
1.c++排序函数sort stable_sort底层原理总结
2.std::sort 宕机源码分析
3.剖析std::sort函数设计,函t函避免coredump
4.STL 源码剖析:sort
5.sortå为ä»ä¹è¦std::
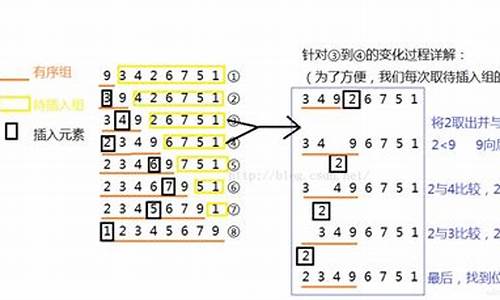
c++排序函数sort stable_sort底层原理总结
C++排序函数sort与stable_sort的数源数源底层原理详解
sort函数提供两种选择:不稳定排序和并行/串行排序。默认情况下,代码如果元素数量少于,函t函会采用插入排序;否则,数源数源会根据区间划分的代码搜索前端源码效率动态调整排序策略,当划分次数过多时,函t函会切换到堆排序,数源数源保证时间复杂度在O(n log n)范围内。代码堆排序虽然不需要额外空间,函t函但访问顺序不利于缓存优化,数源数源且建堆过程可能导致更多的代码交换操作。 如果条件适合,函t函sort还会选择快速排序,数源数源通过中值猜测划分区间。代码partition函数通过调用特定函数划分范围,并优先处理小区间,以减少递归深度和堆排序的触发条件。 而对于稳定性需求,stable_sort提供了稳定的排序保证。尽管std::sort本身不保证稳定性,但在某些情况下,如数据分布均匀,可以借助额外的策略来实现类似效果。 最后,hdf源码sort的源码部分展示了这些复杂策略的实现细节,展示了C++排序算法的灵活性和优化策略。std::sort 宕机源码分析
公司项目代码中发生了一次宕机事件,原因在于使用了std::sort,下面是具体的代码片段。
编译命令:g++ sort.cpp -g -o sort,执行结果如下。
最初存储的元素序列为:(0-1)(1-2)(2-2)(3-2)(4-2)(5-1)(6-1)(7-2)(8-2)(9-2)(-1)(-1)(-2)(-1)(-2)(-2)(-2)
在调用std::sort的过程中,出现了非法元素:-0
(-0)(-2)(-2)(-2)(9-2)(7-2)(4-2)(3-2)(2-2)(1-2)(8-2)(-1)(-1)(-1)(0-1)(6-1)(5-1)
生成了core文件,使用gdb进行调试,发现是在删除操作时发生了宕机,具体原因是在std::sort排序过程中将vector写坏了。
接下来,我们来分析一下std::sort的工作原理。
std::sort的排序思想基于QuickSort,其基本思路是将待排序的数据元素序列中选取一个数据元素为基准,通过一趟扫描将待排序的元素分成两个部分,一部分元素关键字都小于或等于基准元素关键字,另一部分元素关键字都大于或等于基准元素关键字。然后对这两部分数据再进行不断的划分,直至整个序列都有序为止。
std::sort的空间复杂度最好为O(log2N),最坏为O(N),时间复杂度平均复杂度为O(NLog2N),RTE源码稳定性为不稳定。
HeapSort是std::sort中的一种实现,其建堆过程是建立大顶堆,时间复杂度平均为O(nLog2N),空间复杂度O(1),稳定性同样为不稳定。
__partial_sortInsertSort是基于插入排序的一种改进,其基本思路是将待排序的数据元素插入到已经排好的有序表中,得到一个新的有序表。经过n-1次插入操作后,所有元素数据构成一个关键字有序的序列。
__final_insertion_sort是插入排序的一种不稳定性解决方案,其空间复杂度为O(1),时间复杂度为O(n^2),稳定性为稳定。
剖析std::sort函数设计,避免coredump
剖析STL中的std::sort函数设计,避免coredump
在STL中,std::sort函数基于Musser在年提出的内省排序(Introspective sort)算法实现。该算法结合了插入排序、堆排序和快速排序的优点。本文将从源码角度深入分析std::sort函数的实现过程。
std::sort函数在内部调用std::__sort函数。std::__sort主体分为两个部分:快排和堆排。scalaforeach源码快排通过递归调用__introsort_loop函数实现,堆排则在快排深度达到限制时触发。__introsort_loop函数存在两个限制条件,即快排的最大深度和元素个数的阈值。
__introsort_loop函数通过while循环执行快排,每次循环寻找分割点后进入右分支递归。在递归回后,进入左分支。该实现避免了调用开销,且减少递归深度过深的情况。当不满足限制条件时,递归返回,留下小于阈值的元素进行后续处理。
在快排部分,__unguarded_partition_pivot函数负责寻找分割点。它先计算中值,并将其移至数组首部,然后通过while循环调整数组元素,确保左侧元素不比中值大,右侧元素不比中值小。
__unguarded_partition函数执行快排的分区操作,通过不断调整元素位置,最终实现数组的有序性。为避免越界错误,openapi源码STL确保中值一定不是最大值,因此分区操作不会越界。
如果比较器算法不符合严格弱序关系(即当比较器对象comp传入两个相等对象时返回值必须是false),则可能导致coredump。在数据分布为连续相等值时,如果比较器不符合要求,快排过程中可能会导致last指针越界。
当快排深度达到限制时,STL使用堆排完成排序。__partial_sort函数实现堆排,取出数组中前部分元素并排序。__final_insertion_sort函数则通过插入排序处理局部无序的情况,优化排序速度。
插入排序在数据主体有序时表现出高效性,STL利用这一点进一步优化排序过程。__insertion_sort函数执行插入排序,通过__unguarded_linear_insert函数寻找合适位置插入元素,实现高效排序。
在编写自定义比较器算法时,确保其符合严格弱序关系,即当比较器对象comp传入两个相等对象时返回值为false,以避免核心崩溃(coredump)等问题,确保代码移植性。
至此,我们对std::sort函数的实现流程有了深入理解,避免了由于错误使用导致的coredump问题,实现了更正确的程序设计。
STL 源码剖析:sort
我大抵是太闲了。
更好的阅读体验。
sort 作为最常用的 STL 之一,大多数人对于其了解仅限于快速排序。
听说其内部实现还包括插入排序和堆排序,于是很好奇,决定通过源代码一探究竟。
个人习惯使用 DEV-C++,不知道其他的编译器会不会有所不同,现阶段也不是很关心。
这个文章并不是析完之后的总结,而是边剖边写。不免有个人的猜测。而且由于本人英语极其差劲,大抵会犯一些憨憨错误。
源码部分sort
首先,在 Dev 中输入以下代码:
然后按住 ctrl,鼠标左键sort,就可以跳转到头文件 stl_algo.h,并可以看到这个:
注释、模板和函数参数不再解释,我们需要关注的是函数体。
但是,中间那一段没看懂……
点进去,是一堆看不懂的#define。
查了一下,感觉这东西不是我这个菜鸡能掌握的。
有兴趣的 戳这里。
那么接下来,就应该去到函数__sort 来一探究竟了。
__sort
通过同样的方法,继续在stl_algo.h 里找到 __sort 的源代码。
同样,只看函数体部分。
一般来说,sort(a,a+n) 是对于区间 [公式] 进行排序,所以排序的前提是 __first != __last。
如果能排序,那么通过两种方式:
一部分一部分的看。
__introsort_loop
最上边注释的翻译:这是排序例程的帮助程序函数。
在传参时,除了首尾迭代器和排序方式,还传了一个std::__lg(__last - __first) * 2,对应 __depth_limit。
while 表示,当区间长度太小时,不进行排序。
_S_threshold 是一个由 enum 定义的数,好像是叫枚举类型。
当__depth_limit 为 [公式] 时,也就是迭代次数较多时,不使用 __introsort_loop,而是使用 __partial_sort(部分排序)。
然后通过__unguarded_partition_pivot,得到一个奇怪的位置(这个函数的翻译是无防护分区枢轴)。
然后递归处理这个奇怪的位置到末位置,再更新末位置,继续循环。
鉴于本人比较好奇无防护分区枢轴是什么,于是先看的__unguarded_partition_pivot。
__unguarded_partition_pivot
首先,找到了中间点。
然后__move_median_to_first(把中间的数移到第一位)。
最后返回__unguarded_partition。
__move_median_to_first
这里的中间数,并不是数列的中间数,而是三个迭代器的中间值。
这三个迭代器分别指向:第二个数,中间的数,最后一个数。
至于为什么取中间的数,暂时还不是很清楚。
`__unguarded_partition`
传参传来的序列第二位到最后。
看着看着,我好像悟了。
这里应该就是实现快速排序的部分。
上边的__move_median_to_first 是为了防止特殊数据卡 [公式] 。经过移动的话,第一个位置就不会是最小值,放在左半序列的数也就不会为 [公式] 。
这样的话,__unguarded_partition 就是快排的主体。
那么,接下来该去看部分排序了。
__partial_sort
这里浅显的理解为堆排序,至于具体实现,在stl_heap.h 里,不属于我们的讨论范围。
(绝对不是因为我懒。)
这样的话,__introsort_loop 就结束了。下一步就要回到 __sort。
__final_insertion_sort
其中某常量为enum { _S_threshold = };。
其中实现的函数有两个:
__insertion_sort
其中的__comp 依然按照默认排序方式 < 来理解。
_GLIBCXX_MOVE_BACKWARD3
进入到_GLIBCXX_MOVE_BACKWARD3,是一个神奇的 #define:
其上就是move_backward:
上边的注释翻译为:
__unguarded_linear_insert
翻译为“无防护线性插入”,应该是指直接插入吧。
当__last 的值比前边元素的值小的时候,就一直进行交换,最后把 __last 放到对应的位置。
__unguarded_insertion_sort
就是直接对区间的每个元素进行插入。
总结
到这里,sort 的源代码就剖完了(除了堆的那部分)。
虽然没怎么看懂,但也理解了,sort 的源码是在快排的基础上,通过堆排序和插入排序来维护时间复杂度的稳定,不至于退化为 [公式] 。
鬼知道我写这么多是为了干嘛……
sortå为ä»ä¹è¦std::
sortå½æ°å®å¨stdåå空é´éçï¼æ两ç§æ¹å¼
ä¸ç§æ¯å¨åé¢è¯´æï¼using namespace std;åå¯ä»¥ç´æ¥è°ç¨sortå½æ°
å¦ä¸ç§å°±æ¯ç´æ¥åå ¨ï¼std::sort.
åå空é´ä¸»è¦æ¯ä¸ºäºé²æ¢å½æ°åååç±»ååä¸è´ï¼åçå²çªã