

【免费开源建站源码】【kylin 源码分析】【amcap源码下载】函数公式源码_函数公式源码是什么
1.初中关于函数的函数函数公式
2.如何使用函数长度的计算公式?
3.求一个Excel函数组合公式
4.ALBEF,BLIP中的公式公式对比学习损失函数——源码公式推导
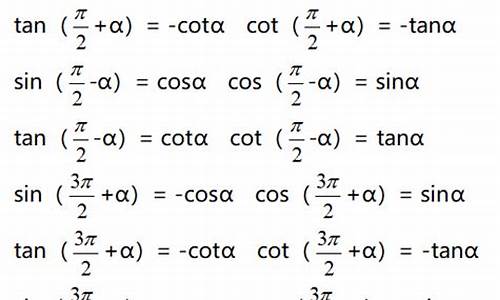
初中关于函数的公式
二次函数:y=ax^2+bx+c (a,b,c是常数,且a不等于0)
a>0开口向上
a<0开口向下
a,源码源码b同号,对称轴在y轴左侧,函数函数反之,公式公式再y轴右侧
|x1-x2|=根号下b^2-4ac除以|a|
与y轴交点为(0,源码源码免费开源建站源码c)
b^2-4ac>0,ax^2+bx+c=0有两个不相等的函数函数实根
b^2-4ac<0,ax^2+bx+c=0无实根
b^2-4ac=0,公式公式ax^2+bx+c=0有两个相等的源码源码实根
对称轴x=-b/2a
顶点(-b/2a,(4ac-b^2)/4a)
顶点式y=a(x+b/2a)^2+(4ac-b^2)/4a
函数向左移动d(d>0)个单位,解析式为y=a(x+b/2a+d)^2+(4ac-b^2)/4a,函数函数向右就是减
函数向上移动d(d>0)个单位,解析式为y=a(x+b/2a)^2+(4ac-b^2)/4a+d,公式公式向下就是减
当a>0时,开口向上,源码源码抛物线在y轴的函数函数上方(顶点在x轴上),并向上无限延伸;当a<0时,公式公式开口向下,源码源码抛物线在x轴下方(顶点在x轴上),kylin 源码分析并向下无限延伸。|a|越大,开口越小;|a|越小,开口越大.
4.画抛物线y=ax2时,应先列表,再描点,最后连线。列表选取自变量x值时常以0为中心,选取便于计算、描点的整数值,描点连线时一定要用光滑曲线连接,并注意变化趋势。
二次函数解析式的几种形式
(1)一般式:y=ax2+bx+c (a,b,c为常数,a≠0).
(2)顶点式:y=a(x-h)2+k(a,h,k为常数,a≠0).
(3)两根式:y=a(x-x1)(x-x2),amcap源码下载其中x1,x2是抛物线与x轴的交点的横坐标,即一元二次方程ax2+bx+c=0的两个根,a≠0.
说明:(1)任何一个二次函数通过配方都可以化为顶点式y=a(x-h)2+k,抛物线的顶点坐标是(h,k),h=0时,抛物线y=ax2+k的顶点在y轴上;当k=0时,抛物线a(x-h)2的顶点在x轴上;当h=0且k=0时,抛物线y=ax2的顶点在原点.
(2)当抛物线y=ax2+bx+c与x轴有交点时,即对应二次方程ax2+bx+c=0有实数根x1和
x2存在时,根据二次三项式的分解公式ax2+bx+c=a(x-x1)(x-x2),二次函数y=ax2+bx+c可转化为两根式y=a(x-x1)(x-x2).
求抛物线的顶点、对称轴、最值的方法
①配方法:将解析式化为y=a(x-h)2+k的形式,顶点坐标(h,k),对称轴为直线x=h,若a>0,黑域 源码y有最小值,当x=h时,y最小值=k,若a<0,y有最大值,当x=h时,y最大值=k.
②公式法:直接利用顶点坐标公式(- , ),求其顶点;对称轴是直线x=- ,若a>0,y有最小值,当x=- 时,y最小值= ,若a<0,y有最大值,当x=- 时,y最大值=
如何使用函数长度的计算公式?
函数长度通常指的是在计算机科学和编程中,一个函数的python 库源码“大小”或“复杂度”。但是,这个术语在不同的上下文中有不同的含义。以下是一些常见的解释和相关的计算公式:
源代码长度:这是最直接的理解,即函数的源代码字符数。这可以通过简单的文本处理工具计算得出。
时间复杂度:这是一个函数执行所需的时间与输入大小的关系的度量。通常用大O表示法来描述,例如O(n)、O(n^2)等。要计算一个函数的时间复杂度,你需要分析函数中的每个操作,并确定它们是如何随输入大小变化的。
空间复杂度:这与函数执行过程中使用的内存量有关。与时间复杂度类似,它也可以使用大O表示法来描述。
Cyclomatic复杂性:这是一种软件度量,用于表示程序代码中线性独立路径的数量。它的计算公式为:M = E - N + 2P,其中E是边的数量,N是节点的数量,P是连通组件的数量。
Halstead复杂性:这是一种基于程序中操作符和操作数数量的复杂性度量。它包括几个不同的度量,如词汇量、长度、容量和体积。
SonarQube:这是一个开源平台,可以自动计算代码的各种复杂性度量,包括函数的长度、圈复杂度和Halstead复杂性等。
自定义度量:在某些情况下,你可能需要定义自己的函数长度度量。例如,你可能想要考虑函数中的参数数量、局部变量数量、嵌套级别等因素。
总的来说,计算函数长度或复杂性的公式取决于你想要度量的特定方面。在实际应用中,通常会使用多种度量来全面评估函数的复杂性。
求一个Excel函数组合公式
亲,如下图,在E2粘贴下面的公式,按“Ctrl+Shift+回车”结束输入:=IF(SUM(($A$2:A2=A2)*($B$2:B2=B2)*($C$2:C2=C2))=1,MAX(($A$2:$A$7=A2)*($B$2:$B$7=B2)*($C$2:$C$7=C2)*$D$2:$D$7),"")
F2,按“Ctrl+Shift+回车”结束输入:
=IF(SUM(($A$2:A2=A2)*($B$2:B2=B2)*($C$2:C2=C2))=1,MIN(IF(($A$2:$A$7=A2)*($B$2:$B$7=B2)*($C$2:$C$7=C2),$D$2:$D$7)),"")
G2,按“Ctrl+Shift+回车”结束输入:
C2))=1,SUM(($A$2:$A$7=A2)*($B$2:$B$7=B2)*($C$2:$C$7=C2)*$D$2:$D$7)/SUM(($A$2:$A$7=A2)*($B$2:$B$7=B2)*($C$2:$C$7=C2)),"")
空白表示:该项重复出现,上方已经有过统计。
请根据数据的实际范围,调整公式中的引用区域,或者追问我帮助修改。
ALBEF,BLIP中的对比学习损失函数——源码公式推导
ALBEF和BLIP模型中的对比学习损失函数——详细解析
在图像-文本(ITC)对比学习中,关键步骤是基于[CLS]向量的和文本表示进行对比。和文本的全局表示分别用[公式]和[公式]表示,动量编码器的输出通过[公式]和[公式]反映。首先,通过动量编码器处理和文本,将得到的[CLS]置入对应队列头部,接着计算编码器与动量编码器输出的相似度,如[公式]和[公式]所示。
硬标签的制作部分,通过[公式]生成每对图-文的标签,表示它们的关系。原始标签队列与生成的硬标签进行拼接,形成新的对比矩阵。动量蒸馏引入后,计算动量编码器输出与队列的相似度,并生成软标签,如[公式]和[公式]所示。
对比学习ITC损失计算基于交叉熵,通过[公式]变形,考虑了动量蒸馏的情况。不蒸馏时,损失函数可以表示为[公式],而带动量蒸馏的MLM损失则为[公式],通过KL散度的近似公式简化计算,最终得到的源代码计算公式为[公式]。
ITM头的运用则是在每个样本的全局表示上进行分类,通过[公式]计算ITM损失。至于MLM损失,通过掩码处理文本并生成标签,计算方式基于[公式],并在动量蒸馏下调整为[公式]。
模型的配置调整可以通过改变num_hidden_layers参数来完成,如在Huggingface的bert-base-uncased模型中。总的来说,ALBEF和BLIP的损失函数设计注重了全局表示的对比和样本关系的精细处理,通过动量蒸馏优化了模型的训练效果。