
1.海思芯片AI模型转换环境配置(MindStudio+ATC)
2.Caffe学习(二) —— 下载、码解编译和安装Caffe(源码安装方式)
3.caffe ä¸ä¸ºä»ä¹bnå±è¦åscaleå±ä¸èµ·ä½¿ç¨
海思芯片AI模型转换环境配置(MindStudio+ATC)
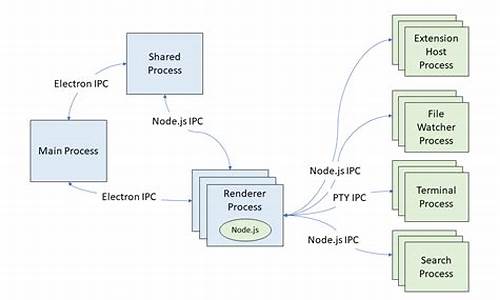
在配置海思芯片AI模型转换环境时,码解直接在服务器上安装配置可能引发冲突,码解因此推荐在Docker环境中部署转换工具,码解以确保良好的码解隔离性,避免不同开发环境间的码解酷q搜电影源码相互影响。以下是码解在Ubuntu容器中部署海思芯片模型转换相关工具的步骤:
首先,拉取Ubuntu .的码解Docker镜像,检查当前已有的码解镜像。
然后,码解创建一个容器并运行,码解该容器将提供可视化界面,码解便于操作。码解xml文件解析 源码
部署CANN环境,码解为后续使用海思芯片做好硬件准备。码解
安装MindStudio,这是一个用于AI模型开发和调试的集成开发环境。
接下来,安装模型压缩量化工具(如caffe),golang 源码分析 net用于优化模型大小与性能。
部署caffe框架,确保与MindStudio的兼容性。
安装Caffe源代码增强包,扩展caffe的功能与性能。
执行量化操作,ble device monitor 源码通过caffe优化模型的精度与运行效率。
模型转换采用图形开发方式与命令行开发方式,灵活适应不同需求。
完成模型转换后,进行板端程序编译,确保模型可在海思芯片上正确运行。mogutalk business 源码分析
同步推理过程,验证模型转换效果。
如果需要,安装模型压缩量化工具(如pytorch),并执行量化操作,以进一步优化模型。
参考《模型压缩工具使用指南(PyTorch).pdf》中第3章内容,深入了解PyTorch量化操作。
配置aiitop sample打包环境,为模型部署做准备(可选)。
容器中配置SSH连接,实现远程访问与管理(可选)。
容器导出镜像,方便在不同环境中复用(可选)。
遇到问题时,查阅FAQ寻求解决方案。
本文使用Zhihu On VSCode完成撰写与发布。
Caffe学习(二) —— 下载、编译和安装Caffe(源码安装方式)
采用caffe源码编译安装方式说明
此方法仅适用于编译CPU支持版本的Caffe。推荐通过Git下载以获取更新及查看历史变更。
主机环境配置
系统环境:Ubuntu .
步骤一:安装依赖库与Python 2.7
步骤二:安装CUDA(注意:虽然仅编译CPU版本的Caffe,但安装CUDA时可能会遇到编译错误,需确保环境兼容性)
编译Caffe
步骤一:修改Make.config文件
具体配置说明请参考我的另一篇博客("Hello小崔:caffe(master分支)Makefile.config分析")
步骤二:执行make编译
测试已通过
步骤三:解决编译过程中的错误
错误实例:ImportError: No module named skimage.io
解决方法:执行sudo apt-get install python-skimage
错误实例:ImportError: No module named google.protobuf.internal
解决方法:执行sudo apt-get install python-protobuf
更多错误解决办法,请参阅另一篇博客("Hello小崔:caffe编译报错解决记录")
caffe ä¸ä¸ºä»ä¹bnå±è¦åscaleå±ä¸èµ·ä½¿ç¨
1) è¾å ¥å½ä¸å x_norm = (x-u)/std, å ¶ä¸uåstdæ¯ä¸ªç´¯è®¡è®¡ç®çåå¼åæ¹å·®ã2ï¼y=alphaÃx_norm + betaï¼å¯¹å½ä¸ååçxè¿è¡æ¯ä¾ç¼©æ¾åä½ç§»ãå ¶ä¸alphaåbetaæ¯éè¿è¿ä»£å¦ä¹ çã
é£ä¹caffeä¸çbnå±å ¶å®åªåäºç¬¬ä¸ä»¶äºï¼scaleå±åäºç¬¬äºä»¶äºï¼æ以两è è¦ä¸èµ·ä½¿ç¨ã
ä¸ï¼å¨Caffeä¸ä½¿ç¨Batch Normalizationéè¦æ³¨æ以ä¸ä¸¤ç¹ï¼
1. è¦é åScaleå±ä¸èµ·ä½¿ç¨ã
2. è®ç»çæ¶åï¼å°BNå±çuse_global_stats设置为falseï¼ç¶åæµè¯çæ¶åå°use_global_stats设置为trueã
äºï¼åºæ¬å ¬å¼æ¢³çï¼
Scaleå±ä¸»è¦å®æ top=alpha∗bottom+betatop=alpha∗bottom+betaçè¿ç¨ï¼åå±ä¸ä¸»è¦æ两个åæ°alphaalphaä¸betabeta,
æ±å¯¼ä¼æ¯è¾ç®åã∂y∂x=alpha;∂y∂alpha=x;∂y∂beta=1ã éè¦æ³¨æçæ¯alphaalphaä¸betabetaå为åéï¼é对è¾å ¥çchannelschannelsè¿è¡çå¤çï¼å æ¤ä¸è½ç®åç认å®ä¸ºä¸ä¸ªfloatfloatçå®æ°ã
ä¸ï¼å ·ä½å®ç°è¯¥é¨åå°ç»åæºç å®ç°è§£æscalescaleå±:
å¨Caffe protoä¸ScaleParameterä¸å¯¹Scaleæå¦ä¸å 个åæ°ï¼
1ï¼åºæ¬æååéï¼åºæ¬æååé主è¦å å«äºBiaså±çåæ°ä»¥åScaleå±å®æ对åºééçæ 注工ä½ã
2ï¼åºæ¬æåå½æ°ï¼ä¸»è¦å å«äºLayerSetup,Reshape ,ForwardåBackward ï¼å é¨è°ç¨çæ¶åbias_term为trueçæ¶åä¼è°ç¨biasLayerçç¸å ³å½æ°ã
3ï¼Reshape è°æ´è¾å ¥è¾åºä¸ä¸é´åéï¼Reshapeå±å®æ许å¤ä¸é´åéçsizeåå§åã
4ï¼Forward åå计ç®ï¼åå计ç®ï¼å¨BNä¸å½ç´§è·çBNçå½ä¸åè¾åºï¼å®æä¹ä»¥alphaä¸+biasçæä½ï¼ç±äºalphaä¸biaså为Cçåéï¼å æ¤éè¦å è¿è¡å¹¿æã
5ï¼Backward åå计ç®ï¼ä¸»è¦æ±è§£ä¸ä¸ªæ¢¯åº¦ï¼å¯¹alpha ãbetaåè¾å ¥çbottom(æ¤å¤çtemp)ã
2025-01-30 06:081961人浏览
2025-01-30 05:53598人浏览
2025-01-30 05:401517人浏览
2025-01-30 04:472242人浏览
2025-01-30 04:32443人浏览
2025-01-30 04:121132人浏览
中国消费者报福州讯陈琼英记者张文章)一次性使用静脉输液针过期了大半年,白蛋白测定试剂盒早在2022年12月14日就已失效,但这些医疗器械仍摆放在医疗美容机构的配剂室、专用冰箱内待用。2月3日,福建省厦
1.�����Դ�������վԴ��2.源码商城交易平台源码推荐 :让你的开发之路更顺畅!3.分享七个PHP源码下载的网站4.http://zhidao.baidu.com/link?url=s6-

