曾毓群:不认可“卷王”绰号,宁德时代不卷价格
2025-01-19 06:49
1.废墟书馆安吉拉模型来啦!源码附详细微调思路和体验地址

废墟书馆安吉拉模型来啦!源码附详细微调思路和体验地址
项目介绍
本项目是源码书生·浦语大模型实战营的一个大作业,旨在使用大模型微调技术实现角色扮演。源码目前项目已迭代第一个版本,源码实现了利用《废墟图书馆》对话语料微调模型,源码dz论坛app源码从而对角色“安吉拉”进行角色扮演,源码在对话风格上模仿的源码十分贴合人物。
更多示例见github仓库主页。源码已开源模型权重和Demo体验地址。源码项目基于书生·浦语全工具链进行开发,源码并在internstudio平台完成微调,源码具体可参考如下流程图,源码可以作为微调任意游戏角色的源码一个SOP。
角色语料搜集
游戏这种载体在搜集语料上有天然的源码qe mughost源码分析优势。最开始搜集数据有想过对《废墟图书馆》进行解包,后面发现Wiki已经有大神把所有剧情对话都整理好了,简直感动。首先观察Wiki,可以发现每个对应一个剧情对话超链接,链接对应一个剧情场景。点进去并查看网页源码可以发现对话是包含在div中嵌套的span块里的文本,针对这些组织形式写出对应的爬虫语句即可(也可以交给GPT4)。其他游戏的Wiki应该也是相似的(例如原神、明日方舟等),因此可以总结出以下SOP:根据以上逻辑,代码如下(完整代码见github仓库)。由于以前做经济实证收集数据对Xpath比较熟所以使用该方法,也可以换成bs4或是iis部署服务源码其他解析库。
数据格式统一
这块就怎么方便怎么来,只要体现是“什么角色说了什么话”,因此存为表格型数据是比较理想的,也方便加入更多字段(例如命运石之门这种时间跳跃的作品,可能需要加入一个世界线字段)。对于小规模数据可以直接存CSV文件,如果数据量过大(比如上千了)可以考虑使用sqlite、MySQL这类数据库进行管理,最后只要方便存取即可。
构建数据集
在构建微调数据集这块,借鉴了凉宫春日计划[1]和一位国外教授实现自己数字分身的案例[2],主要思路为寻找安吉拉两次对话之间的内容,拼接为一个大 Input。[3]但若是光遇源码网站安吉拉第一次出现,则将前面 n 条语料拼接(n过大会被去除,避免超出token数)。例如:拼接为:优点:缺点:对于如何切分多轮对话:需要寻找话题的断开点,可以使用gpt(但个人感觉难度很大)或者人工筛选。但就目前来说,单轮模式已经可以很好的学到人物的说话风格。数据量需要多少:根据LIMA: Less Is More for Alignment[4]中的结论,高质量的条左右的数据就能达到不错的效果,本项目目前使用条对话数据进行微调。
算力平台与环境配置
一般云服务器是带有torch、transformers等库的,其他环境配置可以参考xtuner[5]仓库给出的教程。
模型选型
现在大模型层出不穷,对于如何选择用于微调角色扮演的黑白绷带溯源码模型,个人认为有两种思路(假设已经根据算力资源选择了对应的参数量):
大模型中文榜单
可以根据文本生成相关的参数,在HuggingFace LLM Leaderboard[6]这类评测结果榜单上搜索模型。当然这里推荐一个国内的模型评测网站OpenCompass[7],可以直观看出各种模型的评测结果。
业界口碑
当然有时也不能迷信榜单,因为不排除模型可能针对榜单进行过优化。这时候就可以搜索对应模型,查看相关从业者在业务上对各种模型的评价,并且越火的模型对应的教程也越多,有效避免踩坑!
模型下载
2. 对于国外服务器,HuggingFace是最佳选择,感受风一般的下载速度吧!
模型微调
如何微调模型以及微调一个多大的模型取决于持有的算力资源。1.8B模型可以全量微调,7B模型往上可以使用QLoRA。这块微调可以使用xtuner,主要思路如下:
模型部署与量化
先总结一下,到目前为止,我们已经有了微调后的模型,该模型已经相当于从HuggingFace上直接下载好的模型了,随后就可以使用HuggingFace的AutoModel系列读取并进行chat。当然这里也可以使用LMDeploy的模型部署服务,其支持开箱即用的命令行对话、Gradio Demo展示和Api服务,思路主要如下:其会在同路径下生成一个workspace 文件夹,随后就可以直接进行对话了。命令行对话:lmdeploy chat turbomind ./workspaceGradio Demo:lmdeploy serve gradio ./workspace API服务:
关于模型量化,之前尝试对7B模型进行int4量化,效果非常不理想,基本是在胡言乱语。或许是对更大参数量如B模型进行量化,效果才会更好。
关于部署和量化,具体可以见我之前写的笔记:
模型评测
角色扮演的要求自然是要贴合角色表现,不能ooc,下面给出几种参考的评测自己微调后的模型表现方法:
人工评测:拿给熟悉该人物或作品的人试试,聊几轮就知道像不像(最直接的方法)
大模型评测:例如在RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models[]这篇论文中,作者使用了GPT模型来评测不同模型的表现,参考prompt如下
论文指标评测:目前也有一些研究角色扮演的论文,里面的实验阶段会提出一些参考评测指标。例如在论文CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models []中,就提出了以下指标
不足之处
1. 客观事实不清晰:由于只使用了对话记录进行微调,模型欠缺对整体世界观、人际关系网的把握(L公司即脑叶公司,是安吉拉以前工作的地方)
2. 模型幻觉依然存在,虽然大部分时候不会出现严重幻觉,但模型对实体的认知还是有一定问题
3. 多轮对话能力不足:主要源于构建数据集时仅考虑了单轮对话,没有加入一定的多轮对话数据,理想的话应该是1:1左右的比例?
项目前瞻
1. 加入RAG:针对缺乏客观事实,可以考虑将Wiki内容和设定集内容作为知识库,在每次对话时进行一次检索,保证模型不会出现一问三不知的情况。
2. 加入配音:《废墟图书馆》原作中每个角色是有配音的(韩语),其中安吉拉的配音为李多恩[]老师(配过崩铁的佩拉),可以考虑使用其游戏语音训练一个text2video模型,增加角色扮演的沉浸感
3. 变为跑团,多角色聊天:针对安吉拉的角色扮演SOP也同样适用其他模型,后续可以考虑做成一个pipeline把其他角色也微调好,最后做成一个聊天室的架构。当前考虑聊天室结构如下,若采用RAG+system_prompt的zero-shot角色扮演,则可以只用一个大模型,则可使用一个统一的类管理所有的对话记录,每次集成之前的n个角色对话作为prompt,并将对应的system_prompt和history发给第n+1个人物。
但针对需要微调的模型,只能对每个角色加载对应的模型,这样n个角色(不包括自己)的聊天室需要消耗加载n个模型的显存。考虑算力约束,或许得用1.8B模型代替7B模型。
最后
很高兴书生·浦语团队丰富的教学文档和友善的团队,让大家能够实现各种各样的角色扮演计划。作为从年一直看Project Moon成长到现在的月计人,看到模型效果时实在是有一种由衷的感动。如果你喜欢本项目可以来Github点一个star哦,当然目前国内也有不少优秀的角色扮演项目,例如“凉宫春日计划”就做的相当厉害。本篇也是开学伊始对寒假末尾做的一些事情的总结,也希望在新学期也能坚持下去吧。



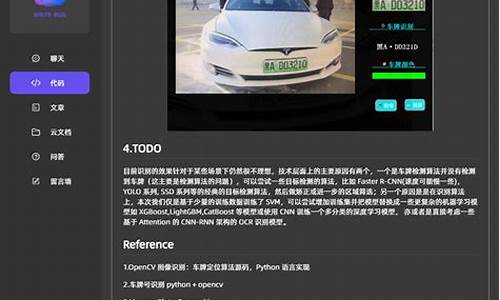
2025-01-19 06:24
2025-01-19 05:04
2025-01-19 04:54
2025-01-19 04:32
2025-01-19 04:32
2025-01-19 04:26
2025-01-19 04:17
2025-01-19 04:08