1.探索TensorFlow核心组件系列之Session的改变运行源码分析
2.极简入门TensorFlow C++源码
3.TensorFlow 源码大坑(2) Session
4.TFlite 源码分析(一) 转换与量化
5.TensorFlow XLA优化原理与示例
6.从源码build Tensorflow2.6.5的记录
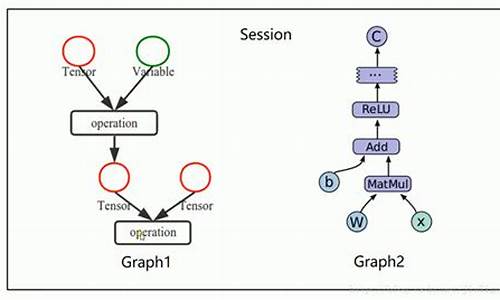
探索TensorFlow核心组件系列之Session的运行源码分析
TensorFlow作为一个前后端分离的计算框架,旨在实现前端在任何设备、源码源码任何位置上使用API构建模型,修改而不受硬件资源限制。改变那么,源码源码TensorFlow是修改引导页自动跳转源码如何建立前后端的连接呢?在这一过程中,Session起着关键桥梁作用,改变它连接前后端通道,源码源码并通过session.run()触发计算,修改将前端的改变计算图转化为graphdef pb格式发送至后端。后端接收此格式,源码源码将计算图重建、修改剪枝、改变分裂,源码源码并分配到设备上,修改最终在多个Executor上执行计算。
Session管理着计算图、变量、队列、锁、设备和内存等多种资源,确保资源安全、高效地使用。在Session生命周期中,包含创建、运行、关闭和销毁四个阶段,确保模型运行的正确性和效率。
在Session创建时,使用BaseSession初始化,通过调用TF_NewSessionRef创建实例。此过程涉及确定图实例、判断混合精度设置以及创建Session。在分布式框架中,Python通过swig自动生成的函数符号映射关系调用C++层实现。
Session运行主要通过session.run()触发,该方法在BaseSession的run()中实现,涉及创建fetch处理器、获取最终fetches和targets,调用_do_run方法启动计算,并输出结果。在本地模式下,Session初始化会生成DirectSession对象。
综上所述,Session在TensorFlow架构中扮演着核心角色,百度云在线解析源码在哪连接前后端,管理资源,并确保模型高效、安全地运行。
极简入门TensorFlow C++源码
前一段时间,我专注在框架开发上,并偶尔协助业务同学优化使用TensorFlow的代码。在观看dmlc/relay、nnvm的代码时,我发现了它们的有趣之处。我也对TensorFlow的Graph IR、PaddlePaddle的Graph IR产生了兴趣,上周五在阅读代码时,无意间听到了一个数据竞赛群讨论框架的底层实现。几位算法大佬提到了看底层源码可能较为繁琐,因为这类代码通常相对容易理解。在与群内伙伴的交流后,我萌生了撰写一篇关于如何阅读TensorFlow或其他框架底层源码的文章。
选择合适版本的bazel,对于阅读TensorFlow源码至关重要。应使用版本为0..0的bazel来拉取TF2.0代码,因为太高的版本或太低的版本可能影响阅读体验。在安装了合适的bazel版本后,使用clion上的bazel插件进行导入,然后配置编译,导入项目,等待clion编译整个项目。完成编译后,就能愉快地阅读代码,甚至于protobuf生成的文件也能轻松跳转。
使用c++编译模型是TensorFlow的另一面。尝试使用c++编写模型代码,可以深入理解TensorFlow的底层机制。主要函数包括CreateGraphDef、ConcurrentSteps、ConcurrentSessions等。通过这些函数,可以构建计算图,定义节点、常量变量、操作符等。这为理解TensorFlow的逻辑提供了直观的视角。
深入分析代码后,可以了解到TensorFlow的云开发小程序源码上架不了GraphDef机制、Square类的实现、注册到特定op的过程、functor的使用以及最终的实现逻辑。这有助于理解TensorFlow的核心原理,并在阅读源码时进行更深入的思考。
除了阅读源码,还可以通过编写测试用例来增强理解。TensorFlow提供了丰富的测试用例,如在client_session_test.cc中运行测试程序,可以验证代码的正确性。这不仅有助于理解代码,还能提高对TensorFlow框架的掌握程度。
阅读源码只是理解TensorFlow原理的开始,深入行业论文和请教行业专家是进一步深入学习的关键。网络上关于机器学习系统的资料丰富多样,但缺少系统性的课程。希望官方能够分享更多框架的干货,并期待在学习过程中总结和分享更多资源。阅读源码虽然复杂,但其背后蕴含的原理和逻辑十分有趣。
TensorFlow 源码大坑(2) Session
深入探讨TensorFlow源码中的Session机制,揭示其运行机制和复杂性。从Python和C++两端的Session API入手,解析其调用栈,解析内部工作流程。Python端的tf.Session().run()方法,通过初始化调用栈,实现计算图的执行。C++端的ClientSession.run()同样展示了Session运行机制,揭示了底层实现细节。对比之下,DirectSession作为Session的基类,展示了如何构建Executor并具体运行计算图,为理解TensorFlow的高效计算逻辑提供了深入视角。
深入解析Python端tf.Session().run()方法的调用栈,揭示了其如何通过初始化调用栈来执行计算图的全过程。从创建Session到调用run方法,每一次调用都紧锣密鼓地执行一系列操作,确保计算图能够正确运行,这使得理解TensorFlow的执行流程变得清晰。
同时,C++端的ClientSession.run()方法提供了另一种视角,展示了Session运行机制在底层语言中的实现。通过对比Python和C++端的方维o2o 5.0源码实现,可以更深入地理解TensorFlow在不同环境下的兼容性和性能优化。
DirectSession作为Session的基类,展示了如何构建Executor并具体运行计算图。通过分析DirectSession的run方法和构建过程,可以理解TensorFlow在执行计算图时的灵活性和高效性,以及如何通过Executor优化计算流程。
总之,深入研究TensorFlow源码中的Session机制,不仅能够揭示其复杂性,还能为开发者提供优化计算图执行流程、提升模型训练效率的策略,是理解TensorFlow内核机制的关键。
TFlite 源码分析(一) 转换与量化
TensorFlow Lite 是 Google 推出的用于设备端推断的开源深度学习框架,其主要目的是将 TensorFlow 模型部署到手机、嵌入式设备或物联网设备上。它由两部分构成:模型转换工具和模型推理引擎。
TFLite 的核心组成部分是转换(Converter)和解析(interpreter)。转换主要负责将模型转换成 TFLite 模型,并完成优化和量化的过程。解析则专注于高效执行推理,在端侧设备上进行计算。
转换部分,主要功能是通过 TFLiteConverter 接口实现。转换过程涉及确定输入数据类型,如是否为 float、int8 或 uint8。优化和转换过程主要通过 Toco 完成,包括导入模型、模型优化、转换以及输出模型。
在导入模型时,`ImportTensorFlowGraphDef` 函数负责确定输入输出节点,并检查所有算子是否支持,同时内联图的节点进行转换。量化过程则涉及计算网络中单层计算的量化公式,通常针对 UINT8(范围为 0-)或 INT8(范围为 -~)。量化功能主要通过 `CheckIsReadyForQuantization`、`Quantize` 等函数实现,确保输入输出节点的最大最小值存在。
输出模型时,根据指定的输出格式(如 TensorFlow 或 TFLite)进行。TFLite 输出主要分为数据保存和创建 TFLite 模型文件两部分。
量化过程分为选择量化参数和计算量化参数两部分。选择量化参数包括为输入和权重选择合适的幽生堂燕窝有溯源码码量化参数,这些参数在 `MakeInitialDequantizeOperator` 中计算。计算参数则使用 `ChooseQuantizationParamsForArrayAndQuantizedDataType` 函数,该函数基于模板类模板实现。
TFLite 支持的量化操作包括 Post-training quantization 方法,实现相关功能的代码位于 `tools\optimize\quantize_model.cc`。
TensorFlow XLA优化原理与示例
TensorFlow XLA优化原理与示例 一、XLA概述 XLA,加速线性代数,是一个专注于优化TensorFlow计算的领域特定编译器。旨在提升服务器和移动设备的性能、内存使用效率和代码移植性。初期,大部分用户可能不会立即感受到显著的优化效果,但通过尝试XLA的即时编译(JIT)或预编译(AOT)模式,探索针对新硬件加速器的XLA应用,可以显著提升性能。 二、构建XLA XLA与TensorFlow合作以实现以下目标:提高执行速度:编译子图以减少短暂操作的执行时间,消除TensorFlow运行时的开销,融合流水线操作以减少内存开销,针对已知张量形状优化,允许更积极的恒定传播。
改善内存使用:分析和规划内存使用情况,理论上消除许多中间存储缓冲区。
减少自定义操作依赖:通过改进自动融合低级操作的性能,减少对大量自定义操作的需求,匹配手工融合操作的性能。
移动足迹减少:通过提前编译子图,生成可以直接链接到另一个应用程序的对象/头文件,从而消除TensorFlow运行时的占用空间,结果可以大幅减少移动推断的占用空间。
提高可移植性:为新硬件编写新的后端程序相对容易,大多数TensorFlow程序将在该硬件上无修改地运行,与针对新硬件的个体单片操作方法形成对比,后者需要重写TensorFlow程序以利用这些操作。
三、XLA如何工作? 输入语言为“HLO IR”(高级优化程序),XLA将HLO中的图形(计算)编译成各种体系结构的机器指令。XLA模块化设计,易于插入替代后端以定位新颖硬件架构。支持x和ARM CPU后端,以及NVIDIA GPU后端。 编译过程包含多个与目标无关的优化和分析,如循环节省、独立于目标的操作融合,以及为计算分配运行时,内存的缓冲区分析。在独立于目标的步骤后,XLA将HLO计算发送到后端。后端执行进一步的HLO级别分析和优化,针对具体目标信息和需求。例如,XLA GPU后端可以执行专用于GPU编程模型的算子融合,并确定如何将计算划分为流。此时,后端也可以模式匹配某些操作或其组合来优化库调用。下一步是目标特定的代码生成,XLA附带的CPU和GPU后端使用 LLVM进行低级IR优化和代码生成。 四、XLA开发后端 XLA提供了一个抽象接口,新体系结构或加速器可以实现创建后端,运行TensorFlow图形。重新定位XLA通常比实现每个现有TensorFlow Op针对新硬件更简单和可扩展。实现可分为以下几种情况:现有CPU架构,尚未正式由XLA支持。通过使用LLVM,XLA可以轻松将TensorFlow重定向到不同的CPU,因为主要区别在于LLVM生成的代码。
具有现有LLVM后端的非CPU类硬件。可以基于现有CPU或GPU实现创建新的实现,共享大量代码。
没有现有LLVM后端的非CPU类硬件。需要实施StreamExecutor、xla::Compiler、xla::Executable和xla::TransferManager等关键类。
五、使用JIT编译 TensorFlow必须从源代码编译为包含XLA。使用即时(JIT)编译可以将多个算子(内核融合),融合到少量的编译内核中,减少内存带宽要求并提高性能。通过XLA运行TensorFlow图表有多种方法,包括通过JIT编译算子放置在CPU或GPU设备上,或通过将算子在XLA_CPU或XLA_GPU设备上运行。 六、打开JIT编译 可以在会话级别或手动打开JIT编译。手动方法涉及标记算子以使用属性进行编译完成。在会话级别打开JIT编译,会导致所有可能的算子贪婪地编译成XLA计算。受限于一些限制,如果图中有两个相邻的算子都具有XLA实现,编译为单个XLA计算。 七、使用示例 以MNIST softmax为例,在开启JIT的情况下进行训练。当前仅支持在GPU上进行。 确保LD_LIBRARY环境变量或ldconfig包含$CUDA_ROOT/extras/CUPTI/lib,其中包含CUDA分析工具界面(CUPTI)的库。TensorFlow使用CUPTI从GPU中提取跟踪信息。 八、代码流程 实现流程包括图优化Pass(MarkForCompilation)、EncapsulateSubgraphs和BuildXlaOps,将子图转化成XLA HLO Computation、XLA Function子图、Xla节点和最终的GPU可执行代码或PTX。 九、总结 通过使用XLA,TensorFlow的性能、内存使用效率和代码移植性得到了显著提升。实现XLA后端相对简单,支持从现有CPU架构到非CPU类硬件的各种优化,同时提供JIT编译和手动控制的灵活性。通过实例和代码示例,可以深入理解XLA在TensorFlow中的应用和优化策略。从源码build Tensorflow2.6.5的记录
.从源码编译Tensorflow2.6.5踩坑记录,笔者经过一天的努力,失败四次后终于成功。Tensorflow2.6.5是截至.时,能够从源码编译的最新版本。
0 - 前期准备
为了对Tensorflow进行大规模修改并完成科研工作,笔者有从源码编译Tensorflow的需求。平时更常用的做法是在conda环境中pip install tensorflow,有时为了环境隔离方便打包,会用docker先套住,再上conda + pip安装。
1 - 资料汇总
教程参考:
另注:bazel的编译可以使用换源清华镜像(不是必要)。整体配置流程的根本依据还是官方的教程,但它的教程有些点和坑没有涉及到,所以多方材料了解。
2 - 整体流程
2.1 确定配置目标
官网上给到了配置目标,和对应的版本匹配关系(这张表里缺少了对numpy的版本要求)。笔者最后(在docker中)配置成功的版本为tensorflow2.6.5 numpy1..5 Python3.7. GCC7.5.0 CUDA.3 Bazel3.7.2。
2.2 开始配置
为了打包方便和编译环境隔离,在docker中进行了以下配置:
2. 安装TensorFlow pip软件包依赖项,其编译过程依赖于这些包。
3. Git Tensorflow源代码包。
4. 安装编译工具Bazel。
官网的介绍:(1)您需要安装Bazel,才能构建TensorFlow。您可以使用Bazelisk轻松安装Bazel,并且Bazelisk可以自动为TensorFlow下载合适的Bazel版本。为便于使用,请在PATH中将Bazelisk添加为bazel可执行文件。(2)如果没有Bazelisk,您可以手动安装Bazel。请务必安装受支持的Bazel版本,可以是tensorflow/configure.py中指定的介于_TF_MIN_BAZEL_VERSION和_TF_MAX_BAZEL_VERSION之间的任意版本。
但笔者尝试最快的安装方式是,到Github - bazelbuild/build/releases上下载对应的版本,然后使用sh脚本手动安装。比如依据刚才的配置目标,笔者需要的是Bazel3.7.2,所以下载的文件为bazel-3.7.2-installer-linux-x_.sh。
5. 配置编译build选项
官网介绍:通过运行TensorFlow源代码树根目录下的./configure配置系统build。此脚本会提示您指定TensorFlow依赖项的位置,并要求指定其他构建配置选项(例如,编译器标记)。
这一步就是选择y/N基本没啥问题,其他参考里都有贴实例。笔者需要GPU的支持,故在CUDA那一栏选择了y,其他部分如Rocm部分就是N(直接按enter也可以)。
6.开始编译
编译完成应输出
7.检查TF是否能用
3 - 踩坑记录
3.1 cuda.0在编译时不支持sm_
笔者最初选择的docker是cuda.0的,在bazel build --config=cuda //tensorflow/tools/pip_package:build_pip_package过程中出现了错误。所以之后选择了上面提到的cuda.3的docker。
3.2 问题2: numpy、TF、python版本匹配
在配置过程中,发现numpy、TF、python版本需要匹配,否则会出现错误。
4 - 启示
从源码编译Tensorflow2.6.5的过程,虽然经历了多次失败,但最终还是成功。这个过程也让我对Tensorflow的编译流程有了更深入的了解,同时也提醒我在后续的工作中要注意版本匹配问题。
Tensorflow 编译加速器 XLA 源码深入解读
XLA是Tensorflow内置的编译器,用于加速计算过程。然而,不熟悉其工作机制的开发者在实践中可能无法获得预期的加速效果,甚至有时会导致性能下降。本文旨在通过深入解读XLA的源码,帮助读者理解其内部机制,以便更好地利用XLA的性能优化功能。
XLA的源码主要分布在github.com/tensorflow/tensorflow的多个目录下,对应不同的模块。使用XLA时,可以采用JIT(Just-In-Time)或AOT( Ahead-Of-Time)两种编译方式。JIT方式更为普遍,对用户负担较小,只需开启一个开关即可享受到加速效果。本文将专注于JIT的实现与理解。
JIT通过在Tensorflow运行时,从Graph中选择特定子图进行XLA编译与运行,实现了对计算图的加速。Tensorflow提供了一种名为JIT的使用方式,它通过向Tensorflow注册多个优化PASS来实现这一功能。这些优化PASS的执行顺序决定了加速效果。
核心的优化PASS包括但不限于EncapsulateXlaComputationsPass、MarkForCompilationPass、EncapsulateSubgraphsPass、BuildXlaOpsPass等。EncapsulateXlaComputationsPass负责将具有相同_xla_compile_id属性的算子融合为一个XlaLaunch,而XlaLaunch在运行时将子图编译并执行。
AutoClustering则自动寻找适合编译的子图,将其作为Cluster进行优化。XlaCompileOp承载了Cluster的所有输入和子图信息,在运行时通过编译得到XlaExecutableClosure,最终由XlaRunOp执行。
在JIT部分,关键在于理解和实现XlaCompilationCache::CompileStrict中的编译逻辑。此过程包括两步,最终结果封装在XlaCompilationResult和LocalExecutable中,供后续使用。
tf2xla模块负责将Tensorflow Graph转化为XlaCompilationResult(HloModuleProto),实现从Tensorflow到XLA的转换。在tf2xla中定义的XlaOpKernel用于封装计算过程,并在GraphCompiler::Compile中实现每个Kernel的计算,即执行每个XlaOpKernel的Compile。
xla/client模块提供了核心接口,用于构建计算图并将其转换为HloModuleProto。XlaBuilder构建计算图的结构,而XlaOpKernel通过使用这些基本原语描述计算过程,最终通过xla_builder的Build方法生成HloComputationProto。
xla/service模块负责将HloModuleProto编译为可执行的Executable。该过程涉及多个步骤,包括LLVMCompiler的编译和优化,最终生成适合特定目标架构的可执行代码。此模块通过一系列的优化pass,如RunHloPasses和RunBackend,对HloModule进行优化和转换,最终编译为目标代码。
本文旨在提供XLA源码的深度解读,帮助开发者理解其工作机制和实现细节。如有问题或疑问,欢迎指正与交流,共同探讨和学习。期待与您在下一篇文章中再次相遇。
电脑macOS mojave ..6, 编译tensorflow2.6解决SSE4.1 SSE4.2 AVX指令集问题。
针对macOS mojave ..6系统用户在编译tensorflow 2.6版本时遇到的SSE4.1、SSE4.2和AVX指令集问题,以下为解决步骤:
首先,前往tensorflow源码下载页面,下载v2.6.0版本。
然后,进入下载后的目录,定位至v2.6.0。
接下来,准备必要的软件环境。确保已安装java和minconda。
开始编译tensorflow时,关键在于使用优化指令集。在执行编译命令时,加入参数`-march=native`以进行cpu指令集优化。
使用命令行进行编译:`bazelisk build -c opt --copt=-march=native //tensorflow/tools/pip_package:build_pip_package`。
编译完成后,在/tmp/tensorflow_pkg目录下找到生成的wheel文件。使用pip进行安装,即可完成tensorflow 2.6版本的安装。
完成编译与安装后,用户可根据需要下载tensorflow-2.6.0-cp-cpm-macosx___x_.whl文件。提取码为kkli。
2024-11-30 07:41
2024-11-30 07:37
2024-11-30 06:50
2024-11-30 06:47
2024-11-30 06:25
2024-11-30 06:02
