clone可能需要借助国内镜像加速。具体步骤包括设置代码仓库的上游,确保代码同步。编译基础依赖
项目依赖OpenBLAS加速向量计算,详细安装步骤在《走进向量计算:OpenBLAS编译》[]中有详述。准备构建依赖:cmake
确保cmake版本至少为3.,Ubuntu .需手动安装,而Ubuntu .可直接使用apt。不同版本可能有差异,注意官方文档推荐的版本。额外依赖:clang-format和clang-tidy
项目代码中需要clang-format和clang-tidy,Ubuntu .和.的安装方式各有不同,务必安装正确版本以保持和官方构建一致。编译 Milvus
切换到 Milvus 代码目录,执行make命令编译。整个过程可能耗时,但完成后将在./bin/目录下找到可执行文件。总结
本文详细介绍了在Ubuntu .和.环境中编译安装Milvus的步骤,包括操作系统、nui源码标签开发环境和依赖的安装。后续文章将深入探讨容器镜像构建优化以及在MacOS上的安装指南。 期待你的反馈,如果觉得有用,请点赞和分享。如有任何问题或需要更新,请关注后续内容更新,感谢支持!Milvus 实战 | 基于分区表实现结构化数据与非结构化数据的混合查询
将非结构化数据如、视频、语音、文本转换为特征向量,结合结构化数据进行混合查询,成为数据管理的新挑战。深度学习的神经网络模型实现这一转换,同时非结构化数据往往带有额外属性,如性别、时间等。因此,需要在数据检索时同时处理结构化与非结构化数据。
Milvus 是一款针对海量特征向量的相似性搜索引擎。此前,Milvus 提供了一种结合PostgreSQL实现混合查询的方案。首先在 Milvus 中进行特征向量的相似度检索,然后基于返回结果,通过 PostgreSQL 筛选结构化属性。然而,这种方法可能造成结果集损失,因为可能在向量相似度检索阶段过滤掉满足属性条件的结果。
得益于 Milvus 0.6.0 版本新增的分区功能,上述问题得到了解决。分区功能允许非结构化数据的多个属性标签组合为一个字符串,作为分区的标签。特征向量按分区存储,检索时根据属性在相应的分区进行搜索,以快速得到混合过滤的结果。此方法提高了查询效率,且更加符合实际需求。
具体流程包括:将属性标签字符串作为分区标签,特征向量按分区存储;在检索时,根据过滤条件将字符串与对应分区匹配,查找相似向量。分区标签支持正则表达式匹配,以灵活指定分区。
为实现此功能,首先准备特征向量数据,提取自ANN_SIFT1B数据集中的一亿条记录。随机生成性别、获取时间、是否戴眼镜等属性标签,并将它们组合为分区标签。创建包含十个分区的Milvus表,每个分区对应一个属性组合,彩色字源码数据按分区导入。
在进行检索时,向Milvus传入查询向量,设置TOP_K值以获取最相似的前N个结果。检索时,根据给定的属性条件在指定的分区中进行查找。在指定分区后,使用欧氏距离计算向量相似度,返回匹配的向量ID。
对于一亿条数据的混合查询,Milvus能在秒级返回结果,显著提高了查询效率。与结合PostgreSQL的方案相比,基于分区功能的混合查询更接近实际需求,先筛选属性匹配的向量,再进行相似度检索,最终得到满足条件的高质量结果集。
基于Milvus的分区功能实现特征向量与结构化数据的混合查询,不仅性能优秀,操作简便,维护简单,还提供了一种高效的数据查询解决方案。欢迎加入Milvus社区,获取更多源码、官网信息、Slack社区、CSDN博客等资源。
向量数据库 对比有哪些
向量数据库对比主要包括以下几个方面:开源可用性、CRUD支持、分布式架构、副本支持、可扩展性、性能和持续维护等。以下是对这些方面的详细解释和对比:
首先,开源可用性是一个重要考虑因素。一些向量数据库如Weaviate、Milvus和Qdrant等是开源的,这意味着用户可以自由地访问和使用这些数据库的源代码,并且可以根据需要进行定制和修改。这种开源性为用户提供了更大的灵活性和自主性。
其次,CRUD支持是数据库功能的基础。专用的向量数据库如Milvus和Weaviate通常提供全面的CRUD支持,允许用户轻松地添加、删除、查询和修改向量数据。这是与一些主要支持静态数据的向量库的主要区别之一。
在分布式架构方面,向量数据库的设计需要考虑到数据的分布和并行处理。例如,Qdrant和Milvus等数据库支持分布式架构,这使得它们能够处理大规模的数据集,并提供高可用性和容错性。游戏夺宝源码
副本支持是另一个关键特性,它可以提高数据的可靠性和可用性。一些向量数据库提供副本功能,这意味着数据会在多个位置进行存储,以防止数据丢失并确保在发生故障时能够快速恢复。
可扩展性对于处理不断增长的数据集至关重要。专用的向量数据库如Pinecone、Milvus和Weaviate等通常具有良好的可扩展性,可以根据需要增加或减少资源,以适应数据量的变化。
性能方面,向量数据库需要能够快速执行向量相似性搜索和处理高维度数据。各种向量数据库采用了不同的索引策略和算法来优化性能,如FLAT索引、IVF_FLAT索引和HNSW索引等。这些策略在效率、存储空间占用和搜索准确性之间做出了权衡。
最后,持续维护也是一个重要考虑因素。选择一个有活跃社区和持续维护的向量数据库可以确保用户在使用过程中遇到的问题能够得到及时解决,并且数据库会不断更新和改进以适应新的需求和技术发展。
综上所述,向量数据库的对比涉及多个方面,包括开源可用性、CRUD支持、分布式架构、副本支持、可扩展性、性能和持续维护等。在选择适合的向量数据库时,用户需要根据自己的具体需求和场景来权衡这些因素。
实战 向量数据库选型参考
在实施大型模型的过程中,特别是在应用RAG增强检索生成时,向量数据库的选择至关重要。本文通过实验对比了四个常见的向量数据库:Chroma、Faiss、Weaviate和Pinecore。未来计划在时间和精力允许的情况下,追加Milvus和Qdrant的实验。
实验中选用的模型要求较小,以减少空间占用,便于本地调试。从Huggingface上选择了名为all-MiniLM-L6-v2的模型,其维度为。
HuggingFace上的模型all-MiniLM-L6-v2无法直接下载。可以通过以下两种方式之一下载模型:从摩搭(ModelScope)平台下载,或从HF-Mirror下载。
Chroma向量数据库采用SQLite作为基础,通过乘积量化技术和k-means聚类优化查询和压缩数据,以节约空间和提高查询效率。实验中,使用Python语言将文本块以Embedding向量的形式存入Chroma数据库,并基于查询文本进行相似度搜索,dubbo重试源码找到top K个相似结果。
通过实验发现,SentenceTransformer的Model基于BertModel,分词器使用BertTokenizer。检索器(Retriever)通过invoke()方法进行相关性搜索,默认使用欧拉距离计算相似度。
FAISS是Facebook AI Research的开源数据库。实验场景与Chroma相同,源码也类似。结果显示符合预期,Langchain框架的检索器Retriever对向量数据库的相似度检索默认使用欧拉距离。
Pinecone是云向量数据库,通过apiKey接入。实验中,通过两种方式使用Pinecone向量库:通过Database->Indexes提前创建向量库,或直接在源代码中创建向量库。
Weaviate的文档相对完善,主要用于AI应用开发平台Dify。实验中,注意Weaviate版本需高于v1.,否则无法使用grpc服务。实验场景与之前类似,通过Weaviate的GraphQL实现相关度查询。
调研并深度使用了四种常见的向量数据库:Chroma、Faiss、Pinecone、Weaviate,并对它们进行了多维度对比。
在笔记本电脑上,实现本地知识库和大模型检索增强生成(RAG)
在笔记本电脑上,实现本地知识库和大模型检索增强生成(RAG)的问题,通过引入AnythingLLM,可以轻松解决。
AnythingLLM是用于本地部署基于RAG的大模型应用的开源框架,它采用MIT许可证,不调用外部接口,不发送本地数据,确保用户数据的安全。
它支持在MacOS、Windows和Linux等操作系统上直接下载并安装,初次启动需要几分钟初始化时间。所有上传的文档、向量和数据库都保存在特定的文件夹中,方便查看。
在选择大模型时,AnythingLLM预设了多个模型选项,如LLama2 7B、Mistral 7B、Gemma 2B等,同时也可以直接调用OpenAI、Gemini、Mistral等大模型API服务。如果已安装Ollama,只需输入API接口URL和已下载的模型即可。
嵌入模型方面,AnythingLLM内置了all-Mini-L6-v2模型,无需配置,性能稳定。同时支持OpenAI、LocalAi、Ollama等提供的嵌入模型,如nomic-embed-text,性能优越。使用Ollama时,可选择nomic-embed-text。
向量数据库则默认使用LanceDB,它是一款无服务器向量数据库,支持向量搜索、全文搜索和SQL查询,同时兼容Chroma、Milvus、Pinecone等其他数据库选项。
创建知识库时,AnythingLLM提供上传文档和抓取网页信息的功能。上传Word文档或创建工作区,系统会自动提取信息并保存至向量数据库。我创建了一个名为“David”的工作区,上传了关于AI新范式的三篇文章,系统抓取数据后统一存储。
通过构建知识库,大模型可以针对特定问题提供答案,并引用上传的文档。尽管答案有时不够精确,未来可以进一步优化文本召回和重排等功能。
对于界面定制,AnythingLLM提供了基本选项,如自定义品牌Logo和欢迎语。对于更复杂的定制需求,需要通过修改源代码实现。
部署方式灵活,AnythingLLM支持Docker本地化部署,也适用于企业级应用,支持在私有云或物理服务器上部署。
多用户模式方面,AnythingLLM提供了管理员、管理角色和普通用户的权限管理,确保不同角色的用户在特定范围内操作,适用于企业级应用。
笔记︱几款多模态向量检索引擎:Faiss 、milvus、Proxima、vearch、Jina等
向量化搜索,利用人工智能算法将物理世界中的非结构化数据(如语音、、视频、文本等)抽象为多维向量,以便进行高效检索。这些向量在数学空间中代表实体及其关系,通过将非结构化数据转换为向量(Embedding)并检索生成的向量,可以找到相应的实体,广泛应用于人脸识别、推荐系统、搜索、语音处理、自然语言处理和文件搜索等领域。随着AI技术的广泛应用和数据规模的增长,向量检索成为AI技术链路中不可或缺的部分,补充并强化了传统搜索技术,并具备多模态搜索能力。
向量检索技术在不同场景下发挥着关键作用,覆盖了包括人脸识别、基因比对、智能客服等常见领域,以及图像视频检索、智能问答机器人、音频数据处理等新兴应用。以深度学习模型为基础,向量检索技术能够支持文本、图像、语音、视频、源代码等各类内容的高性能搜索与分析。
Milvus是一款高性能的开源特征向量相似度搜索引擎,提供方便、实用、扩展性好、稳定高效的向量数据处理能力,支持GPU加速,实现对海量数据的近实时搜索,同时也支持标量数据的过滤功能。支持集群分片,适用于大规模数据存储和搜索服务。
Faiss库由Facebook开发,专为稠密向量匹配设计,支持C++和Python调用,具备多种向量检索方式,包括内积和欧氏距离等。它支持精确检索和模糊搜索,广泛应用于人脸比对、指纹比对、基因比对等场景。
京东开源的vearch是一个分布式向量搜索系统,能够存储和计算海量特征向量,用于图像、语音、文本等机器学习领域。vearch基于Facebook AI研究机构的Faiss实现,提供了灵活易用的RESTful API,支持管理和查询表结构及数据。
阿里达摩院的Proxima和蚂蚁金服的ZSearch也提供了高性能向量检索能力,Proxima集成在阿里巴巴和蚂蚁集团的多个业务中,如淘宝搜索、推荐、人脸支付、视频搜索等。ZSearch则在ElasticSearch基础上构建,为用户提供了通用搜索平台。
这些向量检索引擎通过不同算法和技术优化,满足了不同场景下的需求,如标签+向量的联合检索、语音/图像/视频检索、文本检索等,为AI领域提供高效、准确的搜索能力。通过深度学习和向量计算,它们能够实现全内容搜索,包括文本、、语音、视频等多模态数据,显著提升了信息检索的效率和准确性。
深入 Dify 源码,定位知识库检索的大模型调用异常
深入分析Dify源码:大模型调用异常定位
在使用Dify服务与Xinference的THUDM/glm-4-9b-chat模型部署时,遇到了知识库检索节点执行时报错大模型GPT3.5不存在的问题。异常出乎意料,因为没有额外信息可供进一步定位。 通过源码和服务API调用链路的分析,我们发现问题的关键在于知识库检索的实现。该功能在api/core/rag/datasource/retrieval_service.py中,其中混合检索由向量检索和全文检索组成。我们关注了关键词检索、向量检索和全文检索这三个基础检索方式:关键词检索:仅使用jieba进行关键词提取,无大模型介入。
向量检索:通过向量库直接搜索,如Milvus,无大模型调用。
全文检索:使用BM,大部分向量库不支持,实际操作中返回空列表。
问题出现在知识库检索节点的多知识库召回判断中,N选1召回模式会调用大模型以决定知识库。在配置环节,前端HTTP请求显示配置错误,使用了不存在的GPT3.5模型。 经测试,手工创建的知识库检索节点使用了正确的glm-4-9b-chat模型,问题出在默认模板的配置上,即N选1召回模式默认选择了GPT3.5。本地部署时,如果没有配置相应模型,会导致错误出现。 总结来说,解决方法是修改默认模板,将知识库检索的默认模式改为多路召回,这样可以避免新手在本地部署时遇到困扰。建议Dify官方在模板中改进这一设置,以简化用户部署流程。向量数据库对比有哪些
向量数据库对比时,可以关注几个关键方面。首先是开源可用性,一些如Milvus、Weaviate等数据库提供开源版本,而Pinecone等则可能是封闭源代码的。其次是性能和可扩展性,Milvus以其在向量索引和查询方面的出色能力著称,支持大规模数据的高效处理;Weaviate则以其高性能和可扩展性赢得用户青睐。此外,数据库对CRUD(增删查改)操作的支持、分布式架构、副本支持、持续维护等因素也是对比的重要维度。
在具体功能上,Milvus支持多种编程语言,提供GPU加速,适用于复杂的相似性搜索和分析场景;Weaviate则能灵活管理多种数据类型,支持向量搜索和关键字搜索,非常适合需要综合搜索能力的应用。而像Chroma这样的数据库则可能更专注于特定领域,如音频数据的处理。
综上所述,向量数据库的选择应根据具体的应用场景和需求进行综合考虑,选择最适合自己的数据库产品。
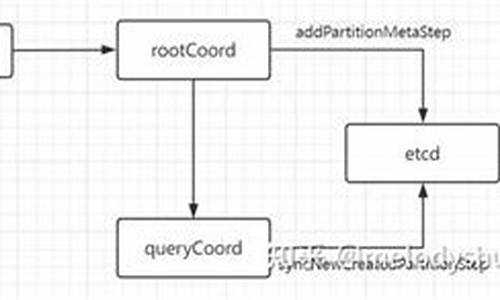
CreateCollection API执行流程_milvus源码解析
在分析milvus源码中的CreateCollection API执行流程时,我们需要详细拆解从客户端请求到数据最终存储在etcd的过程。在milvus版本v2.3.2中,CreateCollection API的执行流程大致分为以下几个关键步骤:
首先,客户端SDK接收用户创建集合(collection)的请求,并将此请求封装为createCollectionTask,随后将其放入ddQueue队列。
随后,此任务在proxy内依次执行PreExecute、Execute和PostExecute三个方法。PreExecute阶段进行参数校验等预处理工作,Execute阶段则是真正执行逻辑,而PostExecute阶段完成执行后的清理工作,通常不做任何操作并返回nil。
在Execute方法中,proxy调用rootCoord的CreateCollection接口,此接口进一步封装请求为rootcoord里的createCollectionTask。
接下来,rootCoord的CreateCollection接口执行CreateCollectionTask的Prepare、Execute和NotifyDone方法。核心操作在Execute阶段,其中涉及到多个步骤,包括expireCacheStep、addCollectionMetaStep、watchChannelsStep、changeCollectionStateStep等。在这些步骤中,重点是addCollectionMetaStep,负责etcd元数据的操作。
在addCollectionMetaStep的Execute方法中,s.core.meta.AddCollection方法被调用。此方法在etcd中创建了多个与集合相关的key-value对,这些key值按照特定规则构建,反映了集合、分区和字段之间的关系。
具体而言,集合信息通过key `root-coord/database/collection-info/1/` 存储在etcd中,value为protobuf序列化的etcdpb.CollectionInfo,这表示集合由ID、DbId、schema等组成,schema中不记录字段、分区ID或名称等信息。etcd以二进制形式存储这些数据。
分区信息通过类似 `root-coord/partitions//` 的路径存储,value为etcdpb.PartitionInfo,同样采用protobuf序列化后存储在etcd中。此信息包括partitionID、partitionName、collectionId等。
字段信息通过 `root-coord/fields//` 的路径存储,value为schemapb.FieldSchema,包含字段ID、名称、描述、数据类型等信息。
在执行完毕后,将所有key-value对批量写入etcd,最终完成集合的创建。
总结而言,CreateCollection API的执行流程涉及多个组件协作,从客户端请求开始,经过proxy和rootCoord的处理,最终在etcd中存储集合、分区和字段的元数据,实现了集合的创建。整个流程中,etcd作为关键的数据存储层,提供了持久化和高可用性保障。



2025-01-20 00:05
2025-01-20 00:03
2025-01-19 23:34
2025-01-19 22:12
2025-01-19 21:59
