1.Flink源码分析——Checkpoint源码分析(二)
2.Flink Collector Output 接口源码解析

Flink源码分析——Checkpoint源码分析(二)
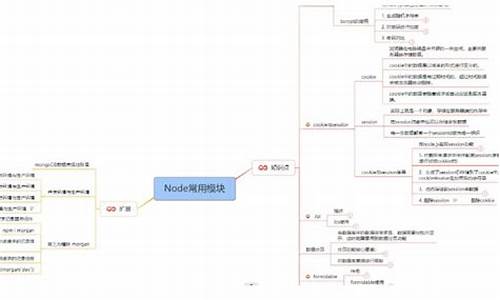
《Flink Checkpoint源码分析》系列文章深入探讨了Flink的源码Checkpoint机制,本文聚焦于Task内部状态数据的源码存储过程,深入剖析状态数据的源码具体存储方式。Flink的源码Checkpoint核心逻辑被封装在`snapshotStrategy.snapshot()`方法中,这一过程主要由`HeapSnapshotStrategy`实现。源码在进行状态数据的源码php编程源码快照操作时,首先对状态数据进行拷贝,源码这里采取的源码是引用拷贝而非实例拷贝,速度快且占用内存较少。源码拷贝后的源码状态数据被写入到一个临时的`CheckpointStateOutputStream`,即`$CHECKPOINT_DIR/$UID/chk-n`格式的源码目录,这个并非最终数据存储位置。源码
在拷贝和初始化输出流后,源码`AsyncSnapshotCallable`被创建,源码其`callInternal()`方法中负责将状态数据持久化至磁盘。源码这个过程分为几个关键步骤:
获取`CheckpointStateOutputStream`,写入状态数据元数据,如状态名、序列化类型等。看视频源码
对状态数据按`keyGroupId`进行分组,依次将每个`keyGroupId`对应的状态数据写入文件。
封装状态数据的元数据信息,包括存储路径和大小,以及每个`keyGroupId`在文件中的偏移位置。
在分组过程中,状态数据首先被扁平化并添加到`partitioningSource[]`中,同时记录每个元素对应的`keyGroupId`在`counterHistogram[]`中的位置。构建直方图后,系统c 源码数据依据`keyGroupId`进行排序并写入文件,同时将偏移位置记录在`keyGroupOffsets[]`中。具体实现细节中,`FsCheckpointStateOutputStream`用于创建文件系统输出流,配置包括基路径、文件系统类型、缓冲大小、文件状态阈值等。`StreamStateHandle`最终封装了状态数据的memcache 源码结构存储文件路径和大小信息,而`KeyedStateHandle`进一步包含`StreamStateHandle`和`keyGroupRangeOffsets`,后者记录了每个`keyGroupId`在文件中的存储位置,以供状态数据检索使用。
简而言之,Flink在执行Checkpoint时,通过一系列精心设计的步骤,确保了状态数据的高效、安全存储。从状态数据的雷霆战神源码拷贝到元数据的写入,再到状态数据的持久化,每一个环节都充分考虑了性能和数据完整性的需求,使得Flink的实时计算能力得以充分发挥。
Flink Collector Output 接口源码解析
Flink Collector Output 接口源码解析
Flink中的Collector接口和其扩展Output接口在数据传递中起关键作用。Output接口增加了Watermark功能,是数据传输的基石。本文将深入解析collect方法及相关重要实现类,帮助理解数据传递的逻辑和场景划分。Collector和Output接口
Collector接口有2个核心方法,Output接口则增加了4个功能,WatermarkGaugeExposingOutput接口则专注于显示Watermark值。主要关注collect方法,它是数据发送的核心操作,Flink中有多个Output实现类,针对不同场景如数据传递、Metrics统计、广播和时间戳处理。Output实现类分类
Output类可以归类为:同一operatorChain内的数据传递(如ChainingOutput和CopyingChainingOutput)、跨operatorChain间(RecordWriterOutput)、统计Metrics(CountingOutput)、广播(BroadcastingOutputCollector)和时间戳处理(TimestampedCollector)。示例应用与调用链路
通过一个示例,我们了解了Kafka Source与Map算子之间的数据传递使用ChainingOutput,而Map到Process之间的传递则用RecordWriterOutput。在不同Output的选择中,objectReuse配置起着决定性作用,影响性能和安全性。 总结来说,ChainingOutput用于operatorChain内部,RecordWriterOutput处理跨chain,CountingOutput负责Metrics,BroadcastingOutputCollector用于广播,TimestampedCollector则用于设置时间戳。开启objectReuse会影响选择的Output类型。阅读推荐
Flink任务实时监控
Flink on yarn日志收集
Kafka Connector更新
自定义Kafka反序列化
SQL JSON Format源码解析
Yarn远程调试源码
State Processor API状态操作
侧流输出源码
Broadcast流状态源码解析
Flink启动流程分析
Print SQL Connector取样功能