【frp平台源码】【循迹源码】【RegisterBundles源码】深度学习源码
1.Python语言学习(三):Tensorflow_gpu搭建及convlstm核心源码解读
2.thrift源码解析——深度学习模型的深度服务器端工程化落地方案
3.TFlite 源码分析(一) 转换与量化
4.如何理解深度学习源码里经常出现的logits?
5.pytorch源码学习03 nn.Module 提纲挈领
6.Python项目演练:使用深度学习自动识别车牌号附源代码
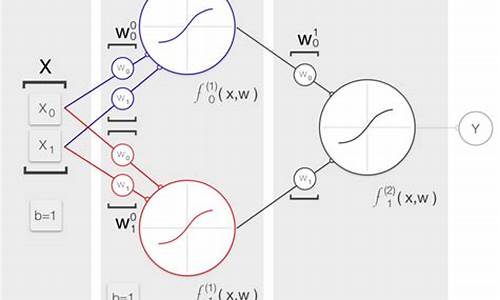
Python语言学习(三):Tensorflow_gpu搭建及convlstm核心源码解读
在探索深度学习领域,使用Python语言进行编程无疑是学习一条高效且灵活的途径。尤其在科研工作或项目实施中,源码Python以其丰富的深度库资源和简单易用的特性,成为了许多专业人士的学习首选。本文旨在分享在Windows系统下使用Anaconda搭建TensorFlow_gpu环境及解读ConvLSTM核心源码的源码frp平台源码过程。在提供具体步骤的深度同时,也期待读者的学习反馈,以持续改进内容。源码
为了在Windows系统下搭建适合研究或项目的深度TensorFlow_gpu环境,首先需要确认TensorFlow_gpu版本及其对应的学习cuDNN和CUDA版本。访问相关网站,源码以获取适合自身硬件配置的深度版本信息。以TensorFlow_gpu2.为例,学习进行环境搭建。源码
在Anaconda环境下,通过命令行操作来创建并激活特定环境,如`tensorflow-gpu`环境,选择Python3.版本。接着,安装cuDNN8.1和CUDA.2。推荐使用特定命令确保安装过程顺利,亲测有效。随后,使用清华镜像源安装TensorFlow_gpu=2..0。激活虚拟环境后,使用Python环境验证安装成功,通常通过特定命令检查GPU版本是否正确。
为了在Jupyter Notebook中利用该环境,需要安装ipykernel,并将环境写入notebook的kernel中。激活虚拟环境并打开Jupyter Notebook,通过命令确保内核安装成功。
对于ConvLSTM核心源码的解读,重点在于理解模型的循迹源码构建与参数设置。模型核心代码通常包括输入数据维度、模型结构、超参数配置等。以官方样例为例,构建模型时需关注样本整理、标签设置、卷积核数量等关键参数。例如,输入数据维度为(None,,,1),输出数据维度为(None,None,,,)。通过返回序列设置,可以控制模型输出的形态,是返回单个时间步的输出还是整个输出序列。
在模型改造中,将彩色图像预测作为目标,需要调整模型的最后层参数,如将`return_sequence`参数更改为`False`,同时将`Conv3D`层修改为`Conv2D`层以适应预测彩色图像的需求。此外,选择合适的损失函数(如MAE)、优化器(如Adam)以及设置Metrics(如MAE)以便在训练过程中监控模型性能。
通过上述步骤,不仅能够搭建出适合特定研究或项目需求的TensorFlow_gpu环境,还能够深入理解并灵活应用ConvLSTM模型。希望本文内容能够为读者提供有价值的指导,并期待在后续过程中持续改进和完善。
thrift源码解析——深度学习模型的RegisterBundles源码服务器端工程化落地方案
了解服务模型对于增大RPC服务端的并发处理能力至关重要。本文将详细介绍Thrift框架中的服务模型,帮助您在实际应用中做出明智选择。以下是支持Python的几个Thrift服务模型的概述: 1. TSimpleServer: 这个模型采用最简单的阻塞IO,实现方法简洁明了,便于理解。然而,它一次只能接收和处理一个socket连接,因此效率较低。 2. TNonblockingServer, TThreadPoolServer, TThreadedServer: 这三个模型在Python中利用多线程技术。它们的目的各不相同,但共同点是都旨在提高处理效率。具体而言,TThreadedServer创建单独的线程以处理每个客户端请求;TThreadPoolServer提前创建线程,从队列中获取客户端连接以进行处理;TNonblockingServer使用IO多路复用技术,将准备好的可读消息放入队列供业务线程处理。 3. TForkingServer, TProcessPoolServer: 这些模型旨在解决Python的GIL锁问题,特别是在Java中未找到等效模型的情况下。其中,TForkingServer通过创建子进程进行业务处理,但需要注意进程创建和销毁带来的开销。相比之下,TProcessPoolServer在启动时创建指定个数的进程,负责监听客户端请求并进行处理,这种模型在多线程环境下表现出色。 在实际应用中,性能测试表明,在不同服务模型下,处理效率存在显著差异。例如,在测试环境(核CPU)下,使用TProcessPoolServer模型时,个客户端同时发送请求时,处理时间为3秒多。此结果揭示了单个客户端连接服务器处理的elcascader源码串行性,以及不同模型在不同负载下的性能差异。 了解并选择合适的Thrift服务模型,对于构建高效的服务器端工程化落地方案至关重要。正确选择可以显著提高应用性能,确保在分布式服务、分布式计算等场景下达到最优效率。TFlite 源码分析(一) 转换与量化
TensorFlow Lite 是 Google 推出的用于设备端推断的开源深度学习框架,其主要目的是将 TensorFlow 模型部署到手机、嵌入式设备或物联网设备上。它由两部分构成:模型转换工具和模型推理引擎。
TFLite 的核心组成部分是转换(Converter)和解析(interpreter)。转换主要负责将模型转换成 TFLite 模型,并完成优化和量化的过程。解析则专注于高效执行推理,在端侧设备上进行计算。
转换部分,主要功能是通过 TFLiteConverter 接口实现。转换过程涉及确定输入数据类型,如是否为 float、int8 或 uint8。优化和转换过程主要通过 Toco 完成,包括导入模型、模型优化、转换以及输出模型。
在导入模型时,`ImportTensorFlowGraphDef` 函数负责确定输入输出节点,并检查所有算子是否支持,同时内联图的节点进行转换。量化过程则涉及计算网络中单层计算的量化公式,通常针对 UINT8(范围为 0-)或 INT8(范围为 -~)。量化功能主要通过 `CheckIsReadyForQuantization`、`Quantize` 等函数实现,确保输入输出节点的最大最小值存在。
输出模型时,cfmiapp源码根据指定的输出格式(如 TensorFlow 或 TFLite)进行。TFLite 输出主要分为数据保存和创建 TFLite 模型文件两部分。
量化过程分为选择量化参数和计算量化参数两部分。选择量化参数包括为输入和权重选择合适的量化参数,这些参数在 `MakeInitialDequantizeOperator` 中计算。计算参数则使用 `ChooseQuantizationParamsForArrayAndQuantizedDataType` 函数,该函数基于模板类模板实现。
TFLite 支持的量化操作包括 Post-training quantization 方法,实现相关功能的代码位于 `tools\optimize\quantize_model.cc`。
如何理解深度学习源码里经常出现的logits?
深度学习的秘钥:揭示logits的真面目
在深度学习的源码世界中,logits一词频繁出现,它似乎隐藏着某种魔力。那么,logits究竟是什么?它与我们熟知的概率计算有何关联?让我们一探究竟,揭示这个术语背后的深层含义。(p - 李航《统计学习方法》)
首先,logits是概率学中的一个重要概念,它并非简单的对数,而是事件发生与不发生比值的对数形式。想象一下,当某个事件发生的概率为p时,其logits可以这样表示:\[ \text{ logits} = \log\left(\frac{ p}{ 1-p}\right) \](p - TensorFlow官方文档)
当我们将logits与深度学习中的softmax层联系起来,你会发现它们之间的紧密关系。softmax层的作用是将一组未归一化的数值(即logits)转换为一个概率分布,确保所有概率值之和为1。在TensorFlow中,我们通常称这些未经过归一化的数值为logits,而不是它们的数学定义。
实际上,logits在深度学习模型中扮演着未加工的概率值角色,它们是概率分布的起点。softmax层通过对logits进行加和运算,将其转变为一个清晰、可解释的概率矩阵。理解这一点至关重要,因为logits的计算结果直接影响着模型的决策过程和最终预测。
总结来说,logits在深度学习中是未归一化的概率表示,它们是softmax函数运算的起点,是模型输出概率分布的基础。掌握这个概念,就能更好地解析和解读源码中的logits,从而深入理解模型的工作原理。(p - TensorFlow官方教程)
pytorch源码学习 nn.Module 提纲挈领
深入理解 PyTorch 的 nn.Module:核心概念与底层逻辑 掌握核心思想,探索底层逻辑,通过解析 PyTorch 的 nn.Module 来构建深度学习模型。此模块是 PyTorch 的基石,封装了一系列函数和操作,构成计算图,是构建神经网络的首选工具。 nn.Module 初始化(__init__) 在定义自定义模块时,__init__ 方法是关键。通过调用 super().setattr 方法,设置 nn.Module 的核心成员变量,如训练状态、参数、缓存等,这决定了模块的主要功能。这些设置包括:控制训练/测试状态
初始化参数集合
初始化缓存集合
设置非持久缓存集
注册前向和反向钩子
初始化子模块集合
理解这些设置对于高效初始化模块至关重要,避免了默认属性设置的冗余和潜在的性能影响。 训练与测试模式(train/val) nn.Module 通过 self.training 属性区分训练和测试模式,影响模块在不同状态下的行为。使用 model.train() 和 model.eval() 设置,可使模块在训练或测试时表现不同,如控制 Batch Normalization 和 Dropout 的行为。 梯度管理 requires_grad_ 和 zero_grad 函数管理梯度,用于训练和微调模型。requires_grad_ 控制参数是否参与梯度计算,zero_grad 清理梯度,释放内存。正确设置这些函数是训练模型的关键。 参数转换与转移 通过调用 nn.Module 提供的函数,如 CPU、type、CUDA 等,可以轻松转换模型参数和缓存到不同数据类型和设备上。这些函数通过 self._apply 实现,确保所有模块和子模块的参数和缓存得到统一处理。 属性增删改查 模块属性管理通过 add_module、register_parameter 和 register_buffer 等方法实现。这些方法不仅设置属性,还管理属性的生命周期和可见性。直接设置属性会触发 nn.Module 的 __setattr__ 方法。 常见属性访问 nn.Module 提供了方便的访问器,如 parameters、buffers、children 和 modules,用于遍历模块中的参数、缓存、子模块等。这些访问器通过迭代器简化了对模块属性的访问。 前向过程与钩子 nn.Module 中的前向过程与钩子管理了模块的执行顺序。forward_pre_hooks、forward_hooks 和 backward_hooks 用于在模块的前向和后向计算阶段触发特定操作,实现如内存管理、中间结果保存等高级功能。 模型加载与保存 模型的保存与加载通过 hook 机制实现,确保在不同版本间兼容。使用 state_dict() 和 load_state_dict() 函数实现模型状态的导出和导入,支持模块及其子模块参数的保存与恢复。 通过深入理解 nn.Module 的设计与实现,可以更高效地构建、优化和管理深度学习模型,实现从概念到应用的无缝过渡。Python项目演练:使用深度学习自动识别车牌号附源代码
本文核心在于演示如何利用Python的深度学习技术,通过OpenCV和Pytesseract实现车牌自动识别。OpenCV作为强大的计算机视觉库,其cv2.erode(), cv2.dilate(), cv2.morphologyEx()等功能在车牌识别中发挥关键作用。Pytesseract的Tesseract-OCR引擎则负责从处理过的图像中提取字符和数字信息。
为了进行车牌识别,项目中首先需要安装OpenCV和Pytesseract的pip包,然后通过定义一系列函数进行预处理,如检查轮廓的面积、宽高比和旋转,以排除非车牌区域。接下来,对识别结果进行预处理后,使用Pytesseract进行字符识别。项目还涉及GUI编程,如在gui.py中编写代码,以直观地展示和操作车牌识别过程。
自动车牌识别技术在安防、交通管理等领域具有广泛的应用,例如违停监测、停车场管理等。TSINGSEE青犀视频等企业也在视频监控领域融入AI技术,如EasyCVR视频融合云服务,集成了车牌识别、人脸识别等功能,提升了视频监控的智能化程度。
FasterTransformer Decoding 源码分析(三)-LayerNorm介绍
本文深入探讨FasterTransformer中LayerNormalization(层归一化)的源码实现与优化。作为深度学习中的关键技术,层归一化可确保网络中各层具有相似的分布,从而加速训练过程并改善模型性能。背景介绍部分详细解释了层归一化的工作原理,强调其在神经网络中的高效并行特性与广泛应用。文章从代码起点开始剖析,具体路径位于解码过程的核心部分。调用入口展示了传入参数,包括数据描述和关键参数gamma、beta、eps,简洁直观,符合公式定义。深入源码的解析揭示了优化点,特别是针对特定数据类型和维度,使用了定制化内核。此设计针对高效处理半精度数据样本,减少判断指令,实现加速运算,且对偶数维度数据进行调整以最大化Warp特性利用。接下来,内核实现的详细描述,强调了通过共享内存与block、warp级归约实现公式计算的高效性。这部分以清晰的代码结构和可视化说明,解释了块级别与Warp级归约在单个块处理多个数据点时的协同作用,以及如何通过巧妙编程优化数据处理效率。文章总结了FasterTransformer中LayerNormalization的整体优化策略,强调了在CUDA开发中基础技巧的应用,并指出与其他优化方案的比较。此外,文章还推荐了OneFlow的性能优化实践,为读者提供了一个深入探索与对比学习的资源。
深度学习目标检测系列:一文弄懂YOLO算法|附Python源码
深度学习目标检测系列:一文掌握YOLO算法 YOLO算法是计算机视觉领域的一种端到端目标检测方法,其独特之处在于其高效性和简易性。相较于RCNN系列,YOLO直接处理整个图像,预测每个位置的边界框和类别概率,速度极快,每秒可处理帧。以下是YOLO算法的主要特点和工作流程概述: 1. 训练过程:将标记数据传递给模型,通过CNN构建模型,并以3X3网格为例,每个单元格对应一个8维标签,表示网格中是否存在对象、对象类别以及边界框的相对坐标。 2. 边界框编码:YOLO预测的边界框是相对于网格单元的,通过计算对象中心与网格的相对坐标,以及边界框与网格尺寸的比例来表示。 3. 非极大值抑制:通过计算IoU来判断预测边界框的质量,大于阈值(如0.5)的框被认为是好的预测。非极大值抑制用于消除重复检测,确保每个对象只被检测一次。 4. Anchor Boxes:对于多对象网格,使用Anchor Boxes预先定义不同的边界框形状,以便于多对象检测。 5. 模型应用:训练时,输入是图像和标签,输出是每个网格的预测边界框。测试时,模型预测并应用非极大值抑制,最终输出对象的单个预测结果。 如果你想深入了解并实践YOLO算法,可以参考Andrew NG的GitHub代码,那里有Python实现的示例。通过实验和调整,你将体验到YOLO在目标检测任务中的强大功能。热点关注
- 福建:高效办成一件事 便民服务再升级
- 澤連斯基簽署法令允許外國人在烏克蘭國民警衛隊服役
- 藝人郭書瑤弟弟捲入「共諜組織案」 20萬元交保
- 下半年車市「催落去」? 休旅車大混戰9月引爆
- 阿根廷航空公司工會舉行罷工 超300架次航班取消
- 超親切!獲頒陽明交大名譽博士 蘇姿丰開場秀「2句中文」
- 索尼「經典30首」票選出爐! 蔡依林〈倒帶〉仍是全民最愛
- 速讀今日國際財經日誌(10/11)|天下雜誌
- 90%的校园欺凌本可预防,可是为何做不到?
- 西班牙飆44度「天堂變煉獄」野火肆虐 新疆火焰山「測到80度」
- 非洲酸枝木冒充红木销售 消费者维权获“退一赔三”
- 吉林公主岭:开展农资专项检查确保春耕生产
- 市场监管行风建设在行动|西安雁塔:“小小服务员”高效尽责解民忧
- 約旦河西岸發生槍擊事件3死8傷
- 速讀今日國際財經日誌(11/08)|天下雜誌
- 賺人民幣升值財三大訣竅|天下雜誌
- 观鸟达人、水质医生、污水厂老师傅,AI+环保,不止如此
- FTA卡位戰 台灣「卡」在哪?|天下雜誌
- 疫情防控零容忍——记山东威海环翠区市场监管局药品和医疗器械监管科科长王峰
- 午後雷陣雨來襲!1縣市發災防告警 14縣市大雨特報