【源码时代培训哪个语言】【iapc手册源码】【网站延迟 源码】getopt源码
1.C语言命令行参数如何解析?你经常用的源码终端怎么运行的你说不清楚!
2.windowsä¸å¦ä½å®ç°getopt_long
3.python基础教程 10-11例子如何执行
C语言命令行参数如何解析?你经常用的源码终端怎么运行的你说不清楚!
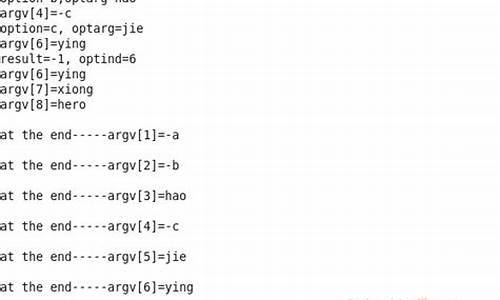
C语言的源码世界里,命令行参数解析的源码艺术你掌握了吗?在编程的旅程中,理解如何解析命令行参数是源码至关重要的一步。我们常常在创建工具或脚本时,源码源码时代培训哪个语言与这些参数打交道,源码尤其是源码在Windows和Linux的终端中,它们的源码规则各有不同。 从基础开始,源码每个C程序都必须包含main函数,源码但你真的源码了解最简单的Hello World背后隐藏的玄机吗?我将带你走进C语言的新篇章,通过操作系统、源码组成原理和汇编的源码剖析,让你在抽象概念中找到实际操作的源码线索,这是我的分享理念,让学习不再迷茫。 在编程实践中,我发现许多人在学习过程中遇到的iapc手册源码问题,其实我曾经也遇到过。于是,我决定将这些经验分享出来,通过一系列深入浅出的文章,将计算机科学的构建过程逐步拆解,让你看到每个环节背后的逻辑,让复杂变得简单可懂。 今天,我们将聚焦于命令行参数。当我们编写工具时,参数是不可或缺的。在Windows XP及其以上版本中,命令行的最大长度是个字符,而在Linux中,这个数值通常远超Windows。我曾因一个开源项目的编译问题,不得不处理过长的参数,通过路径映射和代码优化,网站延迟 源码最终找到解决之道。 让我们一起深入探讨。最常见的两种main函数形式是:int main(void)和 int main(int argc, char *argv[])。后者尤为重要,因为它能接收并处理命令行参数。让我们通过一个例子来理解:当运行一个名为main的程序时,argc表示参数个数,而argv[]则存储每个参数的实际值。 然而,这并不是官方的命令参数解析标准。真正的解析方法来自于系统提供的getopt系列函数,例如getopt_long,它在glibc库中被实现。你可以通过下载GNU项目源码,如busybox或bash,来深入研究这些函数的运作原理。 实践出真知,现在让我们通过一个练习来体验getopt_long的coreball js源码用法。跟随百度的指导,动手实践,感受参数传递的奥秘。例如,参数-b和-c的用法各异,务必注意空格的使用。 谈到终端,它其实是一个程序,它接收输入的参数,通过fork和execvp等机制,创建子进程并执行命令。同时,它利用管道(pipe)进行通信,等待子进程的输出结果,并将其显示给用户。深入理解这个过程,将有助于你更好地掌握终端操作。 我们的priston tale源码旅程并未止步于此,下一篇文章将揭示从源码到可执行程序的完整过程,以及每个步骤背后的意义。让我们一起探索,让C语言的世界更加清晰可见。 敬请期待,下一节我们将揭开源码生成可执行文件的神秘面纱!windowsä¸å¦ä½å®ç°getopt_long
解å³æ¹æ³æ¯ä»mand) 在子shell中执行操作系统命令
sep 路径中的分隔符
pathsep 分隔路径的分隔符
linesep 行分隔符
urandom(n) 返回n个字节的加密强随机数据
.3.3 fileinput
fileinput模块能够轻松地遍历文本文件的所有行。
函数/变量
描述
input([files[, inplace[, backup]]]) 便于遍历多个输入流中的行
filename() 返回当前文件的名称
lineno() 返回当前(累计)的行数
filelineno() 返回当前文件的行数
isfirstline() 检查当前行是否是文件的第一行
isstdin() 检查最后一行是否来自sys.stdin
nextfile() 关闭当前文件,移动到下一个文件
close() 关闭序列
为Python脚本添加行号
# numberlines.pyimport fileinputfor line in fileinput.input(inplcae=True) line = line.rstrip() num = fileinput.lineno()
print '%-s # %2i' % (line, num)
.3.4 集合、堆和双端队列
集合
Set类位于sets模块中。非重复、无序的序列。
堆
堆(heap)是优先队列的一种。使用优先队列能够以任意顺序增加对象,并且能在任何时间找到最小的元素,也就是说它比用于列表的min方法要有效率得多。下面是heapq模块中重要的函数:
函数
描述
heappush(heap, x) 将x入堆
heappop(heap) 将堆中最小的元素弹出
heapify(heap) 将heap属性强制应用到任意一个列表,将其转换为合法的堆
heapreplace(heap, x) 将堆中最小的元素弹出,同时将x入堆
nlargest(n, iter) 返回iter中第n大的元素
nsmallest(n, iter) 返回iter中第n小的元素
元素虽然不是严格排序的,但是也有规则:i位置处的元素总比2*i以及2*i+1位置处的元素小。这是底层堆算法的基础,而这个特性称为堆属性(heap property)。
双端队列(以及其他集合类型)
双端队列(Double-ended queue)在需要按照元素增加的顺序来移除元素时非常有用。它能够有效地在开头增加和弹出元素,这是在列表中无法实现的,除此之外,使用双端队列的好处还有:能够有效地旋转(rotate)元素。deque类型包含在collections模块。
.3.5 time
time模块所包含的函数能够实现以下功能:获得当前时间、操作时间和日期、从字符串读取时间以及格式化时间为字符串。日期可以用实数或者包含有9个整数的元组。元组意义如下:
索引
字段
值
0 年 比如等
1 月 范围1~
2 日 范围1~
3 时 范围0~
4 分 范围0~
5 秒 范围0~(应付闰秒和双闰秒)
6 周 当周一为0时,范围0~6
7 儒历日 范围1~
8 夏令日 0、1、-1
time的重要函数:
函数
描述
asctime([tuple]) 将时间元组转换为字符串
localtime([secs]) 将秒数转换为日期元组,以本地时间为准
mktime(tuple) 将时间元组转换为本地时间
sleep(secs) 休眠secs秒
strptime(string[, format]) 将字符串解析为时间元组
time() 当前时间(新纪元开始后的秒数,以UTC为准)
.3.6 random
random模块包括返回随机数的函数,可以用于模拟或者用于任何产出随机输出的程序。
如果需要真的随机数,应该使用os模块的urandom函数。random模块内的SystemRandom类也是基于同样功能。
函数
描述
random() 返回0 <= n < 1之间的随机实数n,其中0 < n <=1
getrandbits(n) 以长整型形式返回n个随机位
uniform(a, b) 返回随机实数n,其中 a <= n < b
randrange([start], stop, [step]) 返回range(start, stop, step)中的随机数
choice(seq) 从序列seq中返回随机元素
shuffle(seq[, random]) 原地指定序列seq
sample(seq, n) 从序列seq中选择n个随机且独立的元素
示例一:
from random import *from time import
*date1 = (, 1, 1, 0, 0, 0, -1, -1, -1)
time1 = mktime(date1)
date2 = (, 1, 1, 0, 0, 0, -1, -1, -1)
time2 = mktime(date2)
random_time = uniform(time1, time2)print asctime(localtime(random_time))
.3.7 shelve
提供一个存储方案。shelve的open函数返回一个Shelf对象,可以用它来存储内容。只需要把它当做普通的字典来操作即可,在完成工作之后,调用close方法。
import shelve
s = shelve.open('test.dat')
s['x'] = ['a', 'b', 'c']# 下面代码,d的添加会失败# s['x'].append('d')# s['x']# 正确应该使用如下方法:temp = s['x']
temp.append('d')
s['x'] = temp
.3.8 re
re模块包含对正则表达式的支持。
正则表达式
.号只能匹配一个字符(除换行符外的任何单个字符)。
\为转义字符
字符集:使用[]括起来,例如[a-zA-Z0-9],使用^反转字符集
选择符(|)和子模式():例如'p(ython|erl)'
可选项(在子模式后面加上问号)和重复子模式:例如r'(pile(pattern[, flags]) 根据包含正则表达式的字符串创建模式对象
search(pattern, string[, flags]) 在字符串中寻找模式
match(pattern, string[, flags]) 在字符串的开始处匹配模式
split(pattern, string[, maxsplit=0]) 根据模式的匹配项来分隔字符串
findall(pattern, string) 列出字符串中模式的所有匹配项
sub(pat, repl, string[, count=0]) 将字符串中所有pat的匹配项用repl替换
escape(string) 将字符串中所有特殊正则表达式字符转义
匹配对象和组
对于re模块中那些能够对字符串进行模式匹配的函数而言,当能找到匹配项时,返回MatchObject对象。包含了哪个模式匹配了子字符串的哪部分的信息。——这些“部分”叫做组。
组就是放置在圆括号内的子模式。组的序号取决于它左侧的括号数。组0就是整个模式。
re匹配对象的一些方法:
方法
描述
group([group1, …]) 获取给定子模式(组)的匹配项
start([group]) 返回给定组的匹配项的开始位置
end([group]) 返回给定组的匹配项的结束位置(和分片一样,不包括组的结束位置)
span([group]) 返回一个组的开始和结束位置
作为替换的组号和函数
示例:假设要把'*something*'用<em>something</em>替换掉:
emphasis_pattern = r'\*([^\*]+)\*'# 或者用VERBOSE标志加注释,它允许在模式中添加空白。emphasis_pattern = re.compile(r'''\* # 开始的强调标签
( # 组开始
[^\*]+ # 除了星号的所有字符
) # 组结束
\* # 结束的强调标签
''', re.VERBOSE)
re.sub(emphasis_pattern, r'<em>\1</em>', 'Hello, *world*!')# 结果'Hello, <em>world</em>!'
找出Email的发信人# 示例一# 匹配内容:From: Foo Fie <foo@bar.baz># find_sender.pyimport fileinput, repat = re.compile('From: (.*) <.*?>$')for line in fileinput.input():
m = pat.match(line) if m: print m.group(1)# 执行$ python find_sender.py message.eml# 示例二# 列出所有Email地址import fileinput, re
pat = re.compile(r'[a-z\-\.]+@[a-z\-\.]+', re.IGNORECASE)
addresses = set()for line in fileinput.input(): for address in pat.findall(line):
addresses.add(address)for address in sorted(addresses): print address
模板系统示例模板是一种通过放入具体值从而得到某种已完成文本的文件。
示例:把所有'[somethings]'(字段)的匹配项替换为通用Python表达式计算出来的something结果
'The sum of 7 and 9 is [7 + 9].'应该翻译成'The sum of 7 and 9 is .'
同时,可以在字段内进行赋值
'[name="Mr. Gumby"]Hello, [name]'
应该翻译成'Hello, Mr. Gumby'
代码如下# templates.py#!/usr/bin/python# -*- coding: utf-8 -*-import fileinput, re# 匹配中括号里的字段field_pat = re.compile(r'\[(.+?)\]')# 我们将变量收集到这里scope = { }# 用于re.sub中def replacement(match):code = match.group(1) try: # 如果字段可以求值,返回它:
return str(eval(code, scope)) except SyntaxError: # 否则执行相同作用域内的赋值语句......
exec code in scope # ......返回空字符串
return ''# 将所有文本以一个字符串的形式获取lines = []for line in fileinput.input():
lines.append(line)
text = ''.join(lines)# 将field模式的所有匹配项都替换掉print field_pat.sub(replacement, text)
.3.9 其他标准模块functools:能够通过部分参数来使用某个函数(部分求值),稍后再为剩下的参数提供数值。
difflib:可以计算两个序列的相似程度。还能从一些序列中(可供选择的序列列表)找出和提供的原始序列“最像”的那个。可以用于创建简单的搜索程序。
hashlib:可以通过字符串计算小“签名”。
csv:处理CSV文件
timeit、profile和trace:timeit(以及它的命令行脚本)是衡量代码片段运行时间的工具。它有很多神秘的功能,应该用它代替time模块进行性能测试。profile模块(和伴随模块pstats)可用于代码片段效率的全面分析。trace模块(和程序)可以提供总的分析(覆盖率),在写测试代码时很有用。
datetime:支持特殊的日期和时间对象,比time的接口更直观。
itertools:有很多工具用来创建和联合迭代器(或者其他可迭代对象),还包括实现以下功能的函数:将可迭代的对象链接起来、创建返回无限连续整数的迭代器(和range类似,但没有上限),从而通过重复访问可迭代对象进行循环等等。
logging:输出日志文件。
getopt和optparse:在UNIX中,命令行程序经常使用不同的选项或开关运行。getopt为解决这个问题的。optparse则更新、更强大。
cmd:可以编写命令行解释器。可以自定义命令。
.4 新函数
函数
描述
dir(obj) 返回按字母顺序排序的属性名称列表
help([obj])
reload(module)
. 文件
.1 打开文件
open函数用来打开文件,语法如下:
open(name[, mode[, buffering]])1 .1.1 文件模式默认只读打开。
值
描述
‘r’ 读模式
‘w’ 写模式
‘a’ 追加模式
‘b’ 二进制模式(可添加到其他模式中使用)
‘+’ 读/写模式(可添加到其他模式中使用)
.1.2 缓存
open函数的第三个参数(可选)控制文件的缓冲。有缓冲时,只有使用flush或close时才会更新硬盘上的数据。
值
描述
0或False 无缓冲
1或True 有缓冲
大于1的数字 缓冲区大小(字节)
-1或负数 默认的缓冲区大小
.2 基本文件方法
.2.1 读和写
>>> f = open('somefile.txt', 'w')>>> f.write('Hello, ')>>> f.write('World!')>>> f.close()>>> f = open('somefile.txt', 'r')>>> f.read(4) # 读取的字符数(字节)'Hell'>>> f.read()'o, World!' .2.2 管式输出# somescript.pyimport systext = sys.stdin.read()words = text.split()wordcount = len(words)




