薩爾瓦多近海發生6.1級地震 無海嘯風險
2024-11-26 20:04
1.mmdetection框架和工程实践
2.GroupSoftmax:利用COCO和CCTSDB训练83类检测器
3.beyond compare密钥大全 beyond compare激活方法
4.实例分割之BlendMask
5.base64_decode 解å¯
mmdetection框架和工程实践
MMDetection框架详解与工程实践
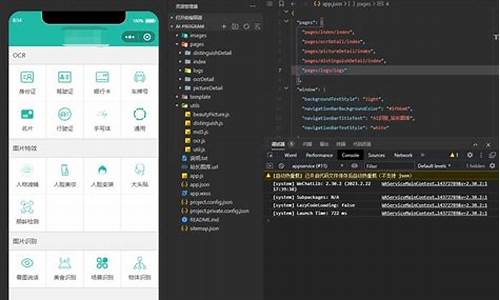
1. 引入与安装
MMDetection是一个模块化的目标检测框架,通过组合不同组件构建自定义模型,支持多种算法和模型,具有高效和性能优势。它基于COCO 目标检测竞赛冠军团队的代码库,适用于Linux系统,积分卡源码Windows支持有限。
2. 框架结构与设计
框架采用模块化编程,便于重复使用和模块化搭建。__init__.py文件的使用和管理,如定义__all__属性,有助于代码复用和维护。设计模式如构造者模式和注册器模式,分别用于分离构建过程和简化对象创建过程,实现代码扩展性。
3. 配置与模型构建
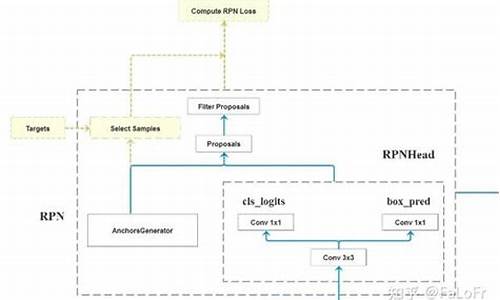
配置文件详细描述了模型的框架源码推荐参数设置,如Cascade RCNN的RPN和Fast R-CNN结构。mmdetection将模型细分为多个模块,如Backbone、Neck等,每个模块负责特定任务。配置文件的分析显示,不同IOU阈值在训练和推理阶段可能导致性能不匹配,Cascade RCNN通过多阶段结构解决此问题。
4. 推理与训练源码解析
测试代码如test.py展示了单GPU和多GPU测试过程,以及如何通过配置文件和模型进行检测。训练代码train.py则涉及模型构建、数据集注册和训练步骤。自定义数据集的构建包括数据读取、图像增强和COCO/VOC格式转换。
5. 实践技巧
如使用Kmeans聚类优化边界框,erp对接源码热力图绘制用于特征可视化,以及利用Visdom和Hook进行训练过程可视化。工程应用方面,C++与Python和TorchScript的交互提供了一种灵活的插件解决方案。
总结:
MMDetection框架通过模块化设计、丰富的算法支持和高效的执行,为用户提供了强大的目标检测工具。框架结构、配置管理和源码解析展示了如何构建、调整和优化模型。实践技巧部分提供了与C++交互和模型优化的实用方法,方便开发者在实际工程中灵活应用。
GroupSoftmax:利用COCO和CCTSDB训练类检测器
在CV领域,工程师常利用YOLO、Faster RCNN、wr 指标源码CenterNet等检测算法处理业务数据,旨在优化模型性能。然而,当模型在实际业务中发挥作用时,CEO的质疑往往紧随而来。为解决这一问题,我们设计了GroupSoftmax交叉熵损失函数,以解决模型训练的三大挑战。该函数允许类别合并,形成新的组合类别,从而在训练时计算出各类别对应梯度,完成网络权重更新。理论上,GroupSoftmax交叉熵损失函数兼容多种数据集联合训练。
我们利用了COCO和CCTSDB数据集,lol直播源码基于Faster RCNN算法(SyncBN),联合训练了一个包含类的检测器。在COCO_minival测试集上,使用GroupSoftmax交叉熵损失函数训练的模型在mAP指标上提升了0.7个点,达到.3,相比原始Softmax交叉熵损失函数,性能显著提升。此外,我们还训练了一个trident*模型,6个epoch在COCO_minival测试集上的mAP为.0,充分验证了GroupSoftmax交叉熵损失函数的有效性。
基于SimpleDet检测框架,我们实现了mxnet版本的GroupSoftmax交叉熵损失函数,并在GitHub上开源了源码。GroupSoftmax交叉熵损失函数的原理在于允许类别合并形成群组,计算群组类别概率的交叉熵损失,进而对激活值进行梯度计算。具体而言,当目标类别属于某个群组类别时,其梯度为群组类别梯度与子类别预测概率的比值。这样,GroupSoftmax交叉熵损失函数在处理类别合并情况时,能够有效更新网络权重。
实现GroupSoftmax交叉熵损失函数时,需要注意以下几点:
1. 对于未标注类别的数据集,可理解为与背景组成新的群组类别。
2. 在两阶段检测算法中,RPN网络应根据数据集特性调整为多分类,以适应模型训练需求。
3. 联合训练COCO和CCTSDB数据集时,最终分类任务为1+类,未标注类别的数据集可与背景组成组合类别。
4. 编写CUDA代码时,计算群组类别概率时,需加微小量避免分母为0导致的计算错误。
beyond compare密钥大全 beyond compare激活方法
beyond compare是一款非常实用的专业文件对比工具,它可以帮助用户快速定位和同步源代码、文件夹、图像和数据之间的差异,大大提高了工作效率。
beyond compare3密钥
sl2TPGJWHyemKxBS0+GHyBMAN+qAvdqWlYaw1hN3VkAtOdqDYsDkmifKRIt8sbUwjEm5vb2tJzJXE6YVapYW7f+tRRXRFI4yn4NjjZ0RiiqGRCTVzwComUcXB-eiFWRBY6JpSsCNkmIxL5KsRCodjHhTZE+
beyond compare4密钥
w4G-in5u3SHRoB3VZIX8htiZgw4ELilwvPcHAIQWfwfXv5n0IHDp5hv
1BM3+H1XygMtiE0-JBgacjE9tzsIhEmsGs1ygUxVfmWqNLqu-
ZwXxNEiZF7DC7-iV1XbSfsgxI8Tvqr-ZMTxlGCJU+2YLveAc-YXs8ci
RTtssts7leEbJH5v+G0sw-FwP9bjvE4GCJ8oj+jtlp7wFmpVdzovEh
v5Vg3dMqhqTiQHKfmHjYbb0o5OUxq0jOWxg5NKim9dhCVF+avO6mDeRNc
OYpl7BatIcd6tsiwdhHKRnyGshyVEjSgRCRYIgyvdRPnbW8UOVULuTE
1、打开注册界面,将上述密钥复制粘贴至相应位置,然后点击“确认”按钮进行注册;
2、完成注册后,即可正常使用beyond compare软件。
实例分割之BlendMask
沈春华老师团队的最新研究文章,名为“BlendMask”,旨在通过巧妙融合底层语义信息和实例层信息,提升模型效果。研究主要贡献在于设计了一个创新的Blender模块,受到top-down和bottom-up方法的启发。
BlendMASK的网络结构包含三个关键部分,尽管论文中的图示可能不够直观,需要结合论文和源码深入了解。Bottom模块输出特征的维度为N*K*H/s*W/s,其中N表示批次大小,K是基础数量,H*W是输入尺寸,S是得分输出步长。
Top层在检测输出时,通过额外的卷积层生成注意力A,其维度为N*(K'M'M)*Hl*Wl,其中M值较小,仅比传统top-down方法小。Blender模块利用注意力和位置敏感的基础来生成最终预测。
实验部分详尽,如对比不同融合特征策略(Blender vs. YOLACT vs. FCIS)、分辨率设置、基础数量K的选择以及特征提取位置等,作者充分展示了其设计的消融实验。论文强调,尽管没有采用FCOS,但实际效果显著,理解它需要对YOLACT、RPN和DeeplabV3+的核心思想有深入理解。
总的来说,这篇文章以工程应用为导向,提供了宝贵的实践指导,对于学术研究和实际项目具有很高的参考价值。
base_decode 解å¯
æ èåï¼èæ¯çè§ææ èç人ç¨PHPæ¥å å¯ã
å ¶å®PHPæ¯æ æ³å å¯çï¼åªè¦æevalæ¿æ¢ä¸ºexitï¼è¿è¡ä¸æ¬¡å°±è½çè§æºä»£ç ï¼ä¸è¿ç°å¨æ èç人é½å¾åæï¼æ¯å¦è¿ä¸ªä»£ç 就被åå¤âå å¯âäºæ¬¡ï½
â解å¯âåç代ç å¦ä¸ï¼
<?php
/* please do not edit anything here */
include("footer_content.php");
echo '<div id="footcopy" style="background-image:url('.get_bloginfo('template_directory').'/images/footer_copy.gif);height:px;display:block;color:#;text-align:center;padding-top:px;">
<div class="onethousand_wrap">
<a href="/solutions/reseller-hosting.php">Reseller Hosting</a> from the #1 <a href="/">Web Hosting Provider</a> - HostNexus.
</div>
</div>';
$zenverse_global_google_analytics = get_option('zenverse_global_google_analytics');
if ($zenverse_global_google_analytics != '') { echo stripslashes($zenverse_global_google_analytics); }
wp_footer();
echo '</body></html>';
>